Памятка «Синтаксический разбор предложения» | Методическая разработка по русскому языку (3 класс) по теме:
Члены предложения.
В предложении всегда есть главные члены. Они составляют основу предложения. В ней заключается главный смысл предложения.
Осенью журавли улетают на юг.
Художник рисует осенние листья.
Слова, которые не составляют основу предложения, являются второстепенными членами. Второстепенные члены поясняют главные члены предложения, уточняют их.
Осенью журавли улетают на юг.
Художник рисует осенние листья.
Подлежащее и сказуемое – главные члены предложения.
Подлежащее и сказуемое – это главные члены предложения. Они составляют грамматическую основу предложения.
- Подлежащее:
- Подлежащее – это главный член предложения, который обозначает, о ком или о чём говорится в предложении.
- Подлежащее отвечает на вопросы кто? или что?
- Подлежащее в предложении подчёркивается одной чертой.


кто? что?
Птицы летят. Жёлтый листочек упал с берёзки.
- Подлежащее выражено именем существительным или местоимением.
сущ. мест.
Спелое яблоко упало с яблони. Оно лежит на земле.
- Сказуемое:
- Сказуемое – это главный член предложения, который обозначает, что говорится о подлежащем.
- Сказуемое отвечает на вопросы что делает? что делал? что сделал? что делает? что сделаем? что делаешь? и другие.
- Сказуемое в предложении подчёркивается двумя чертами.
что делают? что сделал?
Птицы летят. Жёлтый листочек упал с берёзки.
________ _____
- Сказуемое в предложении выражено глаголом.
глаг. глаг.
Спелое яблоко упало с яблони. Оно лежит на земле.
_______ _________
- Встречаются случаи, когда сказуемое выражено именем существительным.
сущ. сущ.
Мой папа – инженер. Москва – столица России.
___________ __________
Что такое распространённое и нераспространённое предложения?
Предложения бывают распространённые и нераспространённые.
Нераспространённое предложение состоит только из главных членов.
сущ. глаг. глаг. сущ.
Дятел стучал. Пролетела чайка.
________ ______________
Распространённое предложение состоит их главных и второстепенных членов.
сущ. глаг. глаг. сущ.
сущ.
Дятел стучал на сосне. Над морем пролетела белокрылая чайка.
________ ______________
Разбор предложения.
Под зелёным кустом играют в прятки шаловливые лисятки.
- Найду действие предмета (глагол) – играют. Это сказуемое, подчеркну двумя чертами, выражено глаголом.
глаг.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
- Найду, кто? или что? выполнило это действие (кто? играют). Это лисятки.
Лисятки –это подлежащее, подчеркну одной чертой, выражено именем существительным.
глаг. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
- Значит в этом предложении говорится о лисятках.

(Кто?) лисятки. Лисятки (что делают?) играют.
Лисятки играют – это главные члены предложения (или грамматическая основа предложения).
- Обозначу части речи.
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
- Определю количество словосочетаний в предложении. Это предложение распространённое, кроме главных членов предложения здесь ещё 4 слова (под кустом, зелёным, в прятки, шаловливые). Значит нужно найти 4 словосочетания, внизу ставлю числа.
1)
2)
3)
4)
ЗАПОМНИ! Главные члены предложения НЕ МОГУТ быть словосочетанием.
Лисятки играют – это главные члены предложения, это нераспространённое предложение
- Сначала найду все словосочетания группы подлежащего (вопрос ставится от подлежащего).

- Лисятки (какие?) шаловливые;
ЗАПОМНИ! Первое словосочетание пишу с заглавной буквы, ставлю точку с запятой (;), остальные словосочетания пишу с маленькой буквы.
- Теперь найду словосочетания группы сказуемого (вопрос ставится от сказуемого).
- играют (где?) под кустом;
- играют (во что?) в прятки;
- Мне осталось найти ещё одно словосочетание (вопрос ставлю от второстепенных членов).
- под кустом (каким?) зелёным.
- Итог разбора предложения.
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
_________
- Лисятки (какие?) шаловливые;
- играют (где?) под кустом;
- играют (во что?) в прятки;
- под кустом (каким?) зелёным.

Как называются и подчёркиваются члены предложения
- Подлежащее __________ выражено существительным, местоимением (И.п. кто? что?)
- Сказуемое выражено глаголом (что делать? что сделал? что делает?
что будет делать? и другие)
- Определение ~~~~~~~~ выражено прилагательным (какой? какая? какое? какие? какой? какому? какого? и другие)
- Дополнение — — — — — — — — выражено существительным, местоимением (вопросы падежей:
Р.п. кого? чего? Д.п. кому? чему? В.п. кого? что? Т.п. кем? чем? П.п. о ком? о чём?)
- Обстоятельство -. — . — . — — выражено наречием, существительным, местоимением, числительным ( когда? сколько? как? где? почему? откуда? куда? и другие)
прил. сущ. глаг. сущ. прил. сущ.
Под зелёным кустом играют в прятки шаловливые лисятки.
~~~~~~~~ — . — . — . — _________ — — — — — — — — ~~~~~~~~~~
Синтаксический разбор слова
Часто пользователи ищут в сети синтаксический разбор какого-либо слова. По этому запросу обычно получают результаты по разбору предложений и словосочетаний. Но почему так происходит? Давайте в этом разберемся далее и приведем примеры такого разбора.
Все дело в том, что разобрать слово синтаксически нельзя. Можно сделать разбор только словосочетания или всего предложения. В школьной программе этой теме выделено довольно много времени для усвоения материала, а также большое количество практических уроков, чтобы ученики сами научились делать такой разбор. Но мы с вами сегодня опишем в общих чертах, как делать синтаксический анализ.
Содержание статьи:
- Как делать синтаксический разбор предложения
- Порядок разбора предложения по словам
- Анализ сложносочиненной конструкции
- Синтаксический разбор сложноподчиненных предложений с придаточными
- Анализ сложной конструкции с различными связными элементами
Как делать синтаксический разбор предложения
Если нужно выполнить синтаксический анализ словосочетания, сделайте следующее:
- Определите словосочетание. Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.
- Определите синтаксическое общее между словами.
- Выделите грамматическое значение для каждого.
 Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.
Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.Порядок разбора предложения по словам
Порядок действий будет следующим:
- Установите, каким выступает предложение по типу высказывания (вопросительное, побудительное, повествовательное).
- Далее нужно указать, из каких частей состоит предложение, его состав. Нужно сказать, что оно простое, односоставное/двусоставное, определить тип – безличное/личное. Предложение является нераспространенным или наоборот. Полное/неполное, если нет, то указать, каких именно частей в нем не достает.
- Если простое предложение осложнено обособленными, однородными членами предложения, отметьте это в синтаксическом разборе.
- Сделайте разбор простого предложения по членам, по ходу отмечая, к каким частям речи их отнести. Для этого соблюдайте порядок: первыми в предложении определите сказуемое и подлежащее, после них найдите второстепенные члены предложения.
- Предоставьте доводы о знаках препинания, если они имеются в предложении.
Синтаксический разбор. Порядок.
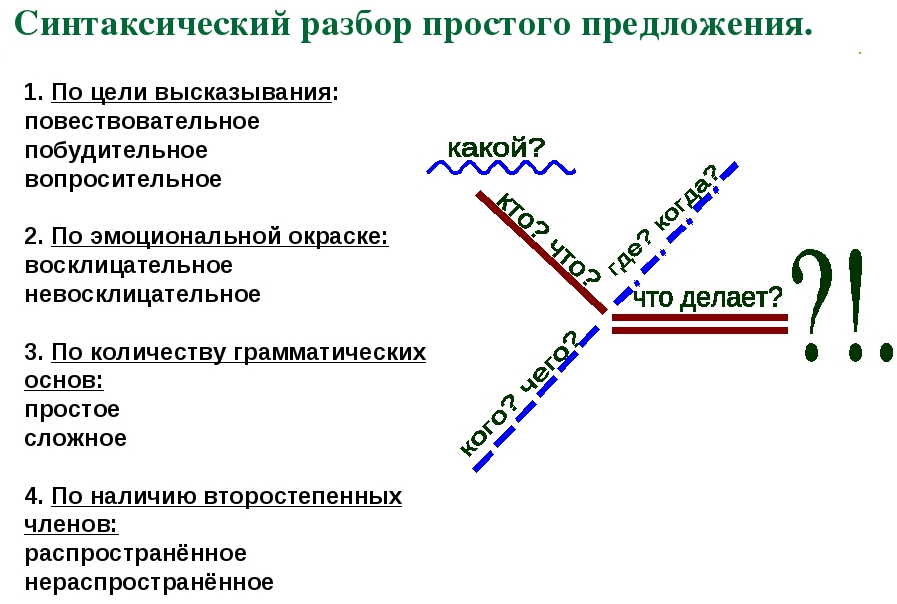
Для сказуемого нужно определить, каким оно является – составным или глагольным. Определите чем оно выступает. Если простое – укажите для него форму глагола, для составного глагольного – определить его состав, составное именное – чем выступает именная часть, какая связка применяется.
Если предложение имеет однородные члены предложения, укажите, чем выражены эти члены, и какими средствами они соединяются (союзы, интонация и союзы). В предложениях, которые имеют обособления, необходимо определить, чем выступает весь оборот. После этого нужно определить, чем выступает каждое слово в обороте, каким членом предложения является. Укажите, что предложение в своем составе имеет прямую речь. Определите слова говорящего, а также прямую речь.
Анализ сложносочиненной конструкции
Порядок действий:
- Аналогично, как и с простым предложением, назовите и определить тип высказывания.
- Определите грамматический фундамент каждого отдельного простого предложения. Прочитайте их по отдельности.
- Обозначите вид союзов, которыми связываются простые предложения в составе сложного (разделительные, соединительные, противительные). Определите, каким выступает сложное предложение (противопоставление, чередование событий, перечисление).
- Определите роль знаков препинания, объясните их расстановку.
- Затем нужно разобрать каждое предложение по отдельности как простое.

Далее рассмотрим пошаговый синтаксический разбор сложноподчиненного предложения (в составе одно придаточное):
- Отметить, каким сложноподчиненное предложение является (вопросительным, повествовательным).
- Разбить на простые предложения, найти грамматическую основу для каждого.
- Выделить, какое предложение из простых является главным.
- Определить по особенностям строения, чем присоединяется, к чему относится, чем выступает это сложноподчиненное предложение.
- Пояснить расстановку знаков препинания.
- Придаточное и главное разобрать подобно простым.
План синтаксического разбора предложения

Синтаксический разбор сложноподчиненных предложений с придаточными
Анализ состоит из следующих этапов:
- Определите цель высказывания сложноподчиненного предложения, отметьте это.
- Установите грамматическую роль каждого простого предложения.
- Определить среди простых придаточное и главное.
- Укажите признаки подчиненного предложения – параллельное, однородное, последовательное (возможно комбинированное).
- Объясните надобность каждого знака препинания.
Анализ сложной конструкции с различными связными элементами
Порядок действий:
- Установите цели высказывания.
- Укажите основу грамматики отдельного простого предложения.
- Указать, что предложение имеет разные виды связи.
- Выделите по смысловому признаку, каким образом соединены простые предложения.
- Объясните каждый знак препинания, его значение.

В статье мы рассмотрели, почему нельзя выполнить синтаксический разбор какого-либо слова, и как правильно выполнять анализ предложений.
Leave a comment
Синтаксический разбор — что это
Ученик, освоивший программу средней школы, должен уметь анализировать строение предложения на родном языке. Грамотный синтаксический разбор – это очень полезный навык, являющийся залогом знания пунктуации и способности быстро осваивать грамматический строй иностранного языка, а также составлять на нем предложения. Именно поэтому к нему следует относиться не как к некоему формальному требованию, а как к одному из ключевых умений.
По программе курса «Русский язык» синтаксический разбор предполагает прежде всего характеристику предложения по таким параметрам, как цель высказывания, эмоциональная составляющая и количество основ. И если с первыми двумя проблем, как правило, не возникает, то уже на этапе характеристики основ у ребенка могут возникнуть сложности. Далее требуется выделить и охарактеризовать второстепенные члены предложения, и здесь очень часто ученики допускают множество ошибок, влекущих за собой и пунктуационные ошибки, и плохие оценки за разбор. Образец синтаксического разбора в этих случаях помогает мало, необходимо обучение четкой последовательности действий и пониманию сути задания.
И если с первыми двумя проблем, как правило, не возникает, то уже на этапе характеристики основ у ребенка могут возникнуть сложности. Далее требуется выделить и охарактеризовать второстепенные члены предложения, и здесь очень часто ученики допускают множество ошибок, влекущих за собой и пунктуационные ошибки, и плохие оценки за разбор. Образец синтаксического разбора в этих случаях помогает мало, необходимо обучение четкой последовательности действий и пониманию сути задания.
Самые распространенные ошибки
Одной из самых распространенных ошибок является стремление выполнить синтаксический разбор предложения, анализируя слова по очереди – от первого к последнему. Как правило, если школьник так приступает к анализу предложения, то именно по этому пути он идет и при переводе иностранного текста на русский язык, что заведомо неверно. Это свидетельствует о том, что обучающийся не видит структуры предложения, не понимает его строения и связей между членами предложения, роли каждого из них в высказывании. Отсюда и ошибки при их идентификации и характеристиках.
Отсюда и ошибки при их идентификации и характеристиках.
Вторая ошибка – это пропуск одной из основ предложения. Можно найти подлежащее и сказуемое и остановиться в поиске основ, все остальные слова в предложении привязывая к найденной.
Третья распространенная ошибка заключается в неумении увидеть нестандартную грамматическую основу. Например, в предложении «Я так и не понял вчера, кто вы на самом деле», можно не найти подлежащее и сказуемое в придаточном предложении или вообще пропустить эту основу.
Наконец, еще одним затруднением, приводящим к сбою, часто становятся односоставные предложения, особенно в составе сложных. «Все мы заметили, как быстро сейчас вечереет». Если при анализе предложения «Вечереет» школьники нередко оказываются готовы увидеть сказуемое, то это же предложение, распространенное второстепенными членами и выступающее в роли придаточного, либо ставит в тупик, либо просто не замечается.
Стандартно в такого типа предложениях ошибочно находят подлежащее «сейчас» либо даже «быстро». Та же ошибка встречается, например, в предложении типа «Нам рассказали, как это место выглядело пять лет назад и как быстро здесь построили дом». Отсутствие запятой между основами из-за соподчинения придаточных провоцирует на ошибку и пропуск третьей – односоставной – основы.
Та же ошибка встречается, например, в предложении типа «Нам рассказали, как это место выглядело пять лет назад и как быстро здесь построили дом». Отсутствие запятой между основами из-за соподчинения придаточных провоцирует на ошибку и пропуск третьей – односоставной – основы.
Наконец, пятая большая группа ошибок заключается в нераспознавании осложненных предложений и приписывание, скажем, обособленным определениям и обстоятельствам, а также вводным словам роли грамматических основ либо в построении неверного пути распространения предложения.
Причины ошибок
Причина первой ошибки – невладение алгоритмом разбора, незнание того, как делать синтаксический разбор. Причина второй – отсутствие достаточного опыта, причина третьей, четвертой и пятой – недостаточная информированность и слабая база рассмотренных и проанализированных конструкций.
В этой статье мы остановимся на первой ошибке и сосредоточимся на сути синтаксического разбора, умении анализировать строение, механизм предложения.
Обучение и самообучение структурному подходу
Итак, синтаксический разбор – это прежде всего действия по четкому алгоритму и умение ясно видеть структуру предложения.
Начинать лучше не с анализа предложений, тем более сложных и запутанных – в этом случае обучающийся всегда будет действовать несколько вслепую и не будет уверен в правильности разбора. Одним из надежных и быстрых способов обучения умению анализировать структуру, чувствовать ее и уверенно составлять схему предложения является составление предложений с постепенным добавлением второстепенных членов и четким проговариванием того, что именно изменяется на каждом этапе, а также с вычерчиванием стрелок, показывающих зависимость слов, и поисков путей распространения предложения. Это задание подходит и при обучении ребенка, и при самообучении.
При таком постепенном «одевании» основы и ее распространении будет очевидно, как устроено предложение. Эта практика, к слову, обычно хорошо сказывается на умении не только переводить с иностранного языка, но и говорить на нем.
Простое предложение. Распространение подлежащего
«Щенок прибежал». Это грамматическая основа.
Распространяем подлежащее. Чей щенок? «Мой щенок прибежал». Какой щенок? «Мой рыжий щенок прибежал». Еще какой щенок? «Мой рыжий веселый щенок прибежал». Еще какой? «Мой рыжий веселый и лукавый щенок прибежал». Что еще можно сказать про то, какой он? «Мой рыжий веселый и лукавый щенок в кудряшках прибежал».
Сейчас мы распространили подлежащее пятью определениями.
Распространение сказуемого
Распространяем сказуемое. Прибежал откуда? С улицы. Куда? Домой. «Мой рыжий веселый и лукавый щенок в кудряшках прибежал домой с улицы».
Распространение второстепенных членов группы подлежащего
Распространяем второстепенные члены предложения группы подлежащего. Насколько веселый? Невероятно. В каких кудряшках? В крупных.
Разумеется, это простой пример. Чем неоднороднее и разнообразнее будут связи членов предложения, тем больший опыт приобретет обучающийся и тем выше будет процент вероятности, что далее он с легкостью «распутает» самые сложные на первый взгляд предложения, так как синтаксический разбор – это прежде всего умение «выпрямить», схематизировать любое высказывание, в независимости от порядка слов.
Распространение второстепенных членов группы сказуемого
Распространяем второстепенные члены предложения группы сказуемого. Как шлепая? Смешно. Как топая? Громко.
«Мой рыжий невероятно веселый и лукавый щенок в крупных кудряшках, смешно шлепая и громко топая, прибежал с улицы».
При самостоятельном составлении предложений по такому алгоритму очевидны связи слов, структура предложения, а следовательно, и его пунктуация.
Как можно увидеть, это задание чрезвычайно простое. Обычно оно выполняется обучающимися любых возрастов с большой охотой, и сложностей в построении схемы предложения не возникает, так как связи между словами очевидны, а между тем это основа обучения тому, как сделать синтаксический разбор грамотно и осознанно.
Инверсии и трансформации
После того как окончательное предложение разобрано, в нем идентифицированы все члены и установлены все связи, очень полезно трансформировать его, переставив местами слова, и снова сделать его анализ. «Смешно шлепая и громко топая, прибежал с улицы домой мой рыжий щенок в крупных кудряшках, невероятно веселый и лукавый». Анализ таких инверсий, а также упражение в трансформировании формируют привычку видеть в самых запутанных предложения их структуру и понимать, как устроены высказывания.
«Смешно шлепая и громко топая, прибежал с улицы домой мой рыжий щенок в крупных кудряшках, невероятно веселый и лукавый». Анализ таких инверсий, а также упражение в трансформировании формируют привычку видеть в самых запутанных предложения их структуру и понимать, как устроены высказывания.
Переход к сложным предложениям
Выше был рассмотрен путь обучения умению видеть структуру простого предложения. Однако синтаксический разбор – это анализ не только простых, но и сложных предложений. При этом важно понимать связи предложений друг с другом, отличать равноправные предложения и их сочинительную связь от иерархических отношений и подчинительной связи. Особенно часто возникают сложности в установлении характера и специфики подчинительной связи.
Разобраться в основах анализа сложного предложения поможет то же самое упражнение. Самый верный путь к пониманию особенностей структуры и работы механизма – это самостоятельное изготовление этого механизма. Это касается и предложений.
Продолжим наш пример, для простоты и краткости пока взяв за скобки второстепенные члены.
Щенок прибежал. Зачем? Поиграть. «Щенок прибежал поиграть». В предложении появилось обстоятельство цели. Попробуем его распространить. Поиграть с кем? С детьми. Подчеркнем цель словом «чтобы». «Щенок прибежал, чтобы поиграть с детьми». В высказывании все еще нет второго субъекта и предиката. «С детьми» — это дополнение. Сделаем так, чтобы дополнение, то есть, по смыслу, второй субъект, стало вторым подлежащим – вошло в основу нового придаточного предложения: «Щенок прибежал, чтобы дети с ним поиграли».
Такие транформации ценны тем, что показывают, какую роль играет придаточное предложение, как может разворачиваться и сворачиваться предикативность. Такая игра научит расставлять акценты, и любое предложение станет прозрачным по своей структуре, анализ которой, как уже говорилось, и составляет суть синтаксического разбора.
Школьная программа дисциплины «Русский язык» синтаксический разбор предложения в основном подает как некую теоретическую надстройку, однако это прежде всего развитие речевых навыков и умения осознанно подходить к построению предложения. Такой операционный подход, повторимся, очень хорошо сказывается и на изучении иностранных языков, и на пунктуационной грамотности, и на умении писать тексты на родном языке.
Такой операционный подход, повторимся, очень хорошо сказывается и на изучении иностранных языков, и на пунктуационной грамотности, и на умении писать тексты на родном языке.
Домашняя школа грамотности Екатерины Бунеевой — ЗАЧЕМ НУЖЕН РАЗБОР ПРЕДЛОЖЕНИЯ В школьном курсе русского языка довольно часто встречается задание разобрать предложение по членам. Для чего оно? Нужно ли тратить время на синтаксический разбор? Уверена, что да, более того: без анализа структуры предложения нельзя научить пунктуации. А пунктуационных ошибок в письменных работах учеников часто гораздо больше, чем орфографических. Известно, что знаки препинания несут в письменной речи особую функцию – смысловую. С их помощью пишущий выражает определённые смыслы и оттенки, а читающий эти смыслы и оттенки воспринимает и понимает. А поскольку все пишущие выступают в роли читающих и наоборот, знаки препинания едины для всех грамотных носителей русского языка. По словам лингвиста А. Б. Шапиро, всякое правило о знаках препинания есть как бы пункт договорённости между пишущим и читающим.
 Сейчас, когда пользователи сети Интернет постоянно общаются письменно, нужно передавать сообщения точно и сжато, и именно пунктуация помогает автору «уложить» наиболее понятно информацию в тексте. В общем, ребёнка надо научить ставить знаки препинания. Для этого нужны не только пунктуационные правила, но и анализ предложений – синтаксический разбор. Какая связь? 1. Первый шаг в разборе предложения – найти подлежащее и сказуемое. Это главное, базовое умение при обучении пунктуации. Если ребёнок не умеет этого делать, он не сможет ни правильно поставить знаки, ни проверить себя. 2. За ним сразу второй шаг: определяем, сколько в предложении пар главных членов. Если только одна – предложение простое, если две или больше – сложное. 3. Если предложение простое, смотрим, какие члены предложения относятся к подлежащему, а какие – к сказуемому, есть ли среди них однородные (если есть, составляем схему). Если предложение сложное, ищем границы частей, нумеруем их и сразу составляем схему предложения.
Сейчас, когда пользователи сети Интернет постоянно общаются письменно, нужно передавать сообщения точно и сжато, и именно пунктуация помогает автору «уложить» наиболее понятно информацию в тексте. В общем, ребёнка надо научить ставить знаки препинания. Для этого нужны не только пунктуационные правила, но и анализ предложений – синтаксический разбор. Какая связь? 1. Первый шаг в разборе предложения – найти подлежащее и сказуемое. Это главное, базовое умение при обучении пунктуации. Если ребёнок не умеет этого делать, он не сможет ни правильно поставить знаки, ни проверить себя. 2. За ним сразу второй шаг: определяем, сколько в предложении пар главных членов. Если только одна – предложение простое, если две или больше – сложное. 3. Если предложение простое, смотрим, какие члены предложения относятся к подлежащему, а какие – к сказуемому, есть ли среди них однородные (если есть, составляем схему). Если предложение сложное, ищем границы частей, нумеруем их и сразу составляем схему предложения. Схема помогает зрительно представить структуру предложения, увидеть границы частей или смысловых отрезков и осознанно выбрать знак препинания. Именно так ребёнок должен действовать, когда проверяет написанное: в каждом предложении найти и подчеркнуть главные члены, установить количество частей, найти границы частей или смысловых отрезков и проверить, тот ли знак стоит. То есть по сути самопроверка – это свёрнутый синтаксический разбор. И ещё одно. При обучении пунктуации очень важно объяснить, что по своей роли в письменной речи все знаки препинания делятся на три группы: знаки завершения, разделительные и выделительные. Эти названия «говорящие». Знаки ЗАВЕРШЕНИЯ (точка, восклицательный знак, вопросительный знак, многоточие) ставятся в конце предложений, завершают их. РАЗДЕЛИТЕЛЬНЫЕ знаки (запятая, точка с запятой, двоеточие, тире) – отделяют друг от друга смысловые отрезки внутри предложения (однородные члены) и части сложного предложения, они ставятся на границе этих смысловых отрезков, разделяют их.
Схема помогает зрительно представить структуру предложения, увидеть границы частей или смысловых отрезков и осознанно выбрать знак препинания. Именно так ребёнок должен действовать, когда проверяет написанное: в каждом предложении найти и подчеркнуть главные члены, установить количество частей, найти границы частей или смысловых отрезков и проверить, тот ли знак стоит. То есть по сути самопроверка – это свёрнутый синтаксический разбор. И ещё одно. При обучении пунктуации очень важно объяснить, что по своей роли в письменной речи все знаки препинания делятся на три группы: знаки завершения, разделительные и выделительные. Эти названия «говорящие». Знаки ЗАВЕРШЕНИЯ (точка, восклицательный знак, вопросительный знак, многоточие) ставятся в конце предложений, завершают их. РАЗДЕЛИТЕЛЬНЫЕ знаки (запятая, точка с запятой, двоеточие, тире) – отделяют друг от друга смысловые отрезки внутри предложения (однородные члены) и части сложного предложения, они ставятся на границе этих смысловых отрезков, разделяют их. Эти знаки одиночные. ВЫДЕЛИТЕЛЬНЫЕ знаки препинания (они всегда двойные: две запятые, два тире, скобки, кавычки) выделяют один смысловой отрезок внутри другого или внутри предложения. Выделяются с двух сторон, если стоят в середине предложения, причастные и деепричастные обороты, одиночные деепричастия, обращения, вводные слова и предложения и др. Кстати, если знать это, вы ни за что не поставите только одну запятую при причастном обороте: его надо ВЫДЕЛИТЬ запятыми, значит, их должно быть две, с двух сторон: в начале и в конце. Все эти смысловые отрезки мы находим, анализируя предложения в процессе синтаксического разбора. Возможно, вы удивитесь, но если ещё в начальных классах регулярно тренироваться в синтаксическом разборе разных предложений, если рассказать детям о функции и о трёх группах знаков препинания и каждый раз, изучая новое правило, делать акцент на том, к какой группе относится знак и что именно он разделяет или выделяет, грамотность вырастает в разы. Дети начинают ставить знаки препинания осмысленно и проверять написанное.
Эти знаки одиночные. ВЫДЕЛИТЕЛЬНЫЕ знаки препинания (они всегда двойные: две запятые, два тире, скобки, кавычки) выделяют один смысловой отрезок внутри другого или внутри предложения. Выделяются с двух сторон, если стоят в середине предложения, причастные и деепричастные обороты, одиночные деепричастия, обращения, вводные слова и предложения и др. Кстати, если знать это, вы ни за что не поставите только одну запятую при причастном обороте: его надо ВЫДЕЛИТЬ запятыми, значит, их должно быть две, с двух сторон: в начале и в конце. Все эти смысловые отрезки мы находим, анализируя предложения в процессе синтаксического разбора. Возможно, вы удивитесь, но если ещё в начальных классах регулярно тренироваться в синтаксическом разборе разных предложений, если рассказать детям о функции и о трёх группах знаков препинания и каждый раз, изучая новое правило, делать акцент на том, к какой группе относится знак и что именно он разделяет или выделяет, грамотность вырастает в разы. Дети начинают ставить знаки препинания осмысленно и проверять написанное. Это многократно лично проверено и на школьных уроках, и в репетиторский практике, и в онлайн-обучении. Если вы хотели бы регулярно получать рассылку с моими рекомендациями, как заниматься с ребёнком русским языком, развивать речь, как учить его читать и понимать текст, писать без ошибок, отправьте по адресу [email protected] письмо: «Хочу получать рассылку». Автор: Екатерина Бунеева
Это многократно лично проверено и на школьных уроках, и в репетиторский практике, и в онлайн-обучении. Если вы хотели бы регулярно получать рассылку с моими рекомендациями, как заниматься с ребёнком русским языком, развивать речь, как учить его читать и понимать текст, писать без ошибок, отправьте по адресу [email protected] письмо: «Хочу получать рассылку». Автор: Екатерина Бунеева
Домашняя школа грамотности Екатерины Бунеевой на Facebook. Если вам интересны новости Домашняя школа грамотности Екатерины Бунеевой, регистрируйтесь на Facebook сегодня!
✅ Что делать разбор предложения. Как делать синтаксический разбор предложения
Синтаксический разбор предложения
Содержание
- Единицы синтаксиса
- Зачем нужен синтаксический разбор предложения
- Члены предложения
- Характеристика предложения
- Осложнённое предложение
- Если предложение сложное
- Пример синтаксического разбора предложения
- Что мы узнали?
Бонус
Единицы синтаксиса
Синтаксис изучает связь слов внутри словосочетаний или предложений. Таким образом, единицами синтаксиса являются словосочетания и предложения – простые или сложные. В этой статье мы будем говорить о том, как сделать синтаксический разбор предложения, а не словосочетания, хотя нередко в школе просят сделать и его.
Таким образом, единицами синтаксиса являются словосочетания и предложения – простые или сложные. В этой статье мы будем говорить о том, как сделать синтаксический разбор предложения, а не словосочетания, хотя нередко в школе просят сделать и его.
Зачем нужен синтаксический разбор предложения
Синтаксический разбор предложения предполагает подробное рассмотрение его структуры. Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Члены предложения
Среди членов предложения всегда сначала выделяют главные: подлежащее и сказуемое. Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Грамматическая основа может состоять как из двух главных членов, так и включать в себя только один из них: или только подлежащее, или только сказуемое. Во втором случае мы говорим, что предложение односоставное. Если же присутствуют оба главных члена – двусоставное.
Если, кроме грамматической основы, слов в предложении нет, оно называется нераспространённым. В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.
если в предложении есть слова, которые членами предложения не являются (например, обращение), оно все равно считается нераспространенным.
Выполняя разбор, необходимо называть и часть речи, которой выражен тот или иной член предложения. Этот навык ребята отрабатывают, изучая в 5 классе русский язык.
Этот навык ребята отрабатывают, изучая в 5 классе русский язык.
Характеристика предложения
Чтобы дать характеристику предложению, надо указать надо его описать
- по цели высказывания;
- по интонации;
- по количеству грамматических основ и так далее.
Ниже мы предлагаем план характеристики предложения.
По цели высказывания: повествовательное, вопросительное, побудительное.
По интонации: восклицательное или невосклицательное.
Восклицательными могут быть любые по цели высказывания предложения, а не только побудительные.
По количеству грамматических основ: простое или сложное.
Если предложение простое, движемся дальше по плану; если сложное, путь отсюда придется пройти несколько раз: столько, сколько частей в сложном.
По количеству главных членов в грамматической основе: односоставное или двусоставное.
Если предложение односоставное, надо определить его вид: назывное, определённо-личное, неопределённо-личное, безличное.
По наличию второстепенных членов: распространённое или нераспространённое.
Если предложение чем-то осложнено, то это также надо указать. Это план синтаксического разбора предложения; лучше его придерживаться.
Осложнённое предложение
Предложение может быть осложнено обращением, вводными и вставными конструкциями, однородными членами, обособленными членами, прямой речью. Если какой-то из этих видов осложнений присутствует, то надо указать, что предложение осложненное, и написать чем.
Если предложение сложное
Если необходимо сделать разбор сложного предложения, надо сначала указать, что оно сложное, и определить его тип: союзное или бессоюзное, а если союзное, то еще и сложносочиненное или сложноподчиненное. Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
В таблице приведены второстепенные члены и их вопросы.
Второстепенные члены предложения
Синтаксический и морфологический разбор предложения или текста онлайн
Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Справочная информация
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое – это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое – это глагол, т.е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение – второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта – было бы скучно, уж поверьте. Итак, обстоятельство – это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?». А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной – важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» — как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая – придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой – как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т.е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется – оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола – действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость. Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны. Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Синтаксический разбор предложения
Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:
5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое).
6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое.
7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено.
8. Подчеркнуть все члены предложения, указать части речи.
9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть.
5. Указать, какая связь в предложении: союзная или бессоюзная.
6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы.
7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП).
8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца.
9. Подчеркнуть все члены предложения, указать части речи.
10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть.
Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.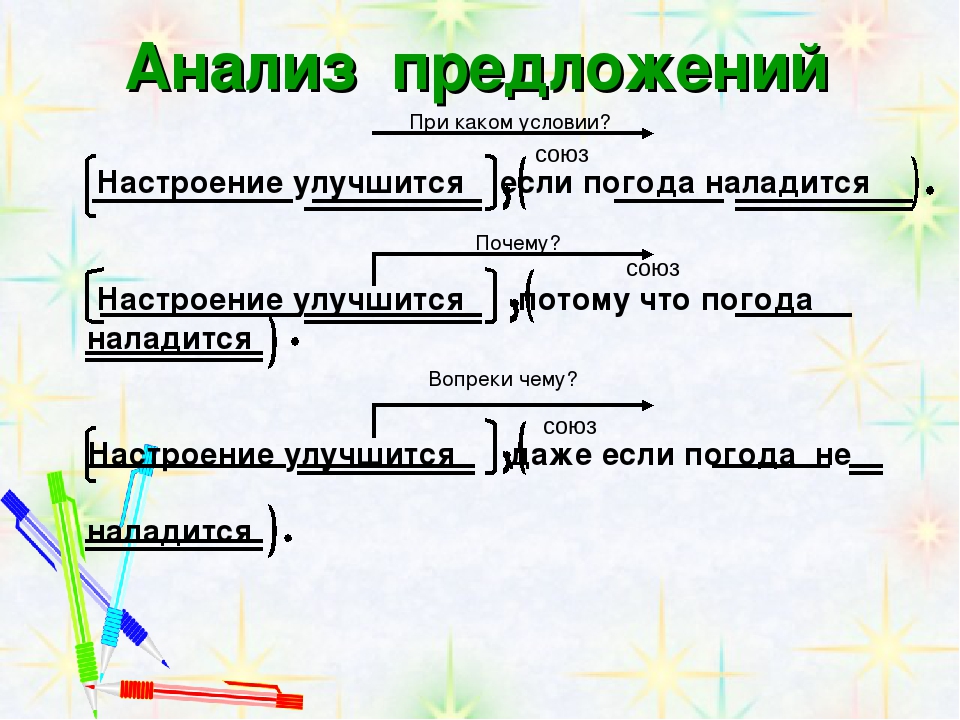
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложения
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Двусоставное оно, либо односоставное.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
 Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.Сказуемое
- Отмечаем, чем является сказуемое — простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое — какой формой глагола;
- составное глагольное — из чего оно состоит;
- составное именное — какая употреблена связка, чем выражается именная часть.

В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Синтаксический разбор предложения — как его сделать?
Каждый из нас учился в школе. Наверное, ещё свежи в памяти те воспоминания о тетрадках, ручках, прописях, азбуках и других важных и нужных вещей в школе. А также правила, правила и ещё раз правила. Правил действительно было много — сложение, вычитание, правила русского языка, правила грамматики. Когда-то это всё было в новизну, и яростно впитывалось пытливым детским умом, чтобы затем использоваться в тестах и контрольных.
Через определённое время многое просто забывается. Вряд ли взрослый человек сможет сейчас по требованию быстро сделать морфологический разбор слова. Ну, конечно, если он сам не является учителем русского языка и литературы. Русский язык очень красив и могуч, он яркий и разнообразный. Но в то же время грамматика русского языка довольно сложна, особенно если в какой-то момент все правила, которые когда-то были выучены за партой в школе, просто испарились из памяти.
Как и морфологический разбор слова, не каждый сможет с ходу сделать синтаксический разбор предложения. Статья позволит ответить на следующие вопросы: «Как делать синтаксический разбор предложения?», «Как делать синтаксический разбор?», «Как осуществить синтаксический анализ предложения?». В данной статье речь пойдёт именно об этом. Читатель сможет освежить свои знания, вспомнить уже забытые правила синтаксического разбора, а затем применить их на практике, если в этом появится необходимость.
Полная общая схема синтаксического разбора предложения
Существует общая схема для осуществления синтаксического разбора предложений. Она может варьироваться в зависимости от того, какую конструкцию требуется разобрать, но, в принципе, основная база остаётся без изменений.
Итак, для синтаксического разбора нужно следовать следующим пунктам упомянутой выше схемы:
- Для начала следует указать цель предложения. Предложение может быть повествовательным, вопросительным, или же побудительным. Определить это совсем легко — обычное образование считается повествовательным, так как сообщает определённую информацию, вопросительное имеет в конце вопросительный знак, а побудительное — соответственно, восклицательный, так как побуждает к действию.
- Далее определяется интонация разбираемого высказывание. По этому критерию предложения делятся на восклицательные и невосклицательные.
- При разборе обязательно нужно указать, простое предложение или сложное, состоящее из нескольких простых.
- У сложных предложений потребуется указать тип конструкции. Тут может быть два варианта — простая конструкция (однотипная) или сложная (подразумевается наличие разных видов связи между несколькими простыми конструкциями в сложном).
- Если сочетание сложное, то понадобится указать тип связи нескольких простых в нём. Связь может быть союзной и бессоюзной.
- Союзные конструкции могут быть сложноподчинёнными и сложносочинёнными.
- Если конструкция является сложноподчинённой, то придётся указать также и тип придаточного: изъяснительное, определительное, присоединительное и обстоятельственное.
- В случае наличия последнего, то потребуется обозначить тип такого придаточного предложения:
- образа действия;
- времени;
- места;
- меры и степени;
- условия;
- уступки;
- сравнения;
- цели;
- причины;
- следствия.
- В том случае, если предложения является сложным, при его разборе потребуется обязательно выполнить описание связи его частей. Все части понадобится пронумеровать и при этом указать все виду связи (союзная и бессоюзная, сочинительная и подчинительная), также если есть необходимость, нужно сделать членение на уровни.
- Затем, указывая номер простого предложения, сделать характеристику каждого из них.
- При осуществлении анализа простых конструкций, обязательно нужно указать, односоставное предложение или двусоставное. Определить это можно, просто обратив внимание на то, есть ли там и подлежащее, и сказуемое.
- Если предложение односоставное, то следует определить его тип: назывное, обобщённо-личное, безличное, определённо-личное или неопределённо-личное.
- Затем понадобится обозначить тип имеющегося в конструкции сказуемого. Сказуемое может быть следующего типа: простое глагольное сказуемое (ПГС), составное глагольное сказуемое (СГС), составное именное сказуемое (СИС).
- На данном этапе потребуется обозначить распространённое образование или нераспространённое. Сделать это очень легко. Если в нём есть второстепенные члены, то оно распространённое, если же они отсутствуют, то оно, соответственно, нераспространённое.
- Потом обязательно указывается осложнено ли предложение, и чем.
- Напоследок, требуется указать, полная ли конструкция или неполная, то есть присутствуют ли все второстепенные члены, или же они опущены.

 Все части понадобится пронумеровать и при этом указать все виду связи (союзная и бессоюзная, сочинительная и подчинительная), также если есть необходимость, нужно сделать членение на уровни.
Все части понадобится пронумеровать и при этом указать все виду связи (союзная и бессоюзная, сочинительная и подчинительная), также если есть необходимость, нужно сделать членение на уровни.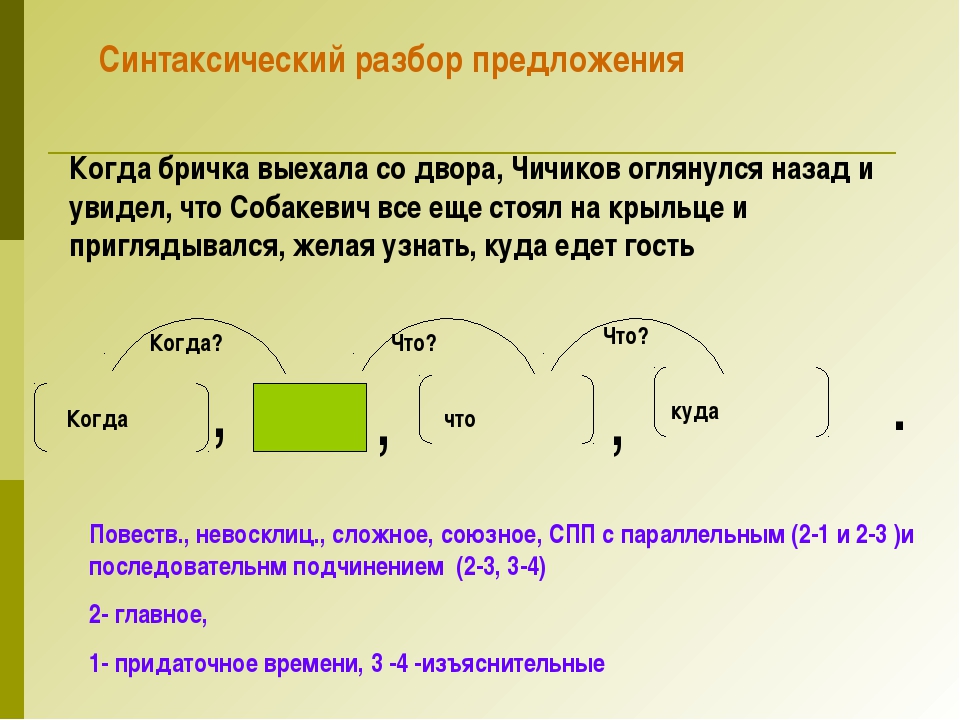 Если в нём есть второстепенные члены, то оно распространённое, если же они отсутствуют, то оно, соответственно, нераспространённое.
Если в нём есть второстепенные члены, то оно распространённое, если же они отсутствуют, то оно, соответственно, нераспространённое.Типы придаточных предложений
Большую трудность зачастую вызывает определение типа придаточных частей в сложноподчинённых конструкциях. Чтобы в этом разобраться, далее будет представлена информация, ознакомление с которой позволит легче осуществить синтаксический разбор, если оно является сложноподчинённым.
Основные моменты
Итак, что следует уяснить при разборе:
- Придаточные предложения изъяснительного типа отвечают на вопросы косвенных падежей. В качестве связующих средств выступают союзные слова или просто союзы.
- К существительному относятся придаточные конструкции определительного типа. Чаще всего присоединяются с помощью союзных слов, но бывают случаи, когда используются и союзы. Отвечают на вопросы «какой?, «чей?».
- Возможно, больше всего проблем возникает при определении придаточного обстоятельственного предложения (ПО). Они различаются в зависимости от разряда.
Разряд придаточного обстоятельственного предложения
Следует помнить о следующих разрядах:
- ПО времени отвечают на следующие вопросы: «когда?», «до каких пор?», «как долго?», «на сколько времени?». Обычно для присоединения используются союзы «когда», «только», «как только», «пока» и другие.
- ПО цели отвечают на вопросы «зачем?», «с какой целью?».
- ПО следствия — союз «так что».
- ПО места — вопросы «куда?», «где?», «откуда?».
- ПО образа действия — «как?», в главную часть конструкции можно вставить слова «так», «таким образом».
- ПО причины раскрывают вопрос «почему?».
- ПО уступки — вопросы «несмотря на что?», «вопреки чему?». Используются союзы «даром», «пускай», «несмотря на то что».
- Сравнительные придаточные обстоятельственные предложения отвечают на следующие вопросы: «подобно чему?», «как что?», при этом обычно используются союзы «словно», «как», «будто», «точно».
Видео
Понять, что такое синтаксический разбор предложения и как его правильно выполнить, вам может этот видеоурок.
Синтаксический разбор предложения.
Синтаксический разбор предложения в русском языке осуществляется по схеме ответов на следующие вопросы:
1) Каково данное предложение по цели высказывания? (Повествовательное, побудительное или вопросительное).
2) Какова эмоциональная окраска предложения ? (Восклицательное или невосклицательное).
3) Сколько грамматических основ есть у данного предложения? (Простое – одна основа, сложное – две и более).
Далее, если предложение простое:
4) Односоставное предложение или двусоставное? (Если имеется и подлежащее, и сказуемое – то двусоставное, если только один главные член – то односоставное).
5) Распространенное предложение или нераспространенное? (Есть ли второстепенные члены предложения?).
6) Осложненное предложение или неосложненное?(Имеются ли однородные члены, вводное слово, причастный/деепричастный оборот, обращение?)
7) Какими частями речи выражены все члены предложения? Подчеркните все члены предложения.
8) Составьте схему предложения, обозначив грамматическую основу и осложнение, если таковое присутствует.
Если предложение сложное, то следуем следующей схеме.
4) Какая связь имеется в сложном предложении: союзная или бессоюзная?
5) Какой именно способ связи используется в предложении: подчинительная, сочинительная или интонация?
6) На основе ответа на предыдущий пункт, обозначить, к какому типу сложного предложения относится данное: сложносочиненное, сложноподчиненное или бессоюзное?
7) Следуя инструкции разбора простого предложение, разобрать каждую из частей сложного предложения.
Пример синтаксического разбора простого предложения.
В букете были розы и лилии.
Устный разбор простого предложения.
Предложение повествовательное, невосклицательное, простое, двусоставное; грамматическая основа: розы и лилии были; распространенное, осложнено однородными подлежащими.
Письменный разбор простого предложения.
Повест., невоскл., прост., двусост., г/о розы и лилии были, распростр., осложн. однород. подл.
Пример разбора сложного предложения.
В букете были розы и лилии, но ей больше нравились тюльпаны.
Устный разбор сложного предложения.
Предложение повествовательное, невосклицательное, сложное, связь союзная, предложения связываются сочинительным союзом «но», сложносочиненное предложение. Первое предложение двусоставное, грамматическая основа розы и лилии были; распространенное, осложнено однородными подлежащими. Второе предложение двусоставное, грамматическая основа: тюльпаны нравились, распространенное, не осложнено.
Письменный разбор сложного предложения.
Повеств., невоскл., сложн., сложносоч., с союзом но. 1-е ПП: двусост., г/о розы и лилии были, распр., осложн. однор. подл. 2-е ПП: двусост., г/о: тюльпаны нравились, распростр., не осложн.
СИНТАКСИЧЕСКИЙ РАЗБОР ПО ЧЛЕНАМ ПРЕДЛОЖЕНИЯ |
Обстоятельственные слова never, never once, in vain, no more, little и др. могут помещаться в начале предложения. В таком случае происходит расщепление смыслового глагола путем введения служебного глагола do.
Примеры:
Never did the snowcapped mountains look so beautiful as on that particular morning.
In vain did the boy implore his cruel master to stop beating him. (From an English fairy-tale.)
Little did he remember after his illness. (Он мало что помнил после своей болезни.)
Примечаниe. Вышеприведенная структура предложений с обстоятельственным словом never является принадлежностью высокого стиля: в языке повседневной жизни усиление значении never производится другими способами.
Например: But you never have been refused yet by anybody, have you?
Возможно помещение обстоятельства образа действия, выраженного наречием, в начале предложения часто с наречием so.
Для того чтобы придать повествованию живость, послелоги, которые указывают на направление и образуют вместе с глаголами, обозначающими движение, составные непереходные глаголы, отрываются от глаголов и помещаются в начале предложения. При этом наблюдается обратный порядок слов.
Примеры:
Away ran the merry children.
Down went the window with a crash.
Up went all the hands.
Прямой порядок слов остается в том случае, если подлежащее выражено местоимением.
Примеры: Away they ran. Down it went. Out he rushed.
Предложения с формальным подлежащим
it
Второй способ выделения того или иного члена предложения заключается в том, что этот член предложения превращается в именную часть сказуемого главного предложения при формальном подлежащем it. К именной части сказуемого (т. е. предикативному члену) примыкает предложение, которое вводится словами that, who или бессоюзно. Тем самым простое предложение превращается в сложное предложение особого типа.
Этим способом может выделяться подлежащее, дополнение и обстоятельства.
Например, предложение: The famous Russian explorer Miklukho-Maclay spent more than ten years on New Guinea – может иметь следующие варианты:
It was the famous Russian explorer Miklukho-Maclay who spent more than ten years on New Guinea (выделяется подлежащее).
It was on New Guinea that Miklukho-Maclay spent more than ten years (выделяется обстоятельство места).
It was more than ten years that Miklukho- Maclay spent on New Guinea (выделяется обстоятельство времени).
Другие примеры:
It was here that it happened.
It was on this condition that I went.
It is you that I am talking to.
Примечание. В таких предложениях местоимение it обычно не переводится.
НЕПОЛНЫЙ СИНТАКСИЧЕСКИЙ АНАЛИЗ ТЕКСТА В ИНФОРМАЦИОННО-ПОИСКОВЫХ СИСТЕМАХ
НЕПОЛНЫЙ СИНТАКСИЧЕСКИЙ АНАЛИЗ ТЕКСТА В
ИНФОРМАЦИОННО-ПОИСКОВЫХ СИСТЕМАХ
А. Е. Ермаков
ООО “Гарант-Парк-Интернет”
Ключевые слова: синтаксический разбор, разрешение омонимии, выделение именных групп, статистический анализ текста, информационный портрет текста.
Доклад посвящен опыту разработки неполного синтаксического анализатора русского языка и его внедрению в прикладные системы анализа полнотекстовых документов в компании “Гарант-Парк-Интернет”. Синтаксический разбор без учета глагольного управления на основе бесконтекстной грамматики позволяет выделять именные группы и разрешать морфологическую омонимию, не выходя за рамки допустимых ограничений на вычислительные ресурсы систем, работающих с большими массивами документов. Экспериментально показано, что использование такого анализатора на этапе предварительной обработки документа существенно повышает точность работы алгоритмов статистического анализа текста в прикладных системах.
1. Введение
Задаче компьютерного анализа текста на естественном языке посвящено множество теоретических и практических работ. Доступные сегодня вычислительные мощности позволили применить широкий класс математических методов анализа неструктурированных данных для обработки больших массивов документов, эффективно решая задачи поиска информации, классификации, кластерного анализа, выявления скрытых закономерностей и другие. Не последнее место в этом ряду занимают и наши собственные разработки в компании “Гарант-Парк-Интернет”, представленные на сайтеhttp://research.metric.ru.
К сожалению, внедрение математических методов в обработку текста проходит на фоне отсталости собственно лингвистической составляющей алгоритмов, что не позволяет достичь высокого качества работы прикладных систем. Ставший устойчивым уклон в область статистических методов анализа привел к тому, что компьютерная лингвистика на время оказалась оставлена в стороне. Господствующего мнения, что лингвистические алгоритмы являются ненадежными, слабо масштабируемыми и чересчур медленными для решения реальных задач, до недавнего времени придерживались и автор в более ранних публикациях на эту тему [1,2].
Исследования, проведенные нами в последний год, заставили изменить сложившуюся точку зрения на место алгоритмов синтаксического разбора в структуре статистических анализаторов текста. Не претендуя на конкуренцию с разработчиками систем машинного перевода и оставаясь в рамках решения собственных задач, относимых скорее к разряду аналитических, мы начали успешно развивать синтаксическую обработку для внедрения в собственные продукты.
2. Синтаксический разбор в задачах автоматического анализа текста
Сложность реализации высокоточного анализатора связана с наличием тесной связи между синтаксисом и семантикой, присутствием в текстах русского языка большого количества синтаксически омонимичных конструкций, не допускающих однозначной интерпретации без привлечения знаний о семантической сочетаемости слов. Такова, например, проблема управления глагола предложно-падежными конструкциями. В синтаксически эквивалентных фразах “человек стрелял из ружья” и “человек стрелял из окна”, объект “ружье” представляет аргумент предиката “стрелять” в роли косвенного дополнения, а объект “окно” – обстоятельство места, которое является дополнительной характеристикой всей ситуации в целом.
Модель языка, призванная объединить синтаксическую и семантическую составляющие, известна под названием толково-комбинаторного словаря и призвана описать ограничения на сочетаемость лексических единиц в определенных синтаксических ролях, например, в форме известного аппарата лексических функций [6].
Однако, помимо колоссального объема необходимого ручного труда, разработку подобного словаря усложняет отсутствие достаточно полной и устоявшейся системы классификации типов синтагматических отношений (например, базиса лексических функций), а также парадигматической классификации лексики (тезауруса). Так, если описание синтагматики обязано декларировать, что аргумент предиката “стрелять”, представляющий орудие действия, должен относиться к классу “оружие”, то описание парадигматики призвано установить все имена, относимые к этому классу – “ружье”, “рогатка” и др.
Указанные проблемы привели к установившемуся мнению о нецелесообразности введения модуля синтаксического разбора в системы автоматического анализа текста. Однако оказалось, что, несмотря на ограниченную точность синтаксических анализаторов, их использование способно заметно повысить качество таких систем в случае комбинирования с известными статистическими методами [1,2], не выходя за рамки стандартных ограничений на вычислительные ресурсы.
Дело в том, что отдельные ошибки синтаксического анализатора поглощаются в дальнейшем при фильтрации статистическим анализатором, поскольку общее число “нормальных” языковых конструкций в тексте существенно превышает число “нестандартных”. Некоторые ошибки могут оказаться заметными при анализе текстов небольшого объема, однако стоит учесть, что статистическому анализу такие тексты вообще не поддаются.
Экспериментально проверенным фактом является также то, что для решения многих задач с приемлемым качеством не требуется полный синтаксический разбор, к которому призваны стремиться автоматические переводчики. Полный анализ всех возможных синтаксических связей, присутствующих во фразе, даже сейчас является непомерно долгим для нашего класса задач.
Основные задачи, решаемые сегодня системами анализа текста, следующие: формирование информационного портрета текста в терминах ключевых понятий, выявление смысловых связей между понятиями, автоматическое реферирование. Прикладные функции интеллектуальных систем, которые могут быть реализованы на основе этих результатов, были описаны в работах [3,4,5]. Важнейшей сопутствующей проблемой, решаемой исключительно средствами синтаксического анализа, является разрешение омонимии в тех случаях, когда грамматические формы различных слов совпадают (например, форма “стали” для существительного “сталь” и глагола “стать”).
3. Синтаксический разбор и разрешение омонимии
Целью синтаксического разбора является построение дерева синтаксических зависимостей между словами во фразе. В случае удачного разбора предложение сворачивается в полносвязное дерево с единственной корневой вершиной.
Поскольку одна словоформа может соответствовать нескольким грамматическим формам слова, в том числе формам различных слов, в ходе анализа необходимо производить свертку предложения для всех возможных вариантов грамматических форм. Те грамматические формы, которые обеспечивают максимальную свертку дерева (минимальное число висячих вершин), следует считать наиболее достоверными.
Как показала практика, для снятия большей части омонимии (около 90%) не требуется полный синтаксический анализ, обеспечивающий полную свертку дерева. Достаточным оказывается включение правил согласования слов в именных и глагольных группах, свертки однородных членов, согласования подлежащего и сказуемого, предложно-падежного управления и нескольких прочих – всего в пределах 20-ти правил, описываемых бесконтекстной грамматикой. Подробно ознакомиться со способами формального описания языка можно, например, в работе [7].
Порядок применения правил управляется алгоритмом разбора, который на каждом шаге проверяет возможность применения очередного правила к очередному фрагменту фразы (паре-тройке слов, знаков препинания и т.п.) и, если удается, сворачивает фрагмент. Свертка фрагмента обычно заключается в его замене одним главным словом – удалением подчиненных слов, после чего разбор продолжается. В случае невозможности дальнейшего применения правил на любом из шагов совершается откат – последний свернутый фрагмент восстанавливается и делается попытка применить другие правила. Окончательным вариантом разбора следует считать такую последовательность применения правил, которая порождает максимальную свертку фразы.
Так, в ходе разбора фразы “усталые гуси и утки стали снижаться”, возникают следующие варианты:
( усталые -> ( гуси + утки ) ) ~> ( стали <- снижаться ),
( усталые -> гуси ) и ( утки ~> ( стали <- снижаться ) ),
( ( усталые -> гуси ) + ( утки <- стали ) ) снижаться,
и ряд других.
Здесь каждая пара скобок включает ряд слов, обработанных некоторым правилом на очередном шаге анализа. Прямая стрелка указывает отношение подчинения при свертке именных и глагольных групп, знак плюса – свертку равноправных однородных членов, а волнистая стрелка – связь подлежащего со сказуемым. Такое представление соответствует дереву зависимостей во фразе.
Очевидно, что только первый вариант соответствует полному разбору – полносвязному дереву с одной вершиной, представленной глагольной группой “стали снижаться”. Второй вариант не полон, но все установленные синтаксические связи являются правильными и позволяют правильно разрешить омонимию у глагола “стать”. В третьем варианте присутствует ошибка, вызванная наличием у существительного “сталь” формы “стали” в родительном падеже множественного числа – выделена именная группа “утки стали” (аналогично “полосы стали”, “ковка стали”).
Как видно, процессу разбора соответствует целое дерево вариантов свертки фразы, вследствие чего производительность алгоритма падает экспоненциально с ростом числа используемых правил и количества слов в предложении. Так, очень сложные предложения могут порождать десятки тысяч вариантов разбора. Эта вычислительная проблема является общей для всех синтаксических анализаторов, ввиду чего на практике целесообразно ограничивать допустимое число рассматриваемых вариантов, и выбирать из них субоптимальный вариант свертки.
Как показал опыт, влияние подобного ограничения сказывается лишь на разборе небольшого количества особенно сложных предложений. Однако для разрешения омонимии даже неполного разбора практически всегда оказывается достаточно. Положительной стороной этого момента является то, что точность анализа и его скорость (обратно пропорциональная полноте) регулируются одним числовым параметром, определяющим соотношение между ними. Так, начиная с некоторого момента, повышение точности разбора на один процент требует двукратного снижения производительности. В нашей реализации этот предел соответствует скорости обработки около 50 Мбайт текста в час (P-II, 400Мгц), что приемлемо для прикладных систем.
4. Информационный портрет текста и именные группы
Основной проблемой, возникающей при формировании информационного портрета текста, является проблема выделения именных групп — устойчивых словосочетаний, в которые входят существительные и согласованные с ними прилагательные (например, “развитие сельского хозяйства”). Именно цельные именные группы, а не отдельные слова, характеризуют содержание текста и могут служить для тематического индексирования, авторубрицирования и т.п. Сопутствующей задачей является их ранжирование по значимости в тексте – вычисление так называемого “тематического веса”, отражающего вклад соответствующего понятия в содержание текста (его информативность).
Синтаксические отношения в пределах именных групп могут быть описаны десятком правил бесконтекстной грамматики, которые учитывают лишь согласование грамматических форм.
В общем случае полезно привлечение словаря моделей управления существительных, типа “борьба с [кем,чем?]”, “борьба против [кого,чего?]”. Однако, в отличие от глаголов, лишь немногие существительные может участвовать в управлении, вследствие чего доля образуемых ими словосочетаний относительно мала (см., к примеру, [8]).
В ходе полного синтаксического разбора фразы возможно установление синтаксических ролей именных групп в предложении, что позволяет ранжировать их с точки зрения важности для автора фразы. Так, наиболее важными являются слова из группы подлежащего, затем — сказуемого, прямого дополнения, косвенного дополнения, обстоятельства. В сочетании с алгоритмами статистического анализа эти факты способствуют более точному ранжированию понятий по значимости в информационном портрете документа.
Задача выявления дополнений и обстоятельств требует как минимум привлечения словаря моделей управления глаголов, который на данный момент отсутствует на рынке в объеме, достаточном для наших задач (в русском языке около 20 тысяч глаголов).
Задача выявления подлежащего в большинстве случаев решается достаточно просто и однозначно за счет введения соответствующих правил согласования существительного с глаголом.
Ниже приведен пример разбора нашим анализатором фразы:
(клинки,<- изготовленные) (великими->мастерами), становились
( (предметами <- (религиозного->поклонения) ), + (символами <- (гордости и+
( чести <- ( (живущих и+ будущих) -> (поколений<-японцев) ) ) ) ) )
После выбора наилучшего варианта разбора фразы включается обратный алгоритм синтеза, который проходит по дереву зависимостей и собирает все именные группы. Одновременно входящие в них слова ставятся в согласованные грамматические формы.
Полный список выделенных именных групп следующий:
100 КЛИНОК
50 СИМВОЛ ЧЕСТИ СЕГОДНЯШНЕГО ПОКОЛЕНИЯ ЯПОНЦА
50 СИМВОЛ ЧЕСТИ СЕГОДНЯШНЕГО ПОКОЛЕНИЯ
50 СИМВОЛ ЧЕСТИ ВЧЕРАШНЕГО ПОКОЛЕНИЯ ЯПОНЦА
50 СИМВОЛ ЧЕСТИ ВЧЕРАШНЕГО ПОКОЛЕНИЯ
50 СИМВОЛ ЧЕСТИ
50 СИМВОЛ ГОРДОСТИ
50 СИМВОЛ
50 ПРЕДМЕТ РЕЛИГИОЗНОГО ПОКЛОНЕНИЯ
50 ПРЕДМЕТ
50 КЛИНОК
50 ВЕЛИКИЙ МАСТЕР ДРЕВНОСТИ
50 ВЕЛИКИЙ МАСТЕР
40 ЧЕСТЬ СЕГОДНЯШНЕГО ПОКОЛЕНИЯ ЯПОНЦА
40 ЧЕСТЬ ВЧЕРАШНЕГО ПОКОЛЕНИЯ ЯПОНЦА
37 ЧЕСТЬ СЕГОДНЯШНЕГО ПОКОЛЕНИЯ
37 ЧЕСТЬ ВЧЕРАШНЕГО ПОКОЛЕНИЯ
33 РЕЛИГИОЗНОЕ ПОКЛОНЕНИЕ
33 МАСТЕР ДРЕВНОСТИ
30 СЕГОДНЯШНЕЕ ПОКОЛЕНИЕ ЯПОНЦА
30 ВЧЕРАШНЕЕ ПОКОЛЕНИЕ ЯПОНЦА
25 ЧЕСТЬ
25 СЕГОДНЯШНЕЕ ПОКОЛЕНИЕ
25 МАСТЕР
25 ГОРДОСТЬ
25 ВЧЕРАШНЕЕ ПОКОЛЕНИЕ
20 ПОКОЛЕНИЕ ЯПОНЦА
16 ПОКЛОНЕНИЕ
16 ДРЕВНОСТЬ
12 ПОКОЛЕНИЕ
10 ЯПОНЕЦ
Слева от каждой именной группы – понятия текста – указан его тематический вес, вычисляемый на основе синтаксической роли в предложении, а также места понятия в составе более сложной именной группы.
Так, если вес именной группы «предмет религиозного поклонения» равен 50 (не подлежащее), то веса входящих в нее понятий будут соответственно: 50 – для “предмет” (главного слова в группе), 50 * 2/3 = 33 для «религизное поклонение» (подчиненной группы длины 2 в группе длины 3) и 50 * 1/3 = 16 для «поклонение» (подчиненной группы длины 1 в группе длины 3).
Максимальный вес, равный 100, в данном примере имеет единственное понятие “клинок”, которое представляет подлежащее – главную тему фразы.
Заметим, что последняя часть разобранной фразы допускает второй, столь же полный вариант разбора:
(символами <-( (гордости и+ чести) <-
( (живущих и+ будущих) -> (поколений<-японцев) ) ) )
который порождает дополнительные именные группы:
гордость будущего поколения японца, гордость живущего поколения японца, символ гордости будущего поколения японца, символ гордости живущего поколения японца.
Наличие нескольких равноправных вариантов разбора есть явление синтаксической омонимии, разрешение которой невозможно без привлечения семантики, а иногда и прагматики, как в данном случае.
5. Заключение
Как показала практика, статистические методы анализа текста, на которых до настоящего времени были сконцентрированы усилия разработчиков интеллектуальных систем, достигли своего естественного предела. Дальнейшее усложнение математики без привлечения серьезной лингвистики не позволит заметно повысить качество подобных систем.
Несмотря на ограниченность синтаксических анализаторов текста, работающих без привлечения семантики, есть все основания утверждать, что их включение повышает точность работы статистических анализаторов, а также открывает качественно новые возможности, оставаясь в рамках разумных ограничений на вычислительные ресурсы.
Разработанный нами синтаксический анализатор русского языка, реализующий выделение именных групп и снятие омонимии, уже внедряется в очередную версию системы Russian Context Optimizer для СУБД Oracle [4]. С демонстрацией анализатора можно познакомиться на сайте http://research.metric.ru.
Литература
- Ермаков А.Е. Тематический анализ текста с выявлением сверхфразовой структуры // Информационные технологии. — 2000. — N 11.
- Ермаков А.Е., Плешко В.В. Ассоциативная модель порождения текста в задаче классификации // Информационные технологии. — 2000. — N 12.
- Плешко В.В., Ермаков А.Е., Липинский Г.В. TopSOM: визуализация информационных массивов с применением самоорганизующихся тематических карт // Информационные технологии. — 2001. — N 8.
- Ермаков А.Е. Проблемы полнотекстового поиска и их решение // Мир ПК. – 2001. – N 5.
- Ермаков А.Е., Плешко В.В. Тематическая навигация в полнотекстовых базах данных // Мир ПК. – 2001. – N 8.
- Мельчук И.А Опыт теории лингвистических моделей “Смысл-Текст”. Семантика, синтаксис. — М.: Школа «Языки русской культуры», 1999.
- Гладкий А.В. Формальные грамматики и языки. — М.: Наука, 1973.
- Розенталь Д.Э. Управление в русском языке. Словарь-справочник. – М.: Книга, 1986.
Restricted syntactic analysis of text document in information retrieval systems
A. E. Ermakov
Key words: syntactic parsing, ambiguity resolution, noun-groups extracting, statistical text analysis, information text structure.
The report is devoted to development of restricted syntactic parser for Russian language and embedding it into full-text document analysis systems produced by «Garant-Park-Internet» Ltd. The simplified syntactic parsing that omits verb control is still capable to extract noun-groups and resolve morphological ambiguity. We designed such parser on the base of context-free grammar. Simplification of the parsing algorithm allows us to process large arrays of text documents in times suitable for use in information retrieval and text analyzing systems. Our experiments demonstrate that this parser could be used on document preprocessing stage in statistical text analysis algorithms to increase the precision of these systems.
c # — Что такое парсинг?
c # — что такое парсинг? — Переполнение стека
Присоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
Просмотрено
86к раз
Парсинг
— это то, с чем я часто сталкиваюсь в процессе разработки, но, будучи юниором, я полагаю, что в какой-то момент, когда это понадобится, я научусь работать с ним.В моем текущем проекте мне сказали найти и использовать синтаксический анализатор HTML для определенной функции, я нашел пару в Интернете.
Но что на самом деле делает анализатор HTML? А что значит разобрать объект?
Создан 24 ноя.
ГрейсГрейс
2,11844 золотых знака2323 серебряных знака2323 бронзовых знака
1
Синтаксический анализ обычно применяется к тексту — акт чтения текста и преобразования его в более полезный формат в памяти, в некоторой степени «понимая», что он означает.Так, например, синтаксический анализатор XML возьмет последовательность символов (или байтов) и преобразует их в элементы, атрибуты и т. Д.
В некоторых случаях (особенно в компиляторах) существует разделение между лексическим анализом и синтаксическим анализом, поэтому реальная «понимающая» часть синтаксического анализатора работает с последовательностью токенов (идентификаторов, операторов и т. Д.), А не с необработанными символами.
Создан 24 ноя.
Джон СкитДжон Скит
1.3k118 золотых знаков87068706 серебряных знаков89168916 бронзовых знаков
При синтаксическом анализе берется набор данных и извлекается из него значимая информация. С помощью синтаксического анализа HTML вы хотите прочитать некоторый html и вернуть структурированный набор тегов и текста
Создан 24 ноя.
Адам Хопкинсон, Адам Хопкинсон
26.7k77 золотых знаков5757 серебряных знаков8787 бронзовых знаков
Вы можете начать здесь: http://en.wikipedia.org/wiki/Parsing. Краткая выдержка:
Синтаксический анализ — это процесс анализа строки
символы на естественном языке или на компьютерных языках,
в соответствии с правилами формальной грамматики.Приходит термин синтаксический анализ
от латинского pars (orationis), что означает часть (речи).
Создан 24 ноя.
Конамиман
47.5k1616 золотых знаков107107 серебряных знаков133133 бронзовых знака
0
Разобрать (компьютеры) , по словарю.com:
Для анализа (строки символов), чтобы связать группы символов с синтаксическими единицами базовой грамматики.
Создан 24 ноя.
Игорь ОксИгорь Окс
24.9k2525 золотых знаков8585 серебряных знаков112112 бронзовых знаков
2
Синтаксический анализатор — это компонент компилятора / интерпретатора, который разбивает данные на более мелкие элементы для облегчения перевода на другой язык.Парсер принимает входные данные в виде последовательности токенов или программных инструкций и обычно строит структуру данных в виде дерева синтаксического анализа или абстрактного синтаксического дерева.
Создан 11 июн.
Гаджендра К. Чаухан
3,34777 золотых знаков3838 серебряных знаков5454 бронзовых знака
В информатике и лингвистике парсинг или, более формально, синтаксический анализ — это процесс анализа текста, состоящего из последовательности токенов (например, слов), для определения его грамматической структуры по отношению к заданному (более или меньше) формальная грамматика.
: 0)
Википедия
Создан 24 ноя.
Монгус ПонгМонгус Понг
10.7k99 золотых знаков4040 серебряных знаков7171 бронзовый знак
1
Это процесс идентификации токенов [тегов, атрибутов] внутри HTML.
Создан 24 ноя.
рахулрахул
174k4747 золотых знаков221221 серебряный знак254254 бронзовых знака
Не пытайтесь написать ничего, кроме тривиального синтаксического анализатора.Для этого есть хорошие инструменты: ANTLR и bison — вот два, о которых я могу вспомнить.
Если вы воспользуетесь этими инструментами, вы сможете попросить о помощи, когда столкнетесь с проблемой.
ура,
Мартин.
Создан 24 ноя.
язык-CS
Stack Overflow лучше всего работает с включенным JavaScript
Ваша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie
Настроить параметры
Анализ
— Построение парсера (Часть I)
Большинство наборов инструментов разделяют весь процесс на две отдельных частей
- лексер (он же.токенизатор)
- парсер (он же грамматика)
Токенизатор разделит входные данные на токены. Парсер будет работать только с «потоком» токенов и строить структуру.
Похоже, ваш вопрос касается токенизатора. Но ваше второе решение объединяет синтаксический анализатор грамматики и токенизатор в один шаг. Теоретически это тоже возможно, но для новичка намного легче, чем , сделать это так же, как и большинство других инструментов / фреймворков: держите шаги отдельно.
К вашему первому решению: я бы обозначил ваш пример следующим образом:
T_KEYWORD_IF "если"
T_LPAREN "("
T_IDENTIFIER "x"
T_GT ">"
T_LITARAL "5"
T_RPAREN ")"
T_KEYWORD_RET "возврат"
T_KEYWORD_TRUE "правда"
T_TERMINATOR ";"
На большинстве языков ключевых слов нельзя использовать в качестве имен методов, имен переменных и так далее. Это уже отражено на уровне токенизатора ( T_KEYWORD_IF , T_KEYWORD_RET , T_KEYWORD_TRUE ).
Следующий уровень возьмет этот поток и, применяя формальную грамматику, построит некоторую структуру данных (часто называемую AST — Abstract Syntax Tree), которая может выглядеть так:
IfStatement:
Выражение:
Бинарный оператор:
Оператор: T_GT
LeftOperand:
ИдентификаторВыражение:
"Икс"
RightOperand:
Буквальное выражение
5
IfBlock
ReturnStatement
ReturnExpression
Буквальное выражение
"правда"
ElseBlock (пусто)
Реализация парсера вручную обычно выполняется некоторыми фреймворками.Эффективная реализация чего-то подобного вручную и обычно выполняется в университете в течение большей части семестра. Так что вам действительно стоит использовать какой-то фреймворк.
Входными данными для структуры синтаксического анализатора грамматики обычно является формальная грамматика в некотором виде BNF. Ваша часть «если» может выглядеть так:
IfStatement: T_KEYWORD_IF T_LPAREN Выражение T_RPAREN Инструкция;
Выражение: LiteralExpression | BinaryExpression | IdentifierExpression | ...;
BinaryExpression: LeftOperand BinaryOperator RightOperand;
....
Это только для того, чтобы понять идею. Правильный синтаксический анализ реального языка, такого как Javascript , — непростая задача. Но забавно.
Алгоритм
— синтаксический анализатор уравнения (выражения) с приоритетом?
Трудный путь
Вам нужен синтаксический анализатор с рекурсивным спуском.
Чтобы получить приоритет, вам нужно думать рекурсивно, например, используя образец строки
1 + 11 * 5
, чтобы сделать это вручную, вам нужно будет прочитать 1 , затем увидеть плюс и начать новый «сеанс» рекурсивного синтаксического анализа, начиная с 11 … и не забудьте проанализировать 11 * 5 в его собственный фактор, получив дерево синтаксического анализа с 1 + (11 * 5) .
Все это кажется настолько болезненным, даже если пытаться объяснить, особенно с добавленным бессилием C. Видите ли, после анализа 11, если бы вместо * на самом деле был +, вам пришлось бы отказаться от попытки составить термин и вместо этого проанализировать сам 11 как фактор. Моя голова уже взрывается. Это возможно с рекурсивной приличной стратегией, но есть способ лучше…
Легкий (правильный) путь
Если вы используете инструмент GPL, такой как Bison, вам, вероятно, не нужно беспокоиться о проблемах с лицензированием, поскольку код C, сгенерированный bison, не покрывается GPL (IANAL, но я почти уверен, что инструменты GPL не заставляют GPL на сгенерированный код / двоичные файлы; например, Apple компилирует код, например, Aperture с GCC, и они продают его без необходимости использования указанного кода GPL).
Загрузите Bison (или аналогичный, ANTLR и т. Д.).
Обычно есть пример кода, на котором вы можете просто запустить bison и получить желаемый код C, который демонстрирует этот калькулятор с четырьмя функциями:
http: // www.gnu.org/software/bison/manual/html_node/Infix-Calc.html
Посмотрите на сгенерированный код и убедитесь, что это не так просто, как кажется. Кроме того, преимущества использования такого инструмента, как Bison, заключаются в следующем: 1) вы что-то узнаете (особенно если вы читаете книгу Dragon и изучаете грамматику), 2) вы избегаете попыток NIH изобрести колесо. С настоящим инструментом-генератором синтаксического анализатора у вас действительно есть надежда на масштабирование позже, показывая другим людям, которых вы знаете, что синтаксические анализаторы — это область инструментов синтаксического анализа.
Обновление:
Здесь есть много дельных советов.Мое единственное предупреждение против пропуска инструментов синтаксического анализа или использования алгоритма Shunting Yard или ручного рекурсивного приличного парсера заключается в том, что маленькие игрушечные языки 1 могут когда-нибудь превратиться в большие реальные языки с функциями (sin, cos, log) и переменными, условиями и для петель.
Flex / Bison может оказаться излишним для небольшого простого интерпретатора, но одноразовый синтаксический анализатор + анализатор может вызвать проблемы в дальнейшем, когда необходимо внести изменения или добавить функции. Ваша ситуация будет отличаться, и вам нужно будет использовать свое суждение; просто не наказывайте других за свои грехи [2] и создавайте менее чем адекватный инструмент.
Мой любимый инструмент для парсинга
Лучшим инструментом в мире для этой работы является библиотека Parsec (для рекурсивных приличных парсеров), которая поставляется с языком программирования Haskell. Она очень похожа на BNF или на какой-то специализированный инструмент или предметно-ориентированный язык для синтаксического анализа (пример кода [3]), но на самом деле это обычная библиотека в Haskell, что означает, что она компилируется на том же этапе сборки, что и остальные. вашего кода Haskell, и вы можете написать произвольный код Haskell и вызвать его в своем парсере, и вы можете смешивать и сопоставлять другие библиотеки в одном и том же коде .(Встраивание подобного языка синтаксического анализа в язык, отличный от Haskell, кстати, приводит к множеству синтаксических ошибок. Я сделал это на C #, и он работает довольно хорошо, но не так красиво и лаконично.)
Примечания:
1 Ричард Столлман говорит, почему не следует использовать Tcl
Главный урок Emacs заключается в том, что
язык для расширений не должен
быть просто «языком расширения». Это
должен быть реальным языком программирования,
предназначен для написания и поддержки
содержательные программы.Потому что люди
захочу сделать это!
[2] Да, у меня навсегда остались шрамы от использования этого «языка».
Также обратите внимание, что когда я отправил эту запись, предварительный просмотр был правильным, но неадекватный парсер SO съел мой закрытый тег привязки в первом абзаце , доказывая, что синтаксические анализаторы не являются чем-то, с чем можно шутить, потому что если вы используете регулярные выражения и один от взлома вы, вероятно, получите что-то тонкое и маленькое неправильное .
[3] Фрагмент синтаксического анализатора Haskell с использованием Parsec: калькулятор с четырьмя функциями, расширенный показателями, круглыми скобками, пробелами для умножения и константами (такими как pi и e).- «>> = возврат. (\ x y -> B Pow x (B Sub (toScalar 0) y))
toOp = sym «->» >> = return. (B To)
mulop = sym «*» >> = возврат. (Б Мул)
<|> sym «/» >> = возврат. (B Div)
<|> sym «%» >> = return. (Мод B)
<|> возврат. (Б Мул)
addop = sym «+» >> = возврат. (B Добавить)
<|> sym «-» >> = возврат. (B Sub)
скаляр = число >> = возврат. toScalar
идент = литерал >> = возврат.Горит
parens p = делать
lparen
результат <- p
rparen
вернуть результат
Что такое парсинг? | The Mighty Programmer
Parsing — это процесс преобразования текста в формате в структуру данных . Тип структуры данных может быть любым подходящим представлением информации, выгравированной в исходном тексте .
- Дерево Тип является распространенным и стандартным выбором для синтаксического анализа XML, синтаксического анализа HTML, синтаксического анализа JSON и синтаксического анализа любого языка программирования.Выходное дерево называется Дерево синтаксического анализа или Абстрактное Синтаксическое дерево . В контексте HTML это называется объектной моделью документа (DOM).
- В результате синтаксического анализа файла CSV может быть получен список со списком значений или Список объектов записи.
- Graph Type — выбор для синтаксического анализа естественного языка.
Часть программы, которая выполняет синтаксический анализ, называется Parser .
Как это работает
Parser анализирует исходный текст на соответствие * предписанному формату.Если исходный текст не соответствует формату, выдается или возвращается ошибка.
- Если исходный текст не соответствует формату, выдается или возвращается ошибка.
- Если совпадает, возвращается «структура данных».
Формат
* закодирован внутри парсера.
Формат — это ДНК парсера.
Небольшой пример использования
Рассмотрим пример разбора даты из строки (источника) в формате ДД-ММ-ГГГГ в объект Date:
класс Дата {
int день;
int месяц;
int год;
}
Примечание по реализации
Для разбора даты я бы использовал Regular Expression 90 ( regex для краткости).Регулярное выражение можно сопоставить со строкой. Это также помогает в извлечении части исходного текста , если он совпадает.
Примечание. Это будет небольшая иллюстрация синтаксического анализа с помощью «Regex». Это может быть справедливым подходом для ввода текста в одну-две строки, но не во всех случаях. Возможно, вам придется написать парсер вручную (самый сложный) или использовать инструменты Parser Generator (умеренно сложные).
Код
Элемент даты синтаксического анализа и извлечения:
Строка date = «20-05-2012»;
Шаблон dateMatcher = Шаблон.компилировать («(\\ d {2}) - (\\ d {2}) - (\\ d {4})»);
Matcher matcher = dateMatcher.matcher (дата);
if (matcher.find ()) {
int day = Integer.parseInt (matcher.group (1));
int месяц = Integer.parseInt (matcher.group (2));
int год = Integer.parseInt (matcher.group (3));
вернуть новую дату (день, месяц, год);
} еще {
выбросить новое исключение DateParseException (дата + «недействительна»)
}
Код написан на Java.
Как работает этот код:
- Дата в формате ДД-ММ-ГГГГ может быть сопоставлена с помощью регулярного выражения:
(\ d {2}) - (\ d {2}) - (\ d {4})
где \ d соответствует любой цифре от 0 до 9,
{n} означает, сколько раз ожидается последний тип символа
() называется группой захвата и закрытой частью строки, которая будет извлечена.Каждая группа пронумерована, первой группе присваивается «1», второй - «2» и т. Д.
- Данная дата в виде строки сопоставляется с определенным регулярным выражением.
- Если совпадение прошло успешно, то день, месяц и год извлекаются из исходной строки с помощью Group Construct , предоставляемой API регулярных выражений. Это стандартная конструкция в любом API регулярных выражений на любом языке.
- Извлеченные части даты могут быть проверены; связанный код пропущен, чтобы вы могли его потренировать.
Это иллюстрация синтаксического анализа на основе регулярных выражений, который ограничен форматом, который может быть определен с помощью регулярных выражений. Это базовый пример синтаксического анализа. Язык программирования или формат, такие как синтаксический анализ XML, сложны по своей природе. Вы можете обратиться к книге «Crafting Interpreters», чтобы получить представление о полномасштабном синтаксическом анализе.
Ремесленники
Вы также можете прочитать о «Lezer: Система синтаксического анализа Code Mirror»
Лезер
Фазы синтаксического анализа
Синтаксический анализ можно рассматривать как комбинацию сканирования и синтаксического анализа или просто синтаксического анализа.
Сканирование
Сканирование — это процесс преобразования потока символов в токенов.
Токен представляет собой «концепцию», представленную форматом. Логически токен можно рассматривать как метку, присвоенную одному или нескольким символам. С точки зрения обработки: токен является объектом, может содержать лексему ³ , информацию о местоположении и т. Д.
На языке Java: , если , , а , int — примеры токенов.При синтаксическом анализе даты токены определяются Regex; \ d {2} (день, месяц), - (разделитель), \ d {4} (год) — токены. Примечание. День и месяц относятся к одному типу токенов. Маркер определяется «шаблоном символов», а не расположением символов.
Сканирование
также называется Tokenization или Lexical Analysis . Часть программы, которая выполняет сканирование, называется Lexer или Scanner или Tokenizer.
Синтаксический анализ
Синтаксический анализ анализирует структуру, сформированную для хранения токенов в порядке их расположения.Он также проверяет и извлекает выгравированные данные для создания предпочтительной структуры данных.
В примере анализа даты: «За днем следует месяц и год». Порядок проверяется Regex Engine, также извлечение выполняется на основе порядка и совпадений.
Ошибки, сообщаемые на этом этапе, называются синтаксическими ошибками . Возвращаясь к примеру анализа даты, 99-JAN-2021 — недопустимая дата; однако 99–99–9999 является допустимой датой, поскольку так сказано в правиле (\ d {2}) - (\ d {2}) - (\ d {4}) .Это может показаться абсурдным, но парсеры обычно проверяют синтаксическую правильность .
Заключительные ноты
Масштаб разбора определяет включение или исключение Сканирования как его части:
- Это полезно для крупномасштабного синтаксического анализа, такого как синтаксический анализ языка (естественный или программный), чтобы разделить сканирование и синтаксический анализ. В этом случае синтаксический анализ называется синтаксическим анализом .
- Для мелкомасштабного синтаксического анализа, такого как Date, может быть нецелесообразно разделять лексический анализатор и синтаксический анализ.В данном случае он называется Безсканирующий анализ .
Часто задачи синтаксического анализа делегируются генераторам кода синтаксического анализатора, таким как Antlr или Lex. Эти инструменты требуют набора правил или грамматики и генерируют код парсера.
Сгенерированные синтаксические анализаторы при синтаксическом анализе создают дерево, которое может не соответствовать желаемой структуре данных; однако эти библиотеки предоставляют достаточное количество API-интерфейсов для преобразования построенного дерева в желаемую структуру данных.
В мире парсеров есть еще кое-что; тип стилей синтаксического анализа: сверху вниз или снизу вверх, крайний левый или крайний правый вывод.Эти стили дизайна ограничивают возможности синтаксического анализатора. Вы можете перейти по следующей ссылке, чтобы получить общее представление об этих вариантах дизайна и их сравнение:
Руководство по синтаксическому анализу: алгоритмы и терминология
- Регулярное выражение — это алгебраическое выражение², представляющее группу строк.
- Алгебраическое выражение использует символы и операторы.
- Lexeme — это необработанная строковая версия Token.
Data Parser — Что такое анализ данных
В этой части мы будем объяснять концепции и алгоритмы, которые задействованы в синтаксическом анализе данных, чтобы вы могли лучше понять, что происходит.Здесь будут рассмотрены три части:
- Компоненты и термины парсера данных
- Грамматики
- Алгоритмы
1. КОМПОНЕНТЫ И УСЛОВИЯ ПАРСЕРЫ ДАННЫХ
A. ОБЫЧНЫЕ ВЫРАЖЕНИЯ
Регулярные выражения — это последовательность символов, имеющих шаблон. Несмотря на то, что они обычно считаются непригодными для синтаксического анализа, их можно использовать для синтаксического анализа простых входных данных. Заблуждение связано с ошибками, которые возникают, когда регулярные выражения используются для анализа всего, включая то, для чего они не предназначены.Когда это будет сделано, все закончится серией хрупких регулярных выражений, которые мы взломали вместе.
Регулярные выражения также можно использовать для анализа некоторых простых языков программирования. Не все языки можно анализировать с помощью регулярных выражений, а языки, которые можно использовать, называются регулярными языками. Регулярные языки также можно анализировать с помощью конечного автомата, и, поскольку он также является мощным, его можно использовать для реализации лексеров.
Хотя вы можете определить регулярный язык, используя ряд регулярных выражений, для более сложных языков требуется нечто большее.Как правило, если грамматика языка содержит элементы, которые рекурсивны или вложены, это не обычный язык. Экземпляр — HTML. Он может содержать произвольное количество тегов внутри другого тега, поэтому его нельзя назвать обычным языком. В более широком смысле, его нельзя проанализировать, используя только регулярные выражения, независимо от того, насколько квалифицирован синтаксический анализатор.
Регулярные выражения в грамматике
Поскольку большинство программистов знакомы с регулярными выражениями, они часто используются для определения грамматики языка.Их синтаксис более точно используется для определения правил синтаксического анализатора или лексера. Например, звезда Клини применяется в правиле как индикатор того, что конкретный элемент может присутствовать любое количество раз, начиная от нуля до бесконечности.
Правило отличается от реализации лексического анализатора или анализатора. Вы можете использовать механизм регулярных выражений вашего языка для реализации лексера. Для еще большей производительности регулярные выражения в грамматике преобразованы в конечный автомат.
Б. СТРУКТУРА A-PARSER
Полный синтаксический анализатор обычно состоит из двух частей; лексер, также известный как сканер или токенизатор, и соответствующий синтаксический анализатор. Синтаксический анализатор работает не непосредственно с текстом, а только с выводом лексического анализатора, поэтому ему нужен лексер. Однако некоторые парсеры не имеют отдельного лексера, а скорее объединяют лексер и парсер. Они называются парсерами сканеров.
Лексический анализатор сначала сканирует ввод, а затем создает соответствующие токены, после чего анализатор просматривает токены и выдает результат синтаксического анализа.
Безсканирующие анализаторы
Бесссканированные синтаксические анализаторы отличаются тем, как они работают, поскольку они действуют непосредственно на исходный текст, а не на токены, созданные лексером. Таким образом, синтаксический анализатор без сканирования действует и как лексер, и как синтаксический анализатор.
Неважно определять грамматику, но для целей отладки вам нужно знать, является ли анализатор без сканирования или нет.
C. ГРАММАТИКА
Грамматические правила, описывающие язык синтаксически.Грамматика описывает язык, и это применимо только к синтаксису, но не к семантике. Это означает, что грамматика определяет структуру языка, а не его значение. Чтобы убедиться в правильности ввода, необходимо проверить его каким-либо другим способом.
Например, представьте, что нужно определить грамматику для языка, показанного в определении абзаца;
ПРИВЕТ: «Привет»
НАЗВАНИЕ: [a-zA-z] +
Приветствие: ПРИВЕТ ИМЯ
Допустимый ввод грамматики: «Привет, Майкл» и «Привет, программирование».В любом случае они правы. Однако, поскольку «Программирование» — это не название, оно неверно семантически.
АНАТОМИЯ ГРАММАТИКИ
Существует несколько часто используемых форматов для описания грамматики, например, форма Бэкуса-Наура (BNF). У этого формата есть варианты, одним из которых является Расширенная форма Бэкуса-Наура, и ее преимуществом является простота обозначения повторения. Другой вариант BNF — это расширенная форма Бэкуса-Наура. Это полезно при описании протоколов двунаправленной связи.При использовании грамматики Бэкуса-Наура типичное правило имеет следующее представление;
<символ>:: = _expression_
Может быть заменен группой элементов с правой стороны; _expression_ и поэтому называется нетерминальным. Другой элемент _expression_ может также содержать другие нетерминальные символы, а также терминальные.
Терминальные символы — это символы, которые не отображаются во всей грамматике, и пример представляет собой строку символов, как в «Три».
Правило в техническом смысле определяет преобразование между нетерминальным набором элементов и нетерминальным и конечным наборами элементов с правой стороны. Это также известно как производственное правило.
ВИДЫ ГРАММАТИК
При синтаксическом анализе в основном существуют два типа грамматики. Это обычные грамматики и контекстно-свободные грамматики. Обычно для определения обычного языка и т. Д. Используется обычная грамматика, но недавний вид грамматики, известный как Parsing Expression Grammar (PEG), может также использоваться для определения контекстно-свободного языка, поскольку он столь же эффективен, как и контекстно-свободные грамматики. .Разница между этими двумя типами заключается в обозначениях и способах интерпретации правил.
С точки зрения сложности, обычные языки проще, чем контекстно-свободные, и их можно отличить по _выражению_ обычной грамматики. Это означает, что правая сторона может быть только одной из следующих;
- Обозначение одной клеммы
- Пустая строка
- Символ терминала, за которым следует нетерминальный символ
Теоретически это проще, чем на практике, так как это сложно проверить, потому что инструмент может разрешить использование большего количества терминальных символов в одном определении, а затем преобразовать выражение в соответствующую серию выражений, которые все принадлежат одному из вышеперечисленных — упомянутые случаи.
Таким образом, даже если вы напишете выражение, несовместимое с обычным языком, выражение будет преобразовано в правильную форму.
Д. ЛЕКСЕР
Функция лексического анализатора для преобразования последовательности символов, присутствующих в последовательности токенов, поэтому их также называют сканерами или токенизаторами. Лексеры важны при синтаксическом анализе, поскольку они преобразуют ввод в форму, которой синтаксический анализатор лучше управляет на более поздней стадии процесса. Обычно лексеры легче писать, чем парсеры, хотя в некоторых случаях оба одинаково сложны.
Важная функция лексеров — работа с пробелами. Вам нужно будет отбросить пробелы с помощью лексера, потому что его присутствие заставит синтаксический анализатор проверять его между каждым токеном, и это раздражающий процесс. Однако вы не всегда можете отбросить пробелы из-за их релевантности в некоторых случаях, например, в Python, где пробелы используются для идентификации блока кода. Даже в таких случаях лексер используется, чтобы отличить релевантные пробелы от нерелевантных перед синтаксическим анализом.
ГДЕ ЗАКАНЧИВАЕТСЯ ФУНКЦИЯ LEXER И НАЧИНАЕТСЯ ПАРСЕР
В большинстве случаев лексеры используются вместе с синтаксическими анализаторами, поэтому разделение между ними может быть затруднено в большинстве случаев. Это потому, что после синтаксического анализа результат должен быть релевантным для программы. Так что, в конце концов, вы заботитесь только о подходящем вам методе синтаксического анализа, даже если есть много способов синтаксического анализа данных.
ПАРСЕР
В широком смысле синтаксический анализатор данных — это программное обеспечение, которое выполняет весь процесс синтаксического анализа, но, в частности, синтаксический анализатор анализирует токены, создаваемые лексером.Это означает, что синтаксический анализатор обрабатывает наиболее важную и сложную часть синтаксического анализа, а лексер помогает в этом процессе.
Вывод синтаксического анализатора обычно представляет собой организованную структуру его кода в виде дерева. Дерево может быть деревом синтаксического анализа или абстрактным синтаксическим деревом, и различия между ними заключаются в том, как они представляют код и промежуточные элементы, определенные анализатором. Дерево выбрано потому, что с ним удобнее работать с кодом на разных уровнях.
Синтаксическая правильность против семантической правильности
Синтаксические анализаторы важны в компиляторах или интерпретаторах, но не ограничиваются ими, поскольку они также могут быть частью другого программного обеспечения. Для проверки синтаксической правильности кода можно использовать синтаксический анализатор, но при проверке семантической достоверности компилятор должен будет использовать выходные данные.
В следующем примере код синтаксически правильный, но неправильный семантически.
интервал x = 10
int сумма = x + y
, поскольку переменная (y) не определена, программа завершится ошибкой, если код будет выполнен.Синтаксический анализатор этого не узнает, поскольку он смотрит только на структуру кода, а не на переменные. С другой стороны, компилятор просматривает дерево синтаксического анализа и отслеживает все переменные, которые определены в первый раз. Он проходит по дереву второй раз, чтобы проверить правильность определения используемых переменных.
БЕЗСКАНЕРНЫЙ ПАРАМЕТР
Синтаксический анализатор без сканирования также называется синтаксическим анализатором без лексического анализа, и он выполняет токенизацию и синтаксический анализ за один шаг.Если различие между лексером и синтаксическим анализатором не является необходимым или затруднительным, лучше использовать синтаксический анализатор без сканирования.
ПРОБЛЕМЫ С РАЗБОРОМ РЕАЛЬНЫХ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ
Теоретически синтаксический анализ предназначен для работы с реальными языками программирования, но это проблема из-за некоторых проблем.
Контекстно-зависимые части
Несмотря на то, что инструменты синтаксического анализа предназначены для обработки контекстно-свободных языков, в некоторых случаях языки контекстно-зависимы, и это становится проблемой.Примером контекстно-зависимого элемента являются мягкие ключевые слова (строки элементов, которые могут действовать как ключевые слова в одних местах, а также как идентификаторы в других).
Пробел
Пробелы очень важны в некоторых языках программирования, таких как python, где отступ в операторе указывает, что он принадлежит определенному блоку кода.
Несмотря на то, что пробелы уместны в Python, они также неуместны в некоторых местах, например, в пробелах между словами или ключевыми словами.Проблема заключается в отступе, и самый простой способ справиться с этим — проверить отступ в начале строки и преобразовать его в соответствующий токен.
Несколько синтаксисов
Другая проблема, связанная с использованием реальных языков программирования при синтаксическом анализе, состоит в том, что язык может содержать участки кода с различным синтаксисом. Наиболее распространенным примером этого является препроцессор C или C ++, который сам по себе является сложным языком и может случайным образом появляться внутри любого кода C.
Что касается аннотаций, с ними легче работать, и они присутствуют во многих языках программирования. Они могут использоваться для обработки кода до того, как он попадет в компилятор, и могут дать команду процессору аннотации преобразовать код определенным образом перед аннотированным. Поскольку они появляются только в определенных местах, с ними легче справиться.
Висячие остальные
Эта проблема часто встречается при синтаксическом анализе данных, особенно тех, которые связаны с оператором if-then-else.Предложение Else является необязательным, поэтому оператор if может означать что угодно. Например;
Если один
Тогда если два
Тогда два
Еще ???
В этом примере не ясно, относится ли else к первому или второму if.
При решении проблемы обычно используется метод, связанный с связыванием else с ближайшим оператором if, и это делает синтаксический анализ контекстно-зависимым.
ДЕРЕВО ПАРСОВ И АБСТРАКТНОЕ ДЕРЕВО СИНТАКСИС
Эти два термина тесно связаны и иногда используются как синонимы. Оба они похожи, поскольку оба являются деревьями и имеют корень с узлами, представляющими весь исходный код. У корня есть последующие узлы, которые сами содержат поддеревья, представляющие меньшие части кода до появления отдельных токенов.
Разница между ними заключается в их уровнях абстракции. В дереве синтаксического анализа вы можете найти все токены, которые есть в программе, а также набор промежуточных правил.Но в абстрактном синтаксическом дереве остается только релевантная информация, которая помогает понять код.
Дерево синтаксического анализа представляет код, который ближе к конкретному синтаксису. Он показывает разные уровни детализации процесса синтаксического анализа.
// лексический анализатор
PLUS: «+»
WORD PLUS: «плюс»
НОМЕР: [0-9] +
// парсер
// труба | символ указывает на альтернативу между двумя
Сумма: NUMBER (PLUS | WORD_PLUS) NUMBER
В грамматике сумма может быть определена с помощью символа плюс (+) или использования строки плюс.
При разборе следующего кода;
10 плюс 21
Результирующее дерево синтаксического анализа и абстрактного синтаксиса будет;
Указание на конкретный оператор отсутствует в AST, и это единственная оставшаяся операция, которую еще предстоит выполнить. Конкретный оператор — это промежуточное правило.
ГРАММАТИКИ
Грамматики — это правила, которые используются для описания языка. Грамматика имеет несколько элементов, на которые следует обратить внимание, поскольку грамматика также может использоваться для определения обязанностей или выполнения кодов.
ПРОБЛЕМЫ ГРАММАТИКИ
Отсутствующий жетон
В некоторых типах грамматики определены только несколько лексем. Пример;
НАЗВАНИЕ: [a-zA-Z] +
Приветствие: «ПРИВЕТ» ИМЯ
Токен «HELLO» не определен, и обычно это происходит из-за того, что некоторые инструменты генерируют соответствующие токены для строки, чтобы сэкономить время.
Леворекурсивные правила
Важной особенностью парсеров является поддержка леворекурсивных правил.Это означает, что правило должно начинаться с ссылки на себя. Эта ссылка может быть косвенной и появляться в другом правиле, на которое ссылается первое правило.
Например, в арифметических операциях сложение может быть описано как два выражения, разделенных знаком плюс, но количество добавлений также может быть другим добавлением.
Дополнение: выражение «+»
выражение
Умножение: выражение «+»
выражение
// выражение может быть сложением, умножением или даже числовым выражением: умножение | дополнение | [0-9] +
В приведенном выше примере выражение имеет косвенную ссылку на себя через правила сложения и умножения.
Описание также похоже на множественное сложение, такое как 5 + 4 + 3. Это так, потому что его также можно интерпретировать как выражение (5) (‘+’) выражение (4 + 3. Правило сложения здесь состоит в том, что первое выражение соответствует варианту [0-9] +, а второй также является сложением. 4 + 3 также можно разделить на две его составные части;
Выражение (4) («+»)
Выражение (3)
Правило сложения здесь состоит в том, что оба выражения соответствуют опции [0-9] +
Поскольку леворекурсивные правила нельзя использовать с некоторыми генераторами синтаксического анализатора, другим вариантом будет длинная цепочка выражений, которые заботятся о наиболее важных операциях.
Предикаты
Предикаты — это правила, которые соответствуют только при определенных условиях. Их также называют синтаксическими или семантическими предикатами. Требуемое условие определяется с помощью кода, который поддерживается инструментом, для которого была написана грамматика.
Преимущество предикатов в том, что они допускают некоторую форму контекстно-зависимого синтаксического анализа, который иногда неизбежен при сопоставлении определенных элементов. Например, их можно использовать для проверки того, находится ли последовательность символов, определяющих мягкое ключевое слово, в правильном положении, где она в конечном итоге будет ключевым словом.Его недостатком является то, что он может замедлить процесс синтаксического анализа, а также сделать грамматику зависимой от языка программирования, на котором выражено условие.
Встроенные действия
Действия по внедрению выделяют коды, которые выполняются после совпадения с правилом. Их недостаток в том, что грамматику труднее читать, потому что правила окружены кодами. Как и предикаты, они также нарушают разделение между языком, описывающим грамматику, и кодом, который управляет результатами синтаксического анализа.
Встроенные действия чаще используются менее сложными генераторами синтаксического анализа, поскольку это единственный способ, с помощью которого коды могут легко выполняться после сопоставления узла. С генераторами парсеров единственный способ — получить доступ к дереву и самостоятельно выполнить правильный код. С помощью более продвинутых инструментов вы можете выполнять произвольный код, используя шаблон посетителя, когда это необходимо.
Действия
также могут помочь добавить определенные токены или изменить сгенерированное дерево, и это может быть единственным вариантом при работе со сложными языками программирования, такими как C.
ФОРМАТЫ
Что касается грамматики, существует два основных типа форматов; BNF и все его варианты, а также PEG. Многие инструменты также реализуют свои конкретные варианты форматов, в то время как некоторые инструменты полностью используют настраиваемые форматы. Пользовательский формат состоит из трех частей; параметры с пользовательским кодом, а затем раздел лексера, который заканчивается разделом синтаксического анализатора.
Поскольку форматы BNF являются основой контекстно-свободной грамматики, их также можно определить как формат CFG.
ФОРМА БАКУС-НАУР И ЕЕ ВАРИАНТЫ
BNF — очень успешный формат и основа для создания PEG. Поскольку он очень прост, он в основном используется не в исходной форме, а в виде более мощного варианта. В приведенном ниже примере можно увидеть важность вариантов BNF;
<буква> :: = "a" | "б" | "с" | "д" | "е" | "е" | "г" | "h" | «я» | "j" | "к" | "л" | "м" | "п" | "о" | "р" | "q" | "г" | "s" | "т" | "u" | "v" | "ш" | «х» | "у" | "z"
<цифра> :: = "0" | «1» | «2» | «3» | «4» | «5» | «6» | «7» | «8» | «9»
<символ> :: = <буква> | <цифра>
Символ может быть преобразован в любую из английских букв, и в этом примере допустимы только строчные буквы.Также применимо, в котором может быть любая из альтернативных цифр. Первая проблема заключается в том, что вам придется перечислять альтернативы индивидуально, и вы не можете использовать классы символов, как с регулярными выражениями.
Более сложная проблема заключается в том, что не существует простого способа обозначить необязательные элементы или существующие повторения, поэтому вам придется полагаться на логическую логику и символ (|).
<текст> :: = <символ> | <текст>
<персонаж>
Согласно правилу, может состоять из персонажа или более короткого, предшествующего
Приведенный ниже пример представляет собой древовидный синтаксический анализ для слова «собака»
.
Другие ограничения BNF состоят в том, что он затрудняет использование пустых строк или символов, которые используются форматом в грамматике.
Расширенная форма Бэкуса-Наура
EBNF был создан для устранения некоторых из вышеупомянутых ограничений. Это наиболее популярная форма, используемая в инструментах синтаксического анализа, и даже несмотря на то, что инструменты могут отличаться от стандартных обозначений. Обозначение EBNF более четкое и включает больше операторов для работы с необязательными элементами или конкатенацией.
ABNF
ABNF является сокращением от Augmented BNF и является одним из вариантов BNF. Он разработан с целью описания протоколов двунаправленной связи.Использование ABNF может быть столь же продуктивным, как и EBNF, но из-за некоторых его функций его использование ограничено интернет-протоколами.
ABNF также имеет синтаксис, отличный от синтаксиса EBNF. Например, альтернативный оператор представлен косой чертой (/). Он также имеет больше функций, чем EBNF, например, вы можете определить числовые диапазоны, такие как% x30-39, как [0-9]. Он также используется дизайнерами для включения стандартных правил, подобных классам символов, которые может использовать конечный пользователь.
ПЭГ
PEG — это сокращение от Parsing Expression Grammar.Это формат, основанный на старом грамматическом формате, который называется языком синтаксического анализа сверху вниз. Он похож на EBNF и также используется для поддержки широко используемых переменных, таких как диапазоны символов. Это не совсем похоже на EBNF, в отличие от использования формального символа стрелки вместо обычного символа равенства в присвоениях.
PEG против CFG
Теоретически различия между обоими форматами ограничены. PEG очень похож на алгоритм packrat, вот и все. Например, PEG не допускает левую рекурсию, но, хотя алгоритм может быть изменен для поддержки левой рекурсии, он устраняет свойство синтаксического анализа линейного времени.Парсеры PEG также обычно являются парсерами без сканирования.
Различие между PEG и CFG и, вероятно, наиболее важное, состоит в том, что при упорядочивании вариантов выбора в PEG он имеет смысл, в отличие от CFG. Если существуют различные допустимые способы синтаксического анализа ввода, это будет неоднозначно в CFG, и будет возвращена ошибка. Например, предоставив разработчику все действительные результаты для сортировки. Однако в PEG двусмысленность устранена, поскольку будет выбран первый применимый вариант, и поэтому PEG не может быть неоднозначным.
Недостатком является то, что вы должны быть особенно осторожны при перечислении возможных альтернатив, поскольку в долгосрочной перспективе вы можете иметь неожиданные последствия.
АЛГОРИТМЫ
Parsing имеет разные алгоритмы, каждый из которых имеет свои сильные и слабые стороны и требует частого обновления.
Parsing имеет две стратегии: синтаксический анализ сверху вниз и снизу вверх. Оба определены с использованием дерева синтаксического анализа, созданного синтаксическим анализатором.
Нисходящий синтаксический анализатор сначала определяет корень дерева синтаксического анализа, а затем переходит к поддеревьям, а затем к листьям дерева. В то время как восходящий синтаксический анализатор начинается с нижней части дерева и продвигается вверх до корня дерева.
Изначально было проще создавать нисходящие парсеры, хотя парсеры снизу вверх оказались более мощными. Но благодаря развитию технологий ситуация стала более сбалансированной.
Вывод связан со стратегиями и указывает порядок появления, в котором нетерминальные элементы в правиле справа применяются для получения нетерминального символа слева.С помощью терминов BNF можно сказать, что это указывает, как элементы в –expression_ используются для получения. Существуют две возможности: крайнее левое происхождение и крайнее правое происхождение. Первый указывает правила, которые применяются слева направо, а второй указывает правила, которые применяются справа налево.
Например, при попытке проанализировать результат символа, как определено в следующей грамматике;
expr_one =. . // вещи
expr_two =.. // вещи
result = expr_one «оператор» expr_two
, вы можете применить правило для символа expr_one перед expr_two или наоборот. Для крайней левой деривации вы выбираете первый вариант, но вы выбираете второй вариант для крайней правой деривации.
При применении деривации используется сначала в глубину, либо рекурсивно. Это означает, что сначала он применяется к первому выражению, а затем к полученному промежуточному результату.
ОБЩИЕ ЭЛЕМЕНТЫ
Эти общие элементы используются синтаксическими анализаторами, построенными с использованием стратегий «сверху вниз» и «снизу вверх».
Просмотр вперед и возврат
Lookahead используется для обозначения количества элементов, следующих за текущим и учитываемых при принятии решения. Например, синтаксический анализатор может проверить следующий токен, чтобы решить, какое правило применить сейчас. После совпадения с правильным правилом токен расходуется, но следующий остается в очереди.
Обратное отслеживание, с другой стороны, — это метод, специфичный для алгоритма, который находит решения сложных проблем, пробуя частичные решения и останавливаясь на наиболее многообещающем.Если тестируемое решение терпит неудачу, синтаксический анализатор откатывает назад и пробует другое.
Анализаторы диаграмм
Анализаторы диаграмм могут быть как восходящими, так и нисходящими. Они пытаются избежать возврата с помощью динамического программирования. Динамическое программирование — это метод, который используется для разбиения больших проблем на более мелкие для облегчения решения.
Алгоритм Витерби является примером общего алгоритма динамического программирования, который использует анализатор диаграмм.Он направлен на обнаружение наиболее вероятных скрытых состояний через известную последовательность событий.
АВТОМАТЫ
Автоматы — абстрактные машины. Среди синтаксических анализаторов распространен Pushdown Automaton (PDA), а среди лексеров — детерминированная конечная автоматизация (DFA). КПК — более мощная и сложная машина, чем DFA.
Поскольку они используются для определения абстрактных машин, они не связаны напрямую с реальным алгоритмом, а скорее используются для формального описания уровня сложности, с которым алгоритм должен иметь дело.
Поскольку DFA — это конечный автомат, различие, когда дело доходит до лексера, часто остается неопределенным. Это так, потому что у конечных автоматов есть готовые к использованию библиотеки, и поэтому DFA в большинстве случаев реализуется с конечным автоматом.
Лексирование с помощью детерминированного конечного автомата
Конечный автомат имеет много возможных состояний, каждое из которых имеет функцию перехода, и примером конечного автомата является DFA. Функции перехода отвечают за то, как машина переходит из одного состояния в другое в ответ на событие.Если машина используется для лексирования, входные символы подаются по одному, пока он не сможет построить токен.
Они используются, потому что они могут распознавать точный набор обычных языков, и поэтому они так же эффективны, как и обычные языки. Другая причина в том, что это несколько математических методов, которые можно использовать для проверки их свойств и манипулирования ими, и они могут работать с онлайн-алгоритмом.
Онлайн-алгоритм не требует, чтобы входные данные работали полностью. С помощью лексера токен можно распознать, как только его символы достигнут алгоритма.Вы также можете преобразовать набор регулярных выражений в DFA, и это упрощает ввод правил достаточно простым способом, чтобы у разработчиков не возникло никаких проблем с ними при работе. Оттуда вы можете автоматически преобразовать их в конечный автомат, который сможет эффективно с ними работать.
ВЕРХНИЕ АЛГОРИТМЫ
Это самая популярная стратегия из двух, и она применяется в нескольких алгоритмах.
LL ПАРСЕР
LL обозначает чтение входа слева направо, крайний левый вывод.Эти парсеры основаны на таблицах и не имеют обратного отслеживания, только просмотр вперед. Из этого видно, что они не зависят от какой-либо таблицы при принятии решений о применяемых правилах синтаксического анализа. Они находят правильные правила для применения;
Анализатор сначала просматривает текущий токен, а также необходимое количество предварительных токенов
И затем он применял разные правила, пока не было найдено правильное совпадение
Парсеры
LL не относятся к конкретному алгоритму, а относятся к классу парсеров.Таким образом, парсер LL может анализировать грамматику LL. Грамматики LL определяются количеством предварительных лексем, необходимых для их анализа, и это число указывается в круглых скобках рядом с LL; LL (k).
Таким образом, можно с уверенностью сказать, что синтаксический анализатор LL (k) использует k токенов просмотра вперед и, таким образом, он может анализировать грамматику, которая требует для анализа k токенов просмотра вперед. Грамматики LL (k) используются при сравнении различных алгоритмов и служат в качестве измерителя.
Значение грамматик LL
Использование LL-грамматик сверху связано с тем, что парсеры LL немного ограничительны, и оба они широко используются.Грамматики LL не поддерживают леворекурсивные правила, поэтому вы можете преобразовать любую леворекурсивную грамматику, и это ограничение влияет на производительность и мощность.
Потеря продуктивности основана на требовании написания грамматики определенным образом, а это требует много времени. Возможности ограничены также потому, что грамматике, которой может потребоваться 1 токен просмотра вперед, обычно при написании с использованием леворекурсивного инструмента, может потребоваться от 2 до 3 токенов просмотра вперед, когда он записывается нерекурсивным способом.
Потеря производительности может быть уменьшена с помощью алгоритма, преобразующего леворекурсивную грамматику в нерекурсивную. Примером инструмента, который может это сделать, является ANTLR, но если вы создаете свой собственный анализатор данных, вам придется делать это самостоятельно.
LL (1) и LL (*) — это два специальных типа грамматик LL (k), которые в прошлом были единственными практичными типами из-за простоты создания для них синтаксических анализаторов.
РАННИЙ ПАРСЕР
Парсер Эрли — это синтаксический анализатор диаграмм.Этот алгоритм похож на CYK, еще один похожий синтаксический анализатор, но он проще, но хуже по памяти и производительности. Преимущество алгоритма Эрли перед CYK заключается в том, что после сохранения частичных результатов он также имеет функцию прогнозирования правила, которое будет соответствовать следующему.
Парсер
Earley в основном разбивает правило на части. Пример показан ниже;
// пример грамматики
HELLO: «привет»
НАЗВАНИЕ: [a-zA-Z] +
Приветствие ПРИВЕТ ИМЯ
// Парсер Эрли разбивает приветствие следующим образом
//.ПРИВЕТ ИМЯ
// ПРИВЕТ. НАЗВАНИЕ
// ПРИВЕТ ИМЯ.
Положительным моментом парсера Earley является гарантия того, что он может анализировать все контекстно-свободные языки, тогда как другие алгоритмы, такие как LL или LR, могут анализировать только подмножество языков. Например, у него нет проблем с леворекурсивными грамматиками. В общем смысле синтаксический анализатор Эрли также может обрабатывать недетерминированные и неоднозначные грамматики.
Он может делать все это, но с риском снижения производительности.Однако для обычных грамматик он имеет линейную временную характеристику. Однако хорошо то, что языки, которые анализируются более традиционными алгоритмами, обычно представляют интерес.
Побочным эффектом этого является то, что он не имеет ограничений, поскольку заставляет разработчика писать грамматику в соответствии с определенным форматом, чтобы синтаксический анализ мог быть более эффективным. Другими словами, построение грамматики LL (1) может оказаться трудным для разработчика, но синтаксический анализатор, с другой стороны, может применить ее лучше.Таким образом, Эрли заставляет вас работать меньше, поскольку синтаксический анализатор делает все остальное.
Проще говоря, вы можете сказать, что Эрли позволяет вам использовать грамматику, которую легче писать, даже если производительность может быть не оптимальной.
Варианты использования парсера Earley
Парсеры
Earley, как мы видели, просты в использовании, но с точки зрения производительности им не хватает. Эти плюсы и минусы делают алгоритм более подходящим для использования в образовательных учреждениях, где продуктивность важнее скорости.
В первом варианте использования грамматики, которые пишет пользователь, работают правильно, но синтаксический анализатор периодически отправляет случайные ошибки. Ошибки на самом деле связаны с ограничениями, которые существуют в алгоритме, которые не понимают ваши пользователи. Таким образом, получая сообщения об ошибках, ваши пользователи вынуждены понимать работу вашего парсера и ее ненужность.
Хороший случай ситуации, когда производительность синтаксического анализатора более важна, чем его скорость, — это использование генератора синтаксического анализатора для реализации подсветки синтаксиса в помощь редактору.Редактору требуется поддержка многих языков, и возможность быстрой поддержки может быть важнее, чем быстрое выполнение задачи.
ПАКРАТ (ПЭГ)
Packrat и PEG были изобретены одним и тем же человеком, поэтому их часто связывают друг с другом. Синтаксический анализ Packrat имеет линейное время выполнения, потому что нет обратного отслеживания. Еще одна причина его хорошей эффективности — запоминание. Это процесс сохранения частичных результатов во время синтаксического анализа.Однако недостатком является объем памяти, необходимый для хранения результатов в процессе анализа. Если доступная память не соответствует требуемой, время линейного выполнения алгоритма теряется.
Packrat, как и другие, не поддерживает леворекурсивные правила, потому что PEG всегда должен выбирать первый вариант. Некоторые варианты алгоритма могут поддерживать прямые леворекурсивные правила, но делают это ценой потери линейной сложности.
Если необходимо, packrat может также выполнять бесконечное количество опережающих просмотров, и это влияет на время выполнения.
ПАРСЕР РЕКУРСИВНОГО СПУСКА
Синтаксический анализатор этого типа работает с набором рекурсивных процедур, и в большинстве случаев каждая процедура соответствует правилу грамматики. Итак, вы можете сказать, что структура парсера является зеркалом структуры грамматики.
Прогнозирующий синтаксический анализатор иногда используется как синоним нисходящего синтаксического анализатора, в то время как некоторые другие используют его для обозначения синтаксического анализатора с рекурсивным спуском без возврата. Синтаксический анализатор с рекурсивным спуском с возвратом — прямая противоположность второму значению прогнозирующего синтаксического анализатора.Таким образом, с анализатором рекурсивного спуска с возвратом, всякий раз, когда правило в последовательности не соответствует входным, оно возвращается, чтобы попробовать другое.
Синтаксические анализаторы рекурсивного спуска нелегко анализировать леворекурсивные правила. Это так, потому что алгоритм будет многократно вызывать одну и ту же функцию снова и снова. Чтобы решить эту проблему, вы можете использовать хвостовую рекурсию, а синтаксические анализаторы, которые используют этот метод для решения повторяющихся вызовов функции, называются хвостовыми рекурсивными синтаксическими анализаторами.
Хвостовые рекурсивные парсеры — это рекурсии в конце функции.Однако они используются не сами по себе, а вместе с преобразованиями правил грамматики, и эта комбинация позволяет синтаксическим анализаторам с рекурсивным спуском работать с леворекурсивными правилами.
ПРАТТ ПАРСЕР
Несмотря на то, что синтаксические анализаторы Pratt широко не используются, те, кто знает их ценность, оценят их. Этот алгоритм полагается не на грамматику, а на токены.
Обычно нисходящие синтаксические анализаторы работают лучше, если есть префикс, который различает разные правила. Поскольку это применимо ко всем языкам программирования, это одна из причин, по которой Pratt Parser оказывает незначительное влияние на мир синтаксического анализа данных.
Однако алгоритм Пратта
широко используется в выражениях. Из-за приоритета невозможно понять структуру ввода, просто посмотрев на порядок токенов. Таким образом, алгоритм запрашивает присвоение значения приоритета каждому токену, а также другим функциям, которые определяют действия на основе того, что находится слева и справа от токена.
ПАРСЕР КОМБИНАТОР
Это функция высшего порядка, она работает, принимая функцию синтаксического анализатора в качестве входных данных и отправляя новую функцию синтаксического анализатора в качестве выходных данных.Функция синтаксического анализатора — это функция, которая принимает строку и вывод в виде дерева синтаксического анализа.
Несмотря на то, что комбинаторный синтаксический анализатор легко построить, поскольку он является модульным, он менее сложен и медленнее. Таким образом, они в основном используются для простых задач синтаксического анализа или создания прототипов. Пользователь комбинатора синтаксического анализатора полагается на создателя комбинатора, но частично создает синтаксический анализатор вручную.
Комбинаторы парсера
не поддерживают леворекурсивные правила, как некоторые другие алгоритмы, но другие продвинутые формы могут это делать.Некоторые реализации также называют комбинатором монадического синтаксического анализатора, потому что они полагаются на структуру монады (функциональной программы). Монада объединяет функции, а также данные, и это зависит от типа данных. Тип данных определяет различные комбинации значений.
АЛГОРИТМЫ ВНИЗ-ВВЕРХ
Успех восходящего алгоритма связан с семейством многих LR-анализаторов. Однако они относительно непопулярны, потому что, как известно, их сложно построить, хотя парсеры LR более мощные, чем грамматики LL (1).
Алгоритмы сдвига-уменьшения имеют двухступенчатую функцию;
Shift: на этом этапе один токен считывается со входа, и он становится новым узлом
Уменьшить: на этом этапе дерево, полученное в результате сопоставления правильного правила, объединяется с уже существующим предыдущим поддеревом.
Можно сказать, что этап сдвига касается чтения ввода до завершения, а сокращение объединяет поддеревья для построения окончательного дерева парсера.
CYK PARSER
CYK — это сокращение от Cocke-Younger-Kasami.Этот алгоритм имеет главный недостаток, заключающийся в том, что грамматики должны быть выражены в нормальной форме Хомского. Это требование обусловлено тем, что алгоритм зависит от свойств этой формы для разделения ввода при попытке сопоставить все возможности. Теоретически любую контекстно-свободную грамматику можно преобразовать в соответствующую CNF, но это невозможно сделать вручную.
Алгоритм особенно полезен для конкретных задач, например, проблема членства. Он используется для проверки совместимости строки с определенной грамматикой.Алгоритм также может использоваться при обработке естественного языка в поисках лучшего синтаксического анализа среди доступных вариантов.
LR PARSER
LR — это сокращение от чтения слева направо, самого правого вывода. Это примеры восходящих синтаксических анализаторов, которые могут обрабатывать детерминированные контекстно-свободные языки линейно относительно времени, без использования обратного отслеживания, но с опережением.
Традиционно их сравнивают с синтаксическими анализаторами LL, поэтому существует сходство в количестве предварительных лексем, необходимых для синтаксического анализа языка.Синтаксический анализатор LR (k) может анализировать грамматики, требующие анализа k токенов просмотра вперед. Грамматики LR не такие строгие и более мощные, чем соответствующие парсеры LL.
В техническом смысле LR-грамматики являются надмножеством LL-грамматик, и значение этого состоит в том, что требуется только одна LR (1) грамматика, поэтому (k) обычно не включается.
Как и парсеры LL, они также основаны на таблицах и нуждаются в двух сложных таблицах. Проще говоря;
Одна из таблиц определяет действие парсера в зависимости от текущего токена, его состояния и наборов опережающих просмотров
Вторая таблица сообщает синтаксическому анализатору следующее состояние для перемещения
Парсеры
LR являются мощными и имеют отличную производительность, но требуемые им таблицы трудны для построения и могут вырасти слишком большими для обычных компьютерных языков.Поэтому их можно использовать только через генераторы парсеров.
Обобщенный синтаксический анализатор LR (GLR)
GLR — мощная разновидность парсеров LR. Они важны для анализа недетерминированных и неоднозначных грамматик. Его сила не в таблицах, которые такие же, как у традиционного парсера LR, но могут переходить в разные состояния. На практике, когда существует двусмысленность, он создает новый синтаксический анализатор, который может обрабатывать конкретный случай.
Наихудший случай сложности парсера GLR такой же, как и у анализатора Эрли, хотя его производительность может быть лучше в лучшем случае детерминированных грамматик.С точки зрения простоты создания, синтаксический анализатор Эрли также проще, чем синтаксический анализатор GLR.
Процесс анализа
— обзор
Очистка данных
По сути, вывод, который мы можем сделать из этого обсуждения, заключается в важности обеспечения качества данных перед их использованием в аналитических целях. Это указывает на необходимость поощрения гарантии очистки данных в исходных исходных системах, указывая на необходимость применения очистки данных на ранней стадии процесса, если это возможно.
Однако в обстоятельствах, когда есть желание включить данные, не соответствующие стандартам качества, в аналитическую среду, необходимо принять решение либо очистить данные, либо загрузить набор данных как есть. При этом полезно рассмотреть методы, используемые для очистки данных.
Анализ
Часто вариации или неоднозначность в представлении значений данных могут сбивать с толку как отдельных пользователей, так и автоматизированные приложения. Например, рассмотрим эти разные значения данных: {Калифорния, Калифорния, Калифорния., США-Калифорния, Калифорния, 06}. Некоторые из этих значений используют символьные строки, другие используют цифры, а некоторые используют знаки препинания или специальные символы. По большей части, человек прочитает их и поймет, что все они представляют одну и ту же концептуальную ценность: штат Калифорния. Тем не менее, автоматизируя процесс определения того, являются ли эти значения точными, или выясняя, существуют ли повторяющиеся записи, значения необходимо проанализировать на составляющие их сегменты, а затем преобразовать в стандартный формат.
Синтаксический анализ — это процесс идентификации значимых токенов в экземпляре данных с последующим анализом потоков токенов на предмет распознаваемых шаблонов.Токен — это совокупность нескольких отдельных слов, имеющих какое-то деловое значение; с данными о клиентах эти токены могут относиться к компонентам имени человека или компании, частям адреса или части какого-либо другого элемента данных, зависящего от домена. Например, мы можем обратиться к токену «титул», который представляет собой список часто используемых титулов, таких как «Мистер», «Миссис» и «Доктор», и каждый раз, когда мы видим слово, которое есть в нашем «Заголовки», мы можем использовать это слово как заголовок для последующего анализа паттернов.
Процесс синтаксического анализа разделяет каждое слово, а затем пытается определить взаимосвязь между словом и ранее определенными наборами токенов и сформировать последовательности токенов. Последовательности токенов отправляются в приложение сопоставления с образцом, которое ищет похожие образцы. Когда шаблон совпадает, к исходному значению поля применяется предопределенное преобразование для извлечения его отдельных компонентов, которые затем передаются в приложения драйвера. Инструменты на основе шаблонов являются гибкими в том смысле, что они могут использовать предопределенные шаблоны и поглощать вновь определенные или обнаруженные шаблоны для текущего анализа.
Стандартизация
При синтаксическом анализе используются определенные шаблоны, регулярные выражения или грамматики, управляемые в механизме правил, а также поиск в таблицах, чтобы различать допустимые и недопустимые значения данных. Когда шаблоны распознаны, могут быть запущены другие правила и действия для преобразования входных данных в форму, которую можно более эффективно использовать, либо для стандартизации представления (предполагая допустимое представление), либо для исправления значений (если будут выявлены известные ошибки) . Чтобы продолжить наш пример, каждая из наших ценностей для штата Калифорния {California, CA, Calif., US-CA, Cal, 06} может быть стандартизирован до стандартного двухсимвольного сокращения почтовой службы США, CA.
Стандартизация — это процесс преобразования данных в форму, указанную в качестве стандарта, и является прелюдией к процессу очистки. Стандартизация основана на службе синтаксического анализа, которую можно объединить с библиотекой доменов данных для разделения значений данных на несколько компонентов и преобразования компонентов в нормализованный формат. Стандартизация также может преобразовывать полные слова в сокращения или сокращения в полные слова, преобразовывать псевдонимы в стандартную форму имени, переводить на другие языки (например,g., с испанского на английский), а также исправить распространенные орфографические ошибки.
Стандартизация будет включать преобразования сокращения информации во время приложения консолидации или резюмирования и в конечном итоге может использоваться как средство извлечения информации о конкретных объектах (например, лицо, компания, номер телефона, местоположение) и присвоения ей семантического значения для последующего манипулирования. Например, рассмотрим эти две записи о клиентах:
- 1.
Elizabeth R. Johnson, 123 Main Street, Franconia, NH
- 2.
Бет Р. Джонсон, 123 Мэйн Стрит, Франкония, NH
Наша интуиция при просмотре этой пары записей позволяет нам сделать вывод о совпадении сущностей, потому что, кажется, достаточно эвристических данных, чтобы совершить такой скачок: мы знаем что «Бет» — это сокращенная версия «Элизабет», а почтовый адрес совпадает. Эвристические методы, такие как сопоставление псевдонима с именем полной версии (и другие подобные), могут быть собраны как простые преобразования, которые могут применяться в целом к анализируемым именам.
Существует множество различных типов данных, которые попадают в семантическую таксономию, которая обеспечивает некоторый интуитивно понятный набор правил стандартизации, связанных с контентом. Например, имена во многих культурах имеют вариантные формы (псевдонимы и т. Д.), Которые могут связывать любое имя по крайней мере с одной стандартной формой. Например, «Боб», «Роб», «Бобби» и «Робби» — все это разные формы имени «Роберт»; «Лиз», «Лиззи» и «Бет» могут быть формами имени «Элизабет».
После того, как имя с несколькими вариантами идентифицировано, процесс стандартизации может дополнить значение данных выбранной стандартной формой, которая будет использоваться на этапе связывания.Обратите внимание, что стандартизация не ограничивается именами или адресами. Другие абстрактные типы данных, которые можно стандартизировать, включают деловые слова, номера телефонов, отраслевой жаргон, коды продуктов и коды транзакций. И даже не имеет значения, применяется ли стандартная форма способом, не соответствующим реальной жизни. Например, «Бет Смит» можно не называть «Элизабет», но мы все равно можем присвоить стандартное «Элизабет» записям, потому что эта стандартизация используется исключительно как средство для другой цели: связывание и очищение.
Расширение аббревиатуры
Аббревиатура — это компактное представление некоторой альтернативной распознанной сущности, а поиск и стандартизация сокращений — еще один ориентированный на правила аспект очистки данных. Существуют разные виды сокращений. Один тип сокращает каждое из набора слов до меньшей формы, где сокращение состоит из префикса исходного значения данных. Примеры включают INC для инкорпорации, CORP для корпорации и ST для улицы. Другой тип сокращает слово, удаляя гласные или сокращая буквы для фонетики, например INTL или INTRNTL для международного, PRGRM для программы и MGR для менеджера.Третья форма сокращения — это акроним, в котором первые символы каждого набора слов объединены в строку, например USA для Соединенных Штатов Америки и RFP для запроса предложений. Аббревиатуры необходимо проанализировать и распознать, а затем можно использовать набор трансформационных бизнес-правил для преобразования сокращений в их расширенную форму.
Коррекция данных
После того, как компоненты строки были идентифицированы и стандартизированы, на следующем этапе процесса предпринимается попытка исправить те значения данных, которые не распознаны, и дополнить исправляемые записи исправленной информацией.Очевидно, что если мы сможем распознать, что данные ошибочны, мы захотим исправить эти данные. Существует несколько различных способов автоматического исправления данных, и все они полагаются на какую-то интеллектуальную базу знаний правил и преобразований или некоторые эвристические алгоритмы для распознавания и связывания вариаций известных значений данных. Важно понимать, что процесс исправления можно автоматизировать только частично; у многих поставщиков может сложиться впечатление, что их инструменты могут полностью исправить неверные данные, но серебряной пули нет.
В целом процесс исправления основан на ведении набора неверных значений и их исправленных форм. Например, если слово International часто ошибочно пишется как «Intrnational», может существовать правило, сопоставляющее неправильную форму с правильной формой. Некоторые инструменты могут включать бизнес-знания, накопленные за длительный период времени, что составляет обширные базы знаний правил, включенных в эти продукты; К сожалению, это открывает двери для множества непонятных правил, которые отражают множество особых случаев.
Этот подход ошибочен, потому что эффект накопления правил исправления, основанный на анализе определенных видов данных (обычно имен и адресов), смещает процесс исправления к информации такого рода. Кроме того, большая часть данных одной организации отличается от данных любой другой организации, и, следовательно, бизнес-правила, регулирующие использование этих данных, также отличаются. Использование бизнес-правил других организаций по-прежнему будет приносить пользу, особенно если содержимое данных схоже, но всегда будет какая-то область, в которой людям нужно будет взаимодействовать с системой, чтобы принимать решения о корректировках данных.
Наконец, данные могут быть восприняты как неверные только при наличии правил, указывающих на правильность. Неточность или неточные значения данных могут присутствовать в наборе, но нет способа определить эту недействительность без источника правильных значений, с которыми можно было бы сравнивать. Использование других наборов правил корректности может привести к серьезной проблеме: данные, которые уже могут быть хорошими, могут быть непреднамеренно изменены на некорректные. Примером этого при коррекции адреса является знаменитое шоссе Восток-Запад в пригороде Вашингтона, округ Колумбия.Поскольку в адресах со словом «Восток» в начале ожидается, что это слово используется в качестве префикса направления, а не как часть самого названия улицы, некоторые приложения неправильно «исправляют» это на «E. Западное шоссе », что не является названием дороги.
Еще более серьезной проблемой является представление о том, что данные верны, хотя на самом деле это не так. Иногда единственный способ определить неверные данные — это непосредственный просмотр данных аналитиком вручную.
Обновление отсутствующих полей
Одним из аспектов очистки данных является возможность заполнения полей, в которых отсутствует информация.Отсутствующие значения могут содержать больше информации, чем мы могли бы подозревать; отсутствие значения может быть вызвано одной из следующих причин.
- ▪
Известно, что в этом поле действительно нет значения.
- ▪
Известно, что есть значение, которое должно войти в поле, но по какой-то причине значение на данный момент неизвестно, и неясно, станет ли это значение когда-либо известным.
- ▪
Известно, что для этого поля есть значение, и в какой-то момент в будущем это значение будет получено и заполнено.
- ▪
Для этого нет применимого значения из-за некоторого ограничения, зависящего от других значений атрибутов.
- ▪
Для этого поля есть значение, но оно не соответствует предопределенному набору допустимых значений для этого поля.
Это лишь краткий список существующих типов нулевых значений. В зависимости от нулевого типа могут существовать способы вменения отсутствующего значения, хотя некоторые подходы более надежны, чем другие.Например, мы можем попытаться заполнить поле пола человека на основе его или ее имени, но это не обязательно сработает с человеком с трансгендерным именем.
В некоторых других случаях причина отсутствия значения может быть связана с ошибками в исходных данных, и после процесса очистки у нас может быть достаточно информации, чтобы правильно заполнить отсутствующее поле. Для недоступных полей, если причина пропусков связана с нехваткой данных во время создания экземпляра записи, то процесс консолидации может предоставить достаточно информации, чтобы сделать доступными данные, которые ранее были недоступны.Для неклассифицированных полей причина невозможности классификации значения может заключаться в том, что ошибочные данные в других атрибутах помешали классификации. Учитывая скорректированные данные, можно ввести правильное значение. Для неизвестных атрибутов процесс очистки и консолидации может предоставить недостающее значение.
Однако важно понимать, что без хорошо задокументированного и согласованного набора правил для определения того, как заполнить отсутствующее поле, это может быть (как минимум) контрпродуктивным и (в худшем случае) опасным для заполните пропущенные значения.Соблюдайте строгую осторожность при автоматизации замены отсутствующих значений.
Двойной анализ и устранение с помощью разрешения идентификации
Поскольку операционные системы органически выросли в набор корпоративных приложений, нет ничего необычного в том, что несколько экземпляров данных в разных системах будут по-разному ссылаться на один и тот же объект реального мира. С другой стороны, желание консолидировать и связать данные об одних и тех же бизнес-концепциях с высокой степенью уверенности может убедить кого-то в том, что запись может еще не существовать для реального объекта, хотя на самом деле это действительно так.Обе эти проблемы в конечном итоге представляют собой одну и ту же основную задачу: возможность сравнить идентифицирующие данные в паре записей, чтобы определить сходство между этой парой или различить сущности, представленные в этих записях.
Обе эти проблемы решаются посредством процесса, называемого разрешением идентичности, в котором оценивается степень сходства между любыми двумя записями, чаще всего на основе взвешенного приблизительного соответствия между набором значений атрибутов между двумя записями.Если оценка выше определенного порога, две записи считаются совпадающими и представляются конечному клиенту как наиболее вероятно представляющие одну и ту же сущность. Разрешение идентичности используется для распознавания, когда лишь незначительные отклонения предполагают, что разные записи связаны и где значения могут быть очищены, или когда достаточные различия между данными предполагают, что две записи действительно представляют разные сущности. Поскольку сравнение каждой записи с каждой другой записью требует больших вычислительных ресурсов, многие службы данных используют расширенные алгоритмы для блокировки записей, которые, скорее всего, содержат совпадения, в меньшие наборы, чтобы сократить время вычислений.
Разрешение идентификации обеспечивает основу для более сложной службы базовых данных: анализ и устранение дублирующихся записей. Идентификация похожих записей в одном наборе данных, вероятно, означает, что записи дублируются и могут быть подвергнуты очистке и / или удалению. Идентификация похожих записей в разных наборах может указывать на связь между наборами данных, что помогает облегчить объединение или аналогичные записи для целей очистки данных, а также для поддержки аналитических приложений, которые ожидают увидеть единое представление о ключевых объектах, таких как продукт / цены. модели или инициативы по профилированию клиентов.
Что такое парсер? — Определение из Техопедии
Что означает синтаксический анализатор?
Синтаксический анализатор — это компонент компилятора или интерпретатора, который разбивает данные на более мелкие элементы для облегчения перевода на другой язык. Парсер принимает входные данные в виде последовательности токенов, интерактивных команд или программных инструкций и разбивает их на части, которые могут использоваться другими компонентами в программировании.
Анализатор обычно проверяет все предоставленные данные, чтобы убедиться, что их достаточно для построения структуры данных в форме дерева синтаксического анализа или абстрактного синтаксического дерева.
Techopedia объясняет синтаксический анализатор
Чтобы код, написанный в удобочитаемой форме, мог быть понят машиной, он должен быть преобразован в машинный язык. Эту задачу обычно выполняет переводчик (интерпретатор или компилятор). Синтаксический анализатор обычно используется как компонент переводчика, который организует линейный текст в структуру, которой можно легко манипулировать (дерево синтаксического анализа). Для этого он следует набору определенных правил, называемых «грамматикой».
Общий процесс синтаксического анализа включает три этапа:
Лексический анализ: Лексический анализатор используется для создания токенов из потока входных строковых символов, которые разбиваются на небольшие компоненты для формирования значимых выражений.Токен — это наименьшая единица языка программирования, имеющая какое-то значение (например, +, -, *, «функция» или «новый» в JavaScript).
Синтаксический анализ: Проверяет, образуют ли сгенерированные токены осмысленное выражение. Это использует контекстно-свободную грамматику, которая определяет алгоритмические процедуры для компонентов. Они работают, чтобы сформировать выражение и определить конкретный порядок, в котором должны быть размещены токены.
Семантический анализ: Заключительный этап синтаксического анализа, на котором определяется значение и значение проверенного выражения и предпринимаются необходимые действия.
Основная цель синтаксического анализатора — определить, могут ли входные данные быть получены из начального символа грамматики. Если да, то каким образом можно получить эти входные данные? Это достигается следующим образом:
Анализ сверху вниз: Включает поиск в дереве синтаксического анализа для поиска крайних левых производных входного потока с использованием расширения сверху вниз. Анализ начинается с начального символа, который преобразуется во входной символ, пока все символы не будут переведены и не будет построено дерево синтаксического анализа для входной строки.Примеры включают синтаксические анализаторы LL и синтаксические анализаторы с рекурсивным спуском. Анализ сверху вниз также называется прогнозным или рекурсивным анализом.
Анализ снизу вверх: Включает перезапись входных данных обратно в начальный символ. Он действует в обратном порядке, отслеживая крайнее правое происхождение строки, пока дерево синтаксического анализа не будет построено до начального символа. Этот тип синтаксического анализа также известен как синтаксический анализ с уменьшением сдвига. Одним из примеров является парсер LR.
Синтаксические анализаторы широко используются в следующих технологиях:
Java и другие языки программирования.