Как делать синтаксический разбор текста
Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:
| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |
Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.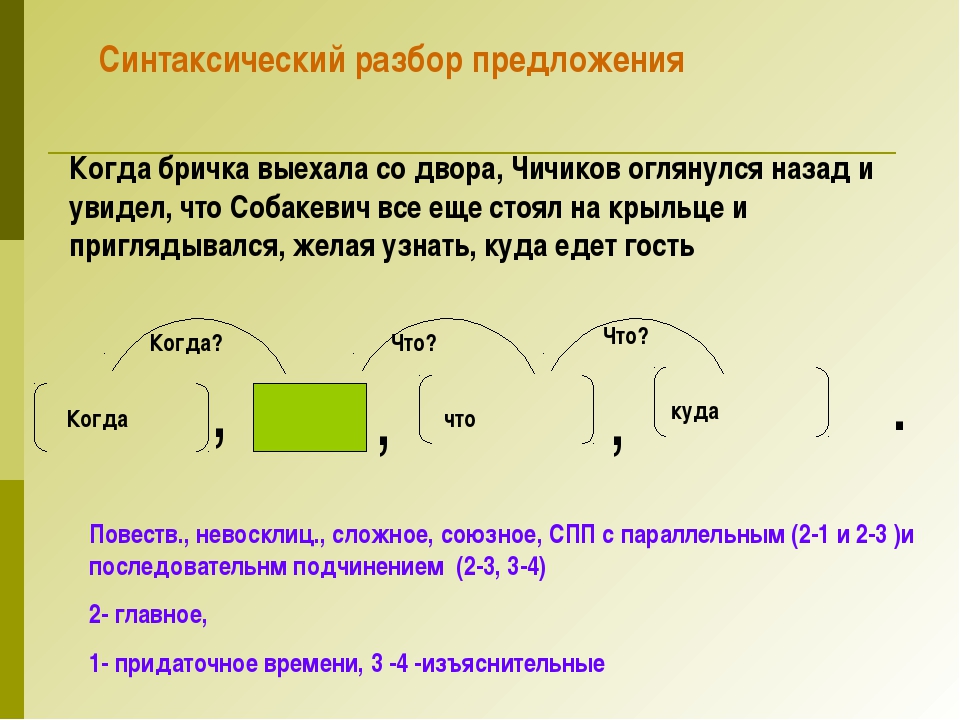
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложения
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное.
 Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное. - Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
 Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.Сказуемое
- Отмечаем, чем является сказуемое – простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое – какой формой глагола;
- составное глагольное – из чего оно состоит;
- составное именное – какая употреблена связка, чем выражается именная часть.
В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Справочная информация
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое – это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое – это глагол, т.е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение – второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта – было бы скучно, уж поверьте. Итак, обстоятельство – это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?». А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной – важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» – как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая – придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой – как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т.е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется – оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола – действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость. Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны. Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Единицы синтаксиса
Синтаксис изучает связь слов внутри словосочетаний или предложений. Таким образом, единицами синтаксиса являются словосочетания и предложения – простые или сложные. В этой статье мы будем говорить о том, как сделать синтаксический разбор предложения, а не словосочетания, хотя нередко в школе просят сделать и его.
Зачем нужен синтаксический разбор предложения
Синтаксический разбор предложения предполагает подробное рассмотрение его структуры. Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Члены предложения
Среди членов предложения всегда сначала выделяют главные: подлежащее и сказуемое. Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Грамматическая основа может состоять как из двух главных членов, так и включать в себя только один из них: или только подлежащее, или только сказуемое. Во втором случае мы говорим, что предложение односоставное. Если же присутствуют оба главных члена – двусоставное.
Если, кроме грамматической основы, слов в предложении нет, оно называется нераспространённым. В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.
если в предложении есть слова, которые членами предложения не являются (например, обращение), оно все равно считается нераспространенным.
Выполняя разбор, необходимо называть и часть речи, которой выражен тот или иной член предложения. Этот навык ребята отрабатывают, изучая в 5 классе русский язык.
Характеристика предложения
Чтобы дать характеристику предложению, надо указать надо его описать
- по цели высказывания;
- по интонации;
- по количеству грамматических основ и так далее.
Ниже мы предлагаем план характеристики предложения.
По цели высказывания: повествовательное, вопросительное, побудительное.
По интонации: восклицательное или невосклицательное.
Восклицательными могут быть любые по цели высказывания предложения, а не только побудительные.
По количеству грамматических основ: простое или сложное.
Если предложение простое, движемся дальше по плану; если сложное, путь отсюда придется пройти несколько раз: столько, сколько частей в сложном.
По количеству главных членов в грамматической основе: односоставное или двусоставное.
Если предложение односоставное, надо определить его вид: назывное, определённо-личное, неопределённо-личное, безличное.
По наличию второстепенных членов: распространённое или нераспространённое.
Если предложение чем-то осложнено, то это также надо указать. Это план синтаксического разбора предложения; лучше его придерживаться.
Осложнённое предложение
Предложение может быть осложнено обращением, вводными и вставными конструкциями, однородными членами, обособленными членами, прямой речью. Если какой-то из этих видов осложнений присутствует, то надо указать, что предложение осложненное, и написать чем.
Если предложение сложное
Если необходимо сделать разбор сложного предложения, надо сначала указать, что оно сложное, и определить его тип: союзное или бессоюзное, а если союзное, то еще и сложносочиненное или сложноподчиненное. Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
В таблице приведены второстепенные члены и их вопросы.
Второстепенные члены предложения
Вопросы
Кого? чего? кому? чему? кем? чем? о ком? о чем?
Какой? чей? который по счету?
Где? когда? куда? откуда? почему? зачем? как? в какой степени?
Второстепенные члены могут быть выражены разными частями речи, например определение:
шерстяная юбка – прилагательное;
юбка из шерсти – существительное;
юбка отглаженная – причастие;
привычка побеждать – инфинитив…
Пример синтаксического разбора предложения
Подчеркнем грамматические основы. Их две: знал и ты переехала . Определим части речи: знал – сказуемое, выражено глаголом в личной форме и т.д.
Их две: знал и ты переехала . Определим части речи: знал – сказуемое, выражено глаголом в личной форме и т.д.
Теперь подчеркиваем второстепенные члены:
Переехала откуда? из деревни – обстоятельство, выражено существительным; куда? в город – тоже обстоятельство, тоже выражено существительным. Маша – это обращение, оно не является членом предложения.
Теперь дадим характеристику. Предложение повествовательное, невосклицательное, сложное, союзное, сложноподчиненное.
Первая часть «не знал» неполная, нераспространенная.
Вторая часть двусоставная, распространенная. Осложнено обращением.
По окончании разбора надо составить схему сложного предложения.
Что мы узнали?
Синтаксический разбор призван помочь понять структуру предложения, поэтому необходимо указать все, что может быть с ней связано. Выполнять разбор лучше по плану, тогда больше шансов, что вы ничего не забудете. Необходимо не только подчеркнуть члены предложения, но и определить части речи, и дать характеристику предложению.
Синтаксический разбор предложения (5 онлайн-сервисов)
Синтаксический разбор предложения — стандартная задача при изучении русского или иностранного языка. Сейчас её выполнение можно переложить на онлайн-сервисы. Они автоматически определяют структуру каждого предложения и выдают результат в удобном виде.
К сожалению, подобные сервисы не всегда делают разбор на 100% правильно, поэтому к результатам их работы следует относиться критично. Чтобы убедиться в отсутствии ошибок, рекомендуем проверять результат разбора на нескольких ресурсах или сверяться с учебниками.
Как сделать синтаксический разбор предложения на русском языке
ProgaOnline
ProgaOnline — единственный веб-ресурс, в состав которого входит сервис для синтаксического разбора предложений на русском языке. Он обрабатывает тексты размером до 15 000 символов.
Сервис не только определяет и подчеркивает члены предложения, но и показывает морфологию каждого слова: часть речи, число, род, падеж.
К сожалению, ProgaOnline не описывает предложение, как этого требует полноценный синтаксический разбор. Он показывает только основную информацию. Давать описание (повествовательное, невосклицательное, простое, двусоставное и т.п.) вам придётся самостоятельно.
Плюс этого ресурса в том, что у него есть версия для Android, которая показывает части речи в предложении. Приложение доступно для бесплатного скачивания в Google Play.
Школьный помощник
«Школьный помощник» — сервис, помогающий закрепить знания или изучить материал, пропущенный в школе. Здесь нет такого функционала, как у ProgaOnline. Помощник не выдает готовый результат, он предлагает лишь прокачать навыки синтаксического разбора предложений, чтобы эта задача перестала вызывать у вас затруднения.
Тест «Синтаксический разбор простого предложения» состоит из четырёх заданий. В первом требуется выбрать правильный вариант синтаксического разбора. Во втором, третьем и четвёртом нужно определить члены предложения.
Для каждого задания есть готовое решение, но оно доступно только зарегистрированным пользователям.
В самом тесте никакой справочной информации нет. После проверки задания вы получите ответ, правильно или неправильно оно выполнено.
Учим Орг
«УчимОрг» — сайт, на котором публикуются различные материалы для учёбы. Функции синтаксического разбора предложений он также не содержит, но здесь есть полезные материалы для освоения этой темы. На этой странице подробно описано, как делать синтаксический разбор. Есть наглядные примеры с подчеркиванием грамматической основы и других членов предложения.
Синтаксический разбор англоязычных предложений
LinguaKit
LinguaKit — сервис для анализа текстов на английском, испанском, португальском и галисийском языках. На нём, как и на ProgaOnline, есть полноценное веб-приложение для синтаксического разбора предложений.
Ресурс поддерживает загрузку текста тремя способами:
- Путем вставки в окно редактора фрагмента объёмом до 5000 символов.
- Указанием ссылки на веб-страницу, где он опубликован.
- Чтением из файла в форматах DOC, DOCX, ODT, TXT, EPUB или HTML.

После обработки предложения вы получите его синтаксический разбор в графическом виде с указанием связей между его частями. В результатах также отмечается часть речи и грамматическая роль каждого слова.
С одного IP-адреса в сутки доступно не более 20 проверок. Для снятия ограничений, вероятно, нужно оформить подписку, однако на странице с тарифами нет никакой информации о ее условиях и стоимости.
Delph-in
Delph-in — сервис для профессиональных лингвистов, где собраны материалы про разные языки. В его состав также входит приложение для синтаксического разбора предложений на английском языке.
Результат обработки представлен в виде схемы с указанием связей между частями предложения. Интерпретировать его без специальной подготовки довольно сложно. Однако если вы занимаетесь лингвистикой, то найдёте на этом ресурсе большое количество полезной информации, рецензируемой профессионалами.
Синтаксический разбор / Русский на 5
Синтаксический разбор — это разбор синтаксических единиц: словосочетаний и предложений. Естественно, характеристика словосочетания отличается от характеристики предложения, потому что словосочетание не является самостоятельной синтаксической единицей, как предложение. Оно устроено иначе.
В разборе простых и сложных предложений много общего: нужно определить тип предложения по цели высказывания и эмоциональной окрашенности, произвести разбор по членам предложения. Но простое предложение имеет лишь одну грамматическую основу, а сложные — более одной. Поэтому для последних важно выявить характер синтаксической связи между частями. То есть схемы разбора простого и сложного предложения имеют важные различия. Приступая к разбору, важно понимать, какие единицы синтаксиса ты разбираешь и что для этого требуется.
Особенности синтаксического разбора
§1.
Что такое синтаксический разбор, в чём его специфика
§2. Что нужно знать и уметь делать
§3. Порядок разбора синтаксических единицСоветы. Как приступить к делу
О чём важно подумать перед разбором предложения, что с чем не перепутать, в чём не ошибиться
Примеры и комментарии
Это то, чего не хватает в учебниках. Здесь на конкретных образцах показано, как разбирать словосочетания и предложения
§1. Словосочетание
§2. Простое предложение
§3. Сложное предложениеТипичные ошибки
Разберись с типичными ошибками и не повторяй их. Без этого знания будут неполными
§1. Ошибки при определении членов предложения
§2. Ошибки при разборе словосочетания
§3. Ошибки при разборе простого предложения
§4. Ошибки при разборе сложного предложенияПервые шаги. Подготовительные задания.
Учись выполнять отдельные важные операции, простые действия. Это поможет избежать множества проблем.
Темы:
Умение находить словосочетания в предложениях
Умение определять члены предложения
Умение определять границу между частями сложного предложения
Умение определять, как осложнена структура предложенияТренинг «Синтаксический разбор»
Полный синтаксический разбор предложений
Итоговый тест «Синтаксический разбор в формате ЕГЭ»
Пройди итоговые тесты по теме: Синтаксический разбор слова
 Что такое синтаксический разбор, в чём его специфика
Что такое синтаксический разбор, в чём его спецификаСинтаксический разбор простого словосочетания — Агентство переводов Lingvotech
Синтаксический разбор простого словосочетания
Схема синтаксического разбора простого словосочетания
1. Выделить словосочетание из предложения.
2.Найти главное и зависимое слова, указать, какими частями речи они выражены, поставить вопрос от главного слова к зависимому.
3.Определить тип словосочетания (глагольное, именное или наречное).
4.Определить способ подчинительной связи (согласование, управление, примыкание) и указать, чем она выражена (окончанием зависимого слова, окончанием и предлогом, только по смыслу).
5.Определить смысловые отношения между главным и зависимым словом (определительные, объектные, обстоятельственные).
Образец синтаксического разбора простого словосочетания
Студёный ветер резко рвал полы его шинели (Л. Толстой)
| 1. Студёный ветер х прилаг. + сущ. | именное словосочетание, способ связи — согласование, выражено окончанием зависимого прилагательного, называется предмет и его признак, определительные отношения. |
| 2. Резко рвал — х нареч. + глаг | глагольное словосочетание, способ связи — примыкание, слова связаны по смыслу и интонационно, называется действие и его признак (качество), обстоятельственные отношения. |
| 3. Рвал полы — глаг. +сущ. вВ.п, | глагольное словосочетание, способ связи управление, выражено окончанием зависимого существительного, называется действие и его объект, объектные отношения. |
| 4. Полы шинели — сущ. + сущ. в Р.п | именное словосочетание, способ связи — управление, выражено окончанием зависимого существительного, называется предмет и его признак, определительные отношения. |
Алый свет вечерней зари медленно скользит по корням деревьев (И. Тургенев)
| 1. Алый свет — прилаг. + сущ. | именное словосочетание, способ связи — согласование, выражено окончанием зависимого прилагательного, называется предмет и его признак, определительные отношения. |
2. Свет зари — х Свет зари — хсущ. + сущ. в Р.п. | именное словосочетание, способ связи — управление, выражено окончанием зависимого существительного, называется предмет и его признак, определительные отношения, |
| 3. Медленно скользит • нар. + глаг. | глагольное словосочетание, способ связи — примыкание, слова связаны по смыслу и интонационно, называется действие и его признак (качество), обстоятельственные отношения, |
| 4. Скользит по корням • глаг. + сущ. в Д.п. с предлогом по | глагольное словосочетание, «по», способ связи — управление, выражено окончанием зависимого существительного и предлогом «по», называется действие и его место, обстоятельственные отношения. |
Синтаксический разбор простого предложения. 5-й класс
Слайд 2.
Цели урока.
- Уметь проводить синтаксический разбор простого предложения.
- Конструировать простое предложение по заданной схеме.
Слайд 3.
Организационный момент.
Повторение изученного.
Игра «Кто я?» — инсценировка теории заранее подготовленными учениками.
- Я – главное средство выражения мысли. Имею грамматическую основу и интонацию законченности. Кто я?
- Я – предложение. Содержу рассказ о чём-то, сообщение, информацию. В конце меня ставится точка или восклицательный знак. Кто я?
- Я – предложение. Я заключаю в себе вопрос. В конце меня ставится вопросительный знак. Кто я?
- Я – предложение. Содержу просьбу, приказание, совет, призыв. В конце меня ставится точка или восклицательный знак. Кто я?
- Я – предложение. Выражаю сильные чувства говорящего: радость, огорчение. Как меня называют?
- Я – предложение. Имею 1 грамматическую основу. Как меня называют?
А как называют предложение с 2 грамматическими основами? - Я – предложение. Состою только из главных членов. Как меня называют?
- Я – предложение. Во мне есть не только главные члены, но и второстепенные. Как меня называют?
 Имею 1 грамматическую основу. Как меня называют?
Имею 1 грамматическую основу. Как меня называют?
Слайд 4.
Объяснение нового материала.
Что значит выполнить синтаксический разбор предложения?
- Назвать главные и второстепенные члены предложения, подчеркнуть.
- Указать, какими частями речи они выражены.
- Дать характеристику предложению.
Оформление памятки «Синтаксический разбор предложения».
Слайд 5.
Синтаксический разбор простого предложения.
1. По цели высказывания:
- повествовательное,
- побудительное,
- вопросительное.
2. По эмоциональной окраске:
- восклицательное,
- невосклицательное.
3. По количеству грамматических основ:
- простое,
- сложное.
4. По наличию второстепенных членов:
- распространённое,
- нераспространённое.
Слайд 6.
Работа по теме.
Конструктор. Составьте предложение, выполнив ряд действий. Выполните синтаксический разбор полученного предложения.
Из предложения
взять сказуемое.
Из предложения
взять определение.
Добавить подлежащее из предложения
Взять существительное, выступающее в роли дополнения:
Употребить данное существительное в винительном падеже с предлогом НА.
Опустились лёгкие снежинки на тропинки.
Слайд 7.
Выполните синтаксический разбор предложения из стихотворения М. Ю.Лермонтова. Соответствует ли данное предложение схеме?
Ю.Лермонтова. Соответствует ли данное предложение схеме?
На севере диком стоит одиноко на голой вершине сосна и дремлет…
Слайды 8-10.
Работа с текстом.
Прочитайте выразительно текст о природе нашего края.
1. Природа нашего края – великий врачеватель и утешитель. 2.Приходишь в лес и успокаиваешься, отдыхаешь от суеты и шума. 3. Присядешь на лесной полянке, присмотришься к окружающей тебя красоте и ощутишь приятное прикосновение ветра.4. Как красиво вокруг! 5. Стройными рядами стоят деревья: дуб и берёза, липа и ель, клён и осина.
Слайд 11.
- Как можно озаглавить данный текст?
- Какова основная мысль текста?
- Как вы понимаете значение слова ВРАЧЕВАТЕЛЬ? Какими близкими по значению словами его можно заменить?
- Как вы понимаете значение слова СУЕТА?
- Найдите в предложении №1 слова, в которых звуков больше, чем букв, букв больше, чем звуков.
- В каких словах буква Г обозначает звук В? (№1) Звук К (№4)? Звук Г (№7,8)?
Слайд 12.
- Выполните синтаксический разбор предложения №5.
- Составьте схемы предложений №1, №2, №3, №7
- Найдите в тексте восклицательное предложение, побудительные предложения
- В каких предложениях грамматическая основа состоит только из сказуемого?
Слайд 13.
- Запишите слова. Обозначьте орфограммы.
- Найдите в предложениях
- №2,3 — глаголы с Ь после шипящих
- №8 – слова с приставками, которые не изменяются на письме
- №5 — слова с проверяемой безударной гласной в корне, слова с непроверяемой гласной в корне №7 – слова с непроизносимой согласной в корне слова
Слайды 14-18.
Работа с текстом.
Какого известного русского художника по праву называют певцом русского леса?
Иван Иванович Шишкин – певец русского леса, великий художник. И.И. Шишкин любил изображать хвойный лес. Живописец раскрыл обаяние могучего старого бора, пахнущего мхом и смолой, показал его красоту и величие.
И.И. Шишкин любил изображать хвойный лес. Живописец раскрыл обаяние могучего старого бора, пахнущего мхом и смолой, показал его красоту и величие.
Его большие полотна рассказывали о жизни рощ, дубрав, полей, сосен. Художник безупречно изображал всё: возраст деревьев, их характер, каждую хвоинку и листочек, почву, на которой они растут, обнажённые корни, валуны, пятна солнечного света.
И.Шишкин половину своей долгой и трудолюбивой жизни провёл в любимом сосновом лесу.
Слайды 19-21.
Работа в парах.
Разгадайте ребусы. Подсказка: слова, зашифрованные в ребусах, являются названиями картин И.Шишкина.
Слайд 22-23.
Рассказ по картине.
Рассмотрите картину Шишкина «Зима» и напишите небольшой рассказ по ней или составьте несколько предложений по картине.
Слайд 24.
О каких фразеологизмах напомнили вам картины Шишкина?
Ёлки зелёные – выражение досады, недоумения, восхищения.
Ёлки-палки — выражение досады, недоумения, восхищения.
Заблудиться в трёх соснах – не суметь найти выход из самого простого затруднения.
С бору да с сосенки – кого попало, откуда попало. О случайном подборе, составе людей.
Слайд 25.
Проверочная работа.
Подпиши листок. Выполни синтаксический разбор предложения. Вставь недостающие знаки препинания.
Большие полотна И.Шишкина рассказывали о жизни рощ полей дубрав.
- ___________
- ___________
- ___________
- ___________
Слайды 26-27.
Итоги урока. Домашнее задание.
Что мы узнали сегодня на уроке? Чему научились?
На память об уроке у вас останутся фигурки — ёлочки и солнышки со стихотворением о природе, которое написала ученица 7 класса Жукова Светлана. Выполните синтаксический разбор последнего предложения.
Родная природа.
Голубые речки,
Светлые полянки.
Местная плотина —
Города краса.
На полях цветут ромашки,
Незабудки — у ручья.
Колодец у тропинки,
В нём чистая вода.
А в тенистом парке
Есть заросший пруд.
Хорошо тут летом
Соловьи поют!
Желающие могут написать своё стихотворение о природе.
в каких заданиях ЦТ он пригодится?
Повторяя правила по теме «Синтаксис и пунктуация», важно не забыть про ещё один важный момент — алгоритм синтаксического разбора. В этой статье напомним, как анализировать предложения и в каких заданиях ЦТ по русскому и белорусскому языкам понадобятся эти знания.
Алгоритм синтаксического разбора простого предложения
Любой разбор предложения начинается со стандартной процедуры: определения его типа по цели высказывания (повествовательное, побудительное, вопросительное) и по эмоциональной окраске (восклицательное и невосклицательное). Кстати, заметь, что расстановка знаков препинания иногда зависит от этих характеристик. Затем стоит определить грамматическую основу (найти подлежащее и сказуемое), чтобы уж точно знать: перед тобой простое либо сложное предложение.
Затем нужно определить тип предложения по структуре (строению). Для простого предложения будут такие варианты:
— двусоставное (если есть подлежащее и сказуемое) либо односоставное (определённо-личное, неопределённо-личное, обобщённо-личное, безличное или назывное).
— распространённое (есть второстепенные члены — определение, обстоятельство, дополнение) или нераспространённое (таковых нет).
— полное или неполное (когда член предложения пропущен).
— осложнено однородными членами или обособленными членами, обращениями, вводными словами.
Затем предложение разбирают по членам, указывают, чем они выражены и составляют схему. Если забыл, как это делается, смотри картинку ниже, либо загляни в учебник по русскому или белорусскому языкам.
Эти знания понадобятся тебе для того, чтобы корректно ставить знаки препинания в простых предложениях, отличать их от сложных и правильно решить задания А13-А16, А20 в ЦТ по русскому языку. И особенно в задании В10, где необходимо установить соответствие между предложениями и их схемами.
Для тых, хто здае ЦТ па беларускай мове, дзейнічае той жа алгарытм сінтаксічнага разбору простага сказа. І гэтыя веды спатрэбяцца ў заданнях А17, А18, А19, А20, А21, А22, А23.
Итоговые занятия перед ЦТ 2020 Адукар: +20 баллов за 4 часа!Крутая возможность для абитуриентов 2020 года! С 12 по 27 июня Адукар проводит итоговые занятия перед ЦТ по 9 предметам. Это реальный шанс повторить весь материал за 4 часа и улучшить свой балл на ЦТ! Успей записаться по скидке!Узнать больше и записаться!
Алгоритм синтаксического разбора сложного предложения
Синтаксический разбор сложного предложения базируется на знаниях о простом. Также необходимо определить тип предложения по цели высказывания и интонации, а затем найти грамматические основы. Понятно, что если в состав входят две и более предикативные части, то перед нами сложное предложение. Затем стоит определить, с помощью чего связаны части: союзов, союзных слов или интонации. Это поможет тебе понять, какое перед тобой предложение (сложносочиненное, сложноподчиненное, бессоюзное, предложение с разными видами связи).
Помни, что части сочинительных предложений связаны с помощью соединительных (и, да, ни, тоже, также), разделительных (или, либо, то … то, не то … не то) и противительных союзов (а, но, однако, зато, же). А в сложноподчинённом предложении ты найдёшь подчинительные союзы (чтобы, если, как, несмотря на то что и так далее), союзные слова (который, чей, какой, что; где, куда), соотносительные слова (тот…кто, тот… который, тот… чей, там… где, там… куда). И понятно, что интонационно связываются части бессоюзного предложения. А предложения с разными видами связи комбинируются из вышеперечисленных предложений. Такой анализ позволит без проблем составить схему.
И понятно, что интонационно связываются части бессоюзного предложения. А предложения с разными видами связи комбинируются из вышеперечисленных предложений. Такой анализ позволит без проблем составить схему.
Повторить всю теорию по теме «Сложные предложения» ты можешь с помощью видеоурока Адукар. Больше роликов смотри на YouTube-канале
Эти знания тебе пригодятся для решения заданий ЦТ по русскому А17-А18, А21, В10. Таксама з гэтымі ведамі ты без праблем выканаеш заданні А24-А27 у ЦТ па беларускай мове.
Как видишь, ты можешь использовать синтаксический разбор как обобщение, повторение материала по всей теме «Синтаксис и пунктуация». Поэтому если тебе трудно даются все вышеперечисленные задания из ЦТ, не ленись повторить правила. Потому что в ЦТ по русскому языку 12 заданий из 40 по этому разделу. А в ЦТ по белорусскому языку — 13 заданий из 40. Как видишь, немалая часть. Правильно выполним их все, ты сможешь заработать много баллов. Удачной подготовки!
Спасибо, что дочитал до конца. Мы рады, что были полезны. Чтобы получить больше информации, посмотри ещё:
Тесты в ЦТ онлайн
Как проходит онлайн-обучение в Адукаре
С 12 по 27 июня пройдут итоговые занятия перед ЦТ 2020 Адукар: +20 баллов за 4 часа!
Не пропускай важные новости и подписывайся на наш YouTube, ВК, Instagram, Telegram, Facebook и уведомления на adukar.by.
***
Если хотите разместить этот текст на своём сайте или в социальной сети, свяжись с нами по адресу [email protected]. Перепечатка материалов возможна только с письменного согласия редакции.
Краткосрочный план синтаксический разбор простого предложения.
 Синтаксический разбор предложения
Синтаксический разбор предложения
Краткосрочный план урока
Предмет
Класс
Дата
Тема
Общие цели
Результаты обучения
Результаты обучения для
учеников (А)
Результаты обучения для
учеников (В)
Результаты обучения для
учеников (С)
Ключевые идеи
Ссылки
Реквизиты(ресурсы)
Этапы (Время)
Начало занятия
(3 минут)
Русский язык
6 «А»
5.05.2016 г.
Синтаксический разбор сложного предложения
Знать синтаксический разбор сложного предложения. Уметь делать синтаксический разбор сложного предложения.
Знают и умеют делать синтаксический разбор сложного предложения.
Знают и умеют делать синтаксический разбор сложного предложения. Умеют самостоятельно анализировать, синтезировать и сравнивать
простые предложения в составе сложного предложения..
Знают и умеют делать синтаксический разбор сложного предложения. Умеют устно и письменно выполнять синтаксический разбор.
Знают и умеют делать синтаксический разбор сложного предложения.
Развивать связную речь, память и мышление.
ГОСО, учебная программа, учебник.
Таблицы, бумага формата А4, карточки с заданиями, стикеры, постер,разные канцелярские товары необходимые для творческой работы
учащихся.
Действия учителя
Действия учеников
Оценивание
Ход урока
1.Приветствие
2.Психологический настрой. Треннинг:
«Приветствие».
1.Приветствуют учителя
2.Ходят по классу, здороваются друг с другом
за руки: «Здравствуй», «Привет», «Как твои
дела?» и т.д. Хвалят, говорят друг другу
комплименты.
Словесное поощрение
учителем.
Проверка домашнего задания
(7 минут)
Упр. 10
Прием «Толстые и тонкие вопросы» вопросы по
пройденным материалам.
Дети отвечают
Введение в тему
(8 минут)
Реализация цели занятия (8
Разберите эти предложения по членам:
Дети делают разбор по членам предложения
1.Белый пар по лугам расстилается.
2.В зеркало залива сонный лес глядит, в чаще
молчаливой темнота лежит.
Порядок разбора:
Словесное поощрение
учителем.
Словесное поощрение
учителем. Дети читают и делают синтаксический разбор
сложного предложения.
Формативное оценивание
«Большой палец»
минут)
1. Вид предложения по цели высказывания.
Вид предложения по цели высказывания.
2. Является ли предложение восклицательным.
3. Простое или сложное предложение.
Простое предложение:
4. Распространённое или нераспространённое.
5. Главные и второстепенные члены предложения.
6. Однородные члены предложения (если они есть).
7. Обращение (если оно есть).
Сложное предложение:
4. Части сложного предложения, их основы.
5. С помощью союзов или без союзов соединены части
сложного предложения.
Образец письменного разбора предложения
простого:
Белый пар по лугам расстилается.
(И. С. Никитин.)
сложного:
В зеркало залива сонный лес глядит, в чаще
молчаливой темнота лежит. Физминутка
(3 минуты)
Реализация цели занятия (15
минут)
(И. С. Никитин.)
Разминка
1. Первое и третье предложения разберите письменно,
остальные устно.
1. Солнце стояло ни..ко на бледноясн..м небе. 2. От
деревьев, от кустов, от высоких стогов сена побежали1
длинные тени. 3. Солнце уже довольно высоко ст..яло
на чист..м небе, но поля ещё бл..стели росой. 4. Сырая
земля упруга под ногами, высокие сухие былинки не
шевелятся, длинные нити блестят на побледневшей
траве.
(И. С. Тургенев.)
Обозначьте звуки на месте выделенных букв.
2. Спишите, расставляя пропущенные запятые.
Разберите письменно предложения. Сделайте
синтаксический разбор предложения.
1. Мы входим ост..рожно в лес ранн..м утром. 2. От
земли поднима..тся лё..кая дымка тумана а на каждой
иголк.. сосны на каждом листочк.. б..рёзы на каждой
травинк.. кие др..жат маленькие и нежны.. капельки
воды.
Домашнее задание
(1 минута)
Рефлексия
(2 минут)
Д/З упр. по выбору.
Дети записывают в дневники
Что вам понравился?
Какие у тебя есть вопросы по новой теме?
Дети отвечают
Формативное оценивание
План — конспект урока по теме: «
Синтаксический разбор простого предложения » в 5 «А» кл.
Цели урока:
- научить правильно выполнять синтаксический разбор простого предложения;
- закрепить знание классификаций предложений по цели высказывания, интонации, наличию главных и второстепенных членов предложения;
- проверить умение ставить знаки препинания при однородных членах предложения, обращении.
Оборудование:
листочки с заданиями, учебник, Толковый словарь.
Ход урока.
- Оргмомент.
- Проверка домашнего задания.
На прошлом уроке вы учились писать дружеское письмо. Сегодня мы послушаем ваши письма, которые вы адресовали своим друзьям. (чтение 1-2 писем)
А какие ещё виды писем вы знаете?
Молодцы, вы справились с домашним заданием. (В конце урока нужно сдать письма на проверку)
3. Словарный диктант.
(1 ученик)
.
Цветочный аромат,косматые дожди, потемнеть от сырости, наслаждаться пейзажем ( определить способ связи словосочетаний
)
(2
ученик
) бегущая вдоль реки тропинка, одинокие золотые березки,серьёзная опасность, удивительный урожай моркови и капусты.( выполнить морфемный разбор слов:
одинокие, удивительные;
написать слово
: бегущая
в транскрипции.)
4
Орфоэпическая минутка.
.
Задание записано заранее на доске(выходит ученик и ставит ударение в словах, весь класс делает запись в словарик)
Квартал,щавель,банты, звонишь,торты,свитер, углубить, упростить.
5 Физминутка.( проводит ученица 5 кл)
Яблоня в моём саду
Гнётся сильно на ветру.
Наклонилась вправо, влево,
Покачаться захотела: 1, 2, 3, 4, 5.
Ветки вниз и вверх опять!
И вперёд их протянула.
А как стихнет ветерок,
Моя яблонька уснёт.
6
Фронтальный опрос
Игра «Кто быстрее»
- — Назовите предложения по цели высказывания (Повествовательное, побудительное, вопросительное)
В побудительном предложении содержится
совет, просьба, приказ, пожелание. (пример)
—
В повествовательном предложении содержится
сообщение.(пример)
—
В вопросительном предложении содержится
вопрос.(пример)
Предложение по эмоциональной окраске может быть
восклицательным и невосклицательным
Подлежащее и сказуемое- это
грамматическая основа.
- — По наличию грамматических основ предложения бывают —
односоставными и двусоставными.
—
По наличию второстепенных чл. предложения
-распространённые и нераспространённые. (пример)
7
. Объяснение нового материала.
- —
Тема нашего урока «Синтаксический разбор простого предложения».
Ребята, попытаемся сформулировать цели нашего урока, опираясь на тему. (Дети самостоятельно определяют цели урока)
Ребята, дайте определение простого предложения.
А какое вы ещё знаете предложение по наличию грамматической основы? Чем сложное предложение отличается от простого?)
—
Давайте вспомним этапы проведения синтаксического разбора предложения. Откройте учебники на с. 89 пар. 44
- Закрепление материала.
1 задание
(На доске заранее крепятся в виде осенних листочков карточки с заданием)
А теперь, ребята, представьте, что мы в лесу и нам нужно собрать листья для гербария.
Ребята, а что такое гербарий? (один из учеников самостоятельно смотрит Л.З. слова «Толковый словарь» С.И. Ожегов, зачитывает вслух.)
Но это необычные листочки, а с заданием по орфографии и пунктуации.
(4 ученика выходят к доске, снимают листочки и выполняют самостоятельно).
Только один ученик берёт листочек и выполняет задание вместе с классом. (Нужно вставить пропущенные буквы, расставить знаки препинания и выполнить синтаксический разбор предложения)
1 Берег п…крывали к…мыши и осока.
2 В саду растут и вишни и ябл…ни и груши.
3 Дуб теплолюбивое дерево.
4 Со…нце светит но (не) греет.
5 Ребята берегите природу!
После выполнения ученики у доски осуществляют взаимопроверку.
2 задание. (На доске заранее написаны отдельные слова. Нужно ученикам так переставить слова, чтобы получились предложения, затем их разобрать.)
Два ученика выполняют это задание у доски, остальные самостоятельно в тетрадях.
Маленькие рыжики, на еловом, белочка, сучке, подосиновики, сушить, развесила.(На еловом сучке белочка развесила сушить подосиновики, маленькие рыжики.)
Снег, выпадет, землю, глубокий, накроет, и, покрывалом белым.(Выпадет глубокий снег и накроет землю белым покрывалом.)
9.
Подведение итога.
- Учащиеся подводят итог урока.
Учитель комментирует работу в классе, выставляет оценки.
10. Домашнее задание.
Выучить порядок синтаксического разбора параграф 44, упр 217.
Тема урока: Синтаксический разбор простого предложения
Цели:
1) познакомить с порядком синтаксического разбора
простого предложения;
2) формировать умение производить синтаксический
разбор (устный и письменный) простого предложения;
3) активизация умений излагать свои мысли чётко и лаконично;
4)воспитание внимания к слову через конструирование
предложений;
5) повторение изученного материала по теме «Синтаксис», частей речи, изученных орфограмм, пунктограмм;
6)
формировать представление о здоровье как одной из главных
ценностей человеческой жизни.
Приёмы ТРКМ
: 1. Приём « Верные — неверные утверждения»
3. Приём «Тонкие и толстые вопросы»
4.Приём «Лови ошибку»
5.Приём «Найди соответствия»
6.Кластер
Форма работы
: 1.Фронтальная
2. Индивидуальная
3. Парная
Ход урока.
1. Орг. момент
.
Здравствуйте, я рада приветствовать вас на уроке русского языка.
Давайте, друзья, улыбнемся друг другу,
улыбки подарим гостям,
к уроку готовы?
Тогда за работу, удачи желаю я вам!
Молодцы! Все улыбнулись! А вы знаете, что улыбка-это лучшая таблетка для здоровья?
У вас на партах лежат смайлики, они вам тоже будут улыбаться и помогать поддерживать хорошее настроение на уроке.
Возьмите смайлик в руку и поднимите вверх.
Пусть на уроке вам сопутствует успех!
Запишите число, классная работа.
2.Стадия вызова. Актуализация знаний.
А сейчас, ребята, мы с вами поиграем в игру « Веришь ли ты?» Эта игра нам поможет выяснить, что вы знаете, а чего не знаете.
Я буду задавать тонкие вопросы, на которые вы мне будете отвечать только «да» или «нет», и толстые вопросы, на которые надо ответить подробно.
Приём «Верные и неверные утверждения», « Тонкие и толстые вопросы»
Верите ли вы, что предложения по эмоциональной окраске бывают восклицательные и невосклицательные? (да)
Верите ли вы, что предложения по цели высказывания бывают распространённые и нераспространённые? (нет) А какие они бывают? (повествовательные, побудительные, вопросительные)
Верите ли вы, что в простых предложениях одна грамматическая основа, а в сложных – две и более грамматических основ? (да)
Верите ли вы, что дополнение, обстоятельство и определение – это главные члены предложения? (нет) А какие члены предложения являются главными? (подлежащее и сказуемое)
Ребята, скажите мне, пожалуйста, а на какую тему я вам задавала вопросы? (предложение)
Какой раздел науки о языке изучает предложение? (Синтаксис)
А вы знаете, ребята, как называется разбор предложения по членам?
Чему мы должны научиться на уроке? (Синтаксическому разбору
простого предложения.)
Запишите, пожалуйста, тему урока в тетрадь.
Кроме того мы должны повторить и обобщить знания по теме «Синтаксис».
А помогут нам в этом загадки, пословицы, поговорки и тексты о здоровом образе жизни. Проходить наш урок будет под девизом: « Здоровым будешь- всё добудешь». Как вы понимаете эту пословицу, ребята? (если будешь здоровым, не будешь болеть, то сможешь учиться, работать, и всё у тебя будет)
3. Словарно- орфографическая работа.
А сейчас мы с вами поиграем в «Орфографический футбол». Я вам буду загадывать загадки, а вы запишете ответы через запятую. Будьте внимательны, не пропускайте гол в свои ворота, т.е. не допускайте ошибок.
1.
Зеленый луг,
Сто скамеечек вокруг,
От ворот до ворот
Бойко бегает народ.
На воротах этих —
Рыбацкие сети.
(стадион)
2.
— Не пойму, ребята, кто вы?
Птицеловы? Рыболовы?
Что за невод во дворе?
— Не мешал бы ты игре,
Ты бы лучше отошел!
Мы играем в…(волейбол)
3. Этот конь не ест овса,
Вместо ног — два колеса.
Сядь верхом и мчись на нем,
Только лучше правь рулем. (велосипед)
4.
Лента, мяч, бревно и брусья,
Кольца с ними рядом.
Перечислить не берусь я
Множество снарядов.
Красоту и пластику
Дарит нам… (гимнастика)
5
.
В этом спорте игроки
Все ловки и высоки.
Любят в мяч они играть
И в кольцо его кидать.
Мячик звонко бьет об пол,
Значит, это… (баскетбол)
6
.
В честной драке я не струшу,
Защищу двоих сестер.
Бью на тренировке грушу,
Потому что я… (боксер)
7
.
Вот спортсмены на коньках
Упражняются в прыжках.
И сверкает лед искристо.
Те спортсмены — … (фигуристы)
8. И мальчишки, и девчонки
Очень любят нас зимой,
Режут лед узором тонким,
Не хотят идти домой.
Мы изящны и легки,
Мы — фигурные… (коньки)
Взаимопроверка.
Я надеюсь, вы не пропустили ни одного гола в свои ворота.
— Ребята!
На какую орфограмму мы написали слова?(непроверяемые гласные и согласные в корне слова) А какие слова лишние? К каким словам можно подобрать проверочное слово? (боксёр, коньки) А какой общей темой объединены эти слова? (спорт) Какую роль он играет для здоровья человека?
Что необходимо делать, чтобы прожить здоровым и счастливым много лет? (правильно, заниматься спортом) Запишите предложение
Мы будем чаще закаляться, спортом заниматься!
4.Объяснение нового материала.
Составление кластера.
Синтаксический разбор записанного предложения. Характеристика предложения.
(Побудительное, восклицательное, простое, двусоставное, распространённое, осложнено однородными сказуемыми) Построение схемы.
5.Части речи
А теперь проверим, как вы знаете части речи, ведь предложения и словосочетания состоят из слов, выраженных разными частями речи.
У какого слова неправильно определена часть речи?
1) Оздоравливает – глагол в форме настоящего времени;
2) И- предлог
3) Хороший – имя прилагательное;
4) Смех – имя существительное. Ответ: 2
6. Отправляемся на поиск предложений. Работа в парах.
У вас на партах лежат листочки со схемами. А на слайде вы видите предложения. Найдите предложение к своей схеме.
1. Мы растём смелыми, на солнце загорелыми.
2. От простуды и ангины вам помогут витамины.
3. Зарядку делай каждый день, пройдёт усталость, вялость, лень!
4. Будем закаляться, спортом заниматься!
5. Ты любишь играть в футбол?
6. Воздух, солнце и вода –наши лучшие друзья.
Запишите найденные предложения и произведите синтаксический разбор. У доски 1 человек (напарник делает в тетради, а потом проверяет у доски)
7. Работа в парах.
У вас на партах есть конверты, откройте их и составьте из слов предложения так, чтобы получились пословицы и поговорки о здоровом образе жизни. Работаем в парах (1 предложение на стол)
1.
Аппетит от больного бежит, а к здоровому катится.
2. Быстрого и ловкого болезнь не догонит.
3.Здоровье дороже богатства.
4. Чистота — залог здоровья.
5.Здоровый сон – прекрасное самочувствие днём.
6. Хороший смех оздоравливает душу.
Запишите получившиеся предложения и разберите синтаксически. У доски 1 человек работает по карточке –разбор слов по составу: чистота, зарядка.
8. Физкультминутка
Сейчас мы с вами проведѐ
м физкультминутку. Поскольку сегодня мы повторяем изученный материал из синтаксиса, то разминка будет связана со знанием терминологии, которую мы используем.
Правила игры.
Ученики встают со своих мест, руки на поясе. Учитель называет различные термины. Если термины относятся к синтаксису, поднять руки вверх, если же к другим разделам языка – опустить руки вниз.
Приставка, грамматическая основа, словосочетание, корень, основа слова, запятая, обстоятельство, тире, суффикс, предложение, обращение, буква.
9. Приём «Лови ошибку»
Исправить ошибки в употреблении слов в данных предложениях.
У Пети смех заразный. Грипп – болезнь заразительная.
Запишите предложения в исправленном виде. Объясните постановку тире во 2 предложении.
10. На наше здоровье влияет и наш рацион. Исключите из ежедневного меню макароны, плюшки, конфеты, а оставьте как можно больше овощей и фруктов. Послушайте, что говорится в одном их стихотворений? Выразительное чтение стихотворения.
Чудо-огород.
Удивляется народ:
Что за чудо-огород?
Здесь редис есть и салат,
Лук, петрушка и шпинат.
Помидоры, огурцы
Зреют дружно — молодцы!
И картофель, и капуста
Растут на грядках густо-густо.
И все дружно говорят:
«Мы растём здесь для ребят.
За усердие и труд
Урожай весь соберут».
Почему нужно есть как можно больше фруктов и овощей, ребята?
Задания: 1) найдите предложения, осложнённые однородными членами предложения;
2) Составьте простое предложение с однородными членами и обобщающим словом. На огороде растут овощи: редис, салат, капуста, помидоры.
2) начертите схему
3. Стадия «Рефлексия»
11. Работа с текстом.
Прочитайте, вставьте пропущенные буквы, расставьте знаки препинания. Произведите синтаксический разбор одного предложения. (Звучит спокойная музыка, звуки живой природы).
1.
Музыка лечит.
Музыку любят все. Х…рошая музыка улучшает настр…ение 4 . А пл…хая музыка разрушает нервную систему ч…ловека.
От х…рошей музыки даже р…стения быстрее р…стут. От плохой музыки они могут засохнуть, п…гибнуть.
2.
Спокойная музыка ра(с,сс)л…бляет, снимает пс…хическое напр…жение. Она сочетает в себе успокаивающие звуки ж…вой природы: журч…ние ручейка, шум моря, г…лоса птиц. Она возвращ…ет душевное равновесие и хорошее настр…ение.
Или дать тест? Или 1 ряду текст, в 2 ряду – тест?
Наш урок подходит к концу, вы сегодня все очень хорошо поработали. Молодцы! На память о нашем уроке у вас останутся смайлики, на обратной стороне которых вы найдёте мои пожелания вам.
Урок окончен, всем спасибо!
Синтаксический разбор простого предложения прочно вошёл в практику начальной и средней школы. Это самый трудный и объёмный вид грамматического разбора. Он включает характеристику и схему предложения, разбор по членам с указанием частей речи.
Строение и значение простого предложения изучается начиная с 5 класса. Полный набор признаков простого предложения обозначается в 8 классе, а в 9 классе основное внимание уделяется сложным предложениям.
В этом виде разбора соотносятся уровни морфологии и синтаксиса: ученик должен уметь определять части речи, узнавать их формы, находить союзы, понимать способы связи слов в словосочетании, знать признаки главных и второстепенных членов предложения.
Начнём с самого простого: поможем ребятам подготовиться к выполнению синтаксического разбора в 5 классе. В начальной школе ученик запоминает последовательность разбора и выполняет его на элементарном уровне, указывая грамматическую основу, синтаксические связи между словами, вид предложения по составу и цели высказывания, учится составлять схемы и находить однородные члены.
В начальной школе используются разные программы по русскому языку, поэтому уровень требований и подготовка учащихся разные. В пятом классе я принимала детей, обучавшихся в начальной школе по программам образовательной системы «Школа 2100», «Школа России» и «Начальная школа XXI века». Отличия есть и большие. Учителя начальной школы проделывают колоссальную работу, чтобы компенсировать недостатки своих учебников, и сами «прокладывают» преемственные связи между начальной и средней школой.
В 5 классе материал по разбору предложения обобщается, расширяется и выстраивается в более полную форму, в 6-7 классах совершенствуется с учётом вновь изученных морфологических единиц (глагольные формы: причастие и деепричастие; наречие и категория состояния; служебные слова: предлоги, союзы и частицы).
Покажем на примерах отличия между уровнем требований в формате синтаксического разбора.
В 4 классе | В 5 классе |
В простом предложении выделяется грамматическая основа, над словами обозначаются знакомые части речи, подчёркиваются однородные члены, выписываются словосочетания или рисуются синтаксические связи между словами. Схема: [О -, О]. Повествовательное, невосклицательное, простое, распространённое, с однородными сказуемыми. Сущ.(главное слово)+прил., Гл.(главное слово)+сущ. Гл.(главное слово)+мест. Нареч.+гл.(главное слово) | Синтаксические связи не рисуются, словосочетания не выписываются, схема и основные обозначения такие же, но характеристика иная: повествовательное, невосклицательное, простое, двусоставное, распространённое, осложнено однородными сказуемыми. Разбор постоянно отрабатывается на уроках и участвует в грамматических заданиях контрольных диктантов. |
В сложном предложении подчёркиваются грамматические основы, нумеруются части, над словами подписываются знакомые части речи, указывается вид по цели высказывания и эмоциональной окраске, по составу и наличию второстепенных членов. Схема разбора: [О и О] 1 , 2 , и 3 . Повествовательное, невосклицательное, сложное, распространённое. | Схема остаётся той же, но характеристика иная: повествовательное, невосклицательное, сложное, состоит из 3 частей, которые связаны бессоюзной и союзной связью, в 1 части есть однородные члены, все части двусоставные и распространённые. Разбор сложного предложения в 5 классе носит обучающий характер и не является средством контроля. |
Схемы предложения с прямой речью: А: «П!» или «П,» — а. Вводится понятие цитаты, совпадающее по оформлению с прямой речью. | Схемы дополняются разрывом прямой речи словами автора: «П, — а. — П.» и «П, — а, — п». Вводится понятие диалога и способы его оформления. Схемы составляют, но характеристика предложений с прямой речью не производится. |
План разбора простого предложения
1. Определить вид предложения по цели высказывания (повествовательное, вопросительное, побудительное).
2. Выяснить тип предложения по эмоциональной окраске (невосклицательное или восклицательное).
3. Найти грамматическую основу предложения, подчеркнуть её и обозначить способы выражения, указать, что предложение простое.
4. Определить состав главных членов предложения (двусоставное или односоставное).
5. Определить наличие второстепенных членов (распространённое или нераспространённое).
6. Подчеркнуть второстепенные члены предложения, указать способы их выражения (части речи): из состава подлежащего и состава сказуемого.
7. Определить наличие пропущенных членов предложения (полное или неполное).
8. Определить наличие осложнения (осложнено или не осложнено).
9. Записать характеристику предложения.
10. Составить схему предложения.
Для анализа мы использовали предложения из прекрасных сказок Сергея Козлова про Ёжика и Медвежонка.
1) Это был необыкновенный осенний день!
2) Обязанность каждого — трудиться.
3) Тридцать комариков выбежали на поляну и заиграли на своих писклявых скрипках.
4) У него нет ни папы, ни мамы, ни Ёжика, ни Медвежонка.
5) И Белка взяла орешков и чашку и поспешила следом.
6) И они сложили в корзину вещи: грибы, мёд, чайник, чашки — и пошли к реке.
7) И сосновые иголки, и еловые шишки, и даже паутина — все распрямились, заулыбались и затянули изо всех сил последнюю осеннюю песню травы.
8) Ёжик лежал, по самый нос укрытый одеялом, и глядел на Медвежонка тихими глазами.
9) Ёжик сидел на горке под сосной и смотрел на освещённую лунным светом долину, затопленную туманом.
10) За рекой, полыхая осинами, темнел лес.
11) Так до самого вечера они бегали, прыгали, сигали с обрыва и орали во всё горло, оттеняя неподвижность и тишину осеннего леса.
12) И он прыгнул, как настоящий кенгуру.
13) Вода, куда ты бежишь?
14) Может, он с ума сошёл?
15) Мне кажется, он вообразил себя… ветром.
Образцы разбора простых предложений
Утверждаю:
Директор КГУ «Свободненская СШ»
Н. А. Меркер _____________
Ососкова Анастасия Игоревна 2 категория 3(базовый уровень)
предмет
Русский язык
класс
5 «Б»
дата
14.11.2016
Тема урока
Синтаксический разбор простого предложения.
Цель
Сформировать у учащихся понятия разбор по членам предложения
Задачи
Организовать деятельность учащихся по усвоению нового материала;
Развитие умения выделять
главные и
второстепенные члены предложения;
Развитие диалогической речи, умение синтезировать, сопоставлять, анализировать, самостоятельно делать выводы.
Методы
Мозговая атака, заполнение таблицы и схем к предложениям, разбор предложений, логические задания.
Интегрирование семи модулей
КМ, диалогическое обучение, управление и лидерство
в обучении, ОО, работа с одаренными учащимися.
Ожидаемый результат
Учащиеся:
Умеют находить главные и второстепенные члены предложения, ставить к ним вопросы, графически выделять их на письме;
-умеют составлять простые предложения.
Оборудование,
наглядность
Маркеры, бумага формата А-4, стикеры, постер,разные канцелярские товары необходимые для творческой работы учащихся.
Ход урока
Деятельность учителя
Деятельность учащихся
Орг. момент.
1.Приветствие
2.Психологический настрой. Треннинг: «Приветствие».
1.Приветствуют учителя
2.Ходят по классу, здороваются друг с другом за руки: «Здравствуй», «Привет», «Как твои дела?» и т.д. Хвалят, говорят друг другу комплименты.
Мозговая атака.
Опрос д/з.
І. Побуждение
Мотивация
Применение.
Выполнение заданий.
Творческая минутка.
Рефлексия.
Оценивание
Домашнее задание.
Сегодня, ребята, у нас необычный день. Мы идем путешествовать в страну «Синтаксис». Чтобы начать наше путешествие мы должны ответить на один вопрос:
Что такое синтаксис?
Молодцы, теперь у нас открыта дорога и мы можем начать наше путешествие. Но перед тем, как
начать наше путешествие давайте разделимся на группы.
Я раздам вам оценочные бланки, куда вы будете выставлять себе оценки за каждый этап урока.
1 остановка.
Ответы на вопросы
.
Назови главные члены предложения.
Что такое подлежащее?
Что такое сказуемое?
Назови второстепенные члены предложения.
Что такое дополнение?
Что такое определение?
Что такое обстоятельство?
2 остановка
.
Заполните таблицу
3 остановка.
Главные члены предложения.
Прочитайте предложения. Найдите главные члены предложения.
4 остановка. Второстепенные члены предложения.
Прочитайте текст. Выпишите первое предложение. Подчеркните второстепенные члены предложения.
Делают зарисовки к этому тексту.
5 остановка. Разминка.
Физкультминутка.
6 остановка. Разбор предложений.
Прочитайте предложения и сделайте разбор по членам предложения.
7 остановка. Заполните схемы.
Заполните схемы к предложениям из 6 остановки.
8 остановка. Пословица – народная мудрость.
Дополните пословицы.
9 остановка. Что знаем, повторяем.
МИНИ ТЕСТ
10 остановка. Конечная.
Моё настроение.
Ребята, о чем мы с вами говорили на уроке? Понравился урок? Напишите ваше мнение об уроке (слайд 32).
По оценочным бланкам выставляются оценки.
Написать небольшой рассказ о том, как прошел урок. Выписать одно предложение и разобрать по членам предложения.
Синтаксис – это раздел науки о языке, который изучает словосочетания и предложения.
По названиям фруктов делятся на группы. Затем сами рисуют эти фрукты.
Ответы учащихся.(кто первый поднимет руку)
Заполняют готовую таблицу.
1.Прозвенел звонок. 2. Школьники вошли. 3. Учитель поздоровался.(устно)
Выполняют все три группы.
Весной школьники сажают плодовые деревья.
Письменная работа.
1группа: Наступила дружная весна.
2группа:С юга подул тёплый ветер.
3группа: Весна окрасила деревья в зелёный цвет.
Раздаются схемы предложений.
Подбирают подходящие по смыслу слова и говорят каким членом предложения они являются.
Читают предложения и находят главные и второстепенные члены предложения.
Выбирают «смайлик».
Выполняют тест проверяют по ключу. Выставляют оценки.
Записывают
Поделитесь статьей с друзьями:
Похожие статьи
Определение синтаксического анализа Merriam-Webster
\ ˈPärs
, в основном британский ˈpärz \
переходный глагол
1а
: для разделения (предложения) на грамматические части и определения частей и их отношения друг к другу.
б
: для описания (слова) грамматически путем указания части речи и объяснения интонации (см. Значение словоизменения 2a) и синтаксических отношений.
2
: для мелкого анализа : для критического анализа
проблема при синтаксическом анализе … объяснения сокращающихся рыночных долей — Р.С. Энсон
непереходный глагол
1
: для грамматического описания слова или группы слов.
2
: , чтобы признать анализ
: продукт или экземпляр синтаксического анализа
Как анализировать данные в Excel (разделить столбец на несколько)
Excel: как анализировать данные (разделить столбец на несколько)
В Excel (2016, 2013, 2010) можно анализировать данные из одного столбца на два или более столбца.И вы можете сделать это за несколько простых шагов. Предположим, что столбец A содержит «Фамилия, имя». Выполните следующие действия, чтобы разделить данные из столбца A на столбец «Фамилия» и столбец «Имя». Нет необходимости в резке и вставке!
Откройте электронную таблицу Excel, содержащую данные, которые вы хотите разделить, затем:
- Выделите столбец, содержащий объединенные данные (например, фамилию, имя), щелкнув букву непосредственно над столбцом.
- Щелкните вкладку «Данные» на ленте, затем найдите группу «Инструменты для работы с данными» и щелкните «Текст в столбцы».Появится «Мастер преобразования текста в столбцы».
- На шаге 1 мастера выберите «С разделителями»> щелкните [Далее].
- Разделитель — это символ или пробел, разделяющий данные, которые вы хотите разделить. Например, если в вашем столбце написано «Смит, Джон», вы должны выбрать «Запятая» в качестве разделителя. Выберите разделитель в ваших данных.
- Установите флажок «Обрабатывать последовательные разделители как один».
- Щелкните [Далее].
- В разделе «Формат данных столбца» выберите «Общие».«
- Щелкните красную стрелку / значок электронной таблицы в дальнем правом углу текстового поля «Место назначения».
- Выделите столбцы, которые вы хотите содержать разделенные данные, щелкнув буквы прямо над столбцами (вы можете выбрать столбцы из любого места в электронной таблице). Или вручную щелкните и перетащите, чтобы выбрать продажи, которые вы хотите содержать разделенные данные.
- Щелкните значок красной стрелки / электронной таблицы еще раз, чтобы вернуться к мастеру.
- Щелкните [Готово].
Примечание:
Если данные, которые вы хотите разделить, НЕ содержат разделителя (тире, запятой, табуляции и т. Д.) Для разделения данных, выберите «Фиксированная ширина» на первом шаге мастера «Преобразовать текст в столбец». . Эта опция позволяет вам вручную создавать подразделения в ваших данных, перетаскивая линию разрыва.
Ключевые слова: разделение столбцов, анализ данных, разделение ячейки, отдельная информация
Опубликовано в
Компьютерная помощь
новый оператор — Что такое парсинг в терминах, понятных новому программисту?
Что такое парсинг?
В информатике синтаксический анализ — это процесс анализа текста, чтобы определить, принадлежит ли он определенному языку или нет (т.n (что означает такое же количество символов A, за которым следует такое же количество символов B). Синтаксический анализатор для этого языка примет ввод AABB и отклонит ввод AAAB . Это то, что делает парсер.
Кроме того, во время этого процесса может быть создана структура данных для дальнейшей обработки. В моем предыдущем примере он мог, например, хранить AA и BB в двух отдельных стеках.
Все, что происходит после этого, например, придание значения AA или BB или преобразование его во что-то еще, не является синтаксическим анализом.Придание значения частям входной последовательности токенов называется семантическим анализом.
Что не разбирает?
- Парсинг не превращает одно в другое. Преобразование A в B, по сути, то, что делает компилятор. Компиляция занимает несколько шагов, синтаксический анализ — только один из них.
- При синтаксическом анализе текст не извлекается. Это семантический анализ, этап процесса компиляции.
Как это проще всего понять?
Я думаю, что лучший способ понять концепцию синтаксического анализа — это начать с более простых концепций.Самым простым по предмету языковой обработки является конечный автомат. Это формализм для синтаксического анализа регулярных языков, таких как регулярные выражения.
Это очень просто, у вас есть вход, набор состояний и набор переходов. Рассмотрим следующий язык, построенный на алфавите {A, B} , L = {w | w начинается с «AA» или «BB» в качестве подстроки} . Автомат ниже представляет возможный синтаксический анализатор для этого языка, все допустимые слова которого начинаются с «AA» или «BB».
А -> (q1) - А -> (qf)
/
(q0)
\
В -> (q2) - В -> (qf)
Это очень простой парсер для этого языка. Вы начинаете с (q0) , начальное состояние, затем вы читаете символ со входа, если это A , тогда вы переходите в состояние (q1) , в противном случае (это B , помните помните, что алфавит только A и B ) вы переходите в состояние (q2) и так далее.Если вы достигли состояния (qf) , значит, ввод был принят.
Как это наглядно, вам понадобится всего лишь карандаш и лист бумаги, чтобы объяснить кому-либо, в том числе и ребенку, что такое парсер. Я думаю, что простота — это то, что делает автоматы наиболее подходящим способом обучения концепциям языковой обработки, таким как синтаксический анализ.
Наконец, будучи студентом информатики, вы будете углубленно изучать такие концепции на курсах теоретической информатики, таких как формальные языки и теория вычислений.
Написание синтаксического анализатора — Часть I: Начало работы | от Супун Сетунга | The Startup
В этой статье обсуждается простой подход к реализации рукописного синтаксического анализатора с нуля и некоторые основы, связанные с ним. Здесь больше внимания уделяется объяснению практических аспектов реализации, а не формальным определениям синтаксических анализаторов.
Синтаксический анализатор — это первое, что приходит в голову, когда мы говорим о разработке компилятора / создании компилятора. Совершенно справедливо, синтаксический анализатор играет ключевую роль в архитектуре компилятора и может также рассматриваться как точка входа в компилятор.Прежде чем мы углубимся в подробности написания парсера, давайте посмотрим, что на самом деле означает синтаксический анализ.
Что такое синтаксический анализ
Анализ по существу означает преобразование исходного кода в представление объекта в виде дерева, которое называется «деревом синтаксического анализа» (также иногда называемым «синтаксическим деревом»). Часто абстрактное синтаксическое дерево (AST) путают с синтаксическим деревом. Дерево синтаксического анализа — это конкретное представление исходного кода. Он сохраняет всю информацию исходного кода, включая тривиальную информацию, такую как разделители, пробелы, комментарии и т. Д.Принимая во внимание, что AST является абстрактным представлением исходного кода и может не содержать некоторой информации, содержащейся в источнике.
В синтаксическом дереве каждый элемент называется «узлом». Конечные узлы или конечные узлы рассматриваются как особый вид узлов, который называется «токеном». Нетерминальные узлы обычно называются просто «узлами».
Почему парсер рукописный?
Если вы посмотрите вокруг, вы увидите, что существует довольно много генераторов парсеров, таких как ANTLR, Bison, Yacc и т. Д.С помощью этих генераторов синтаксического анализатора мы можем просто определить грамматику и автоматически сгенерировать синтаксический анализатор в соответствии с этой грамматикой. Звучит довольно просто! Если да, то зачем писать парсер с нуля?
Распространенная ошибка при создании компилятора — думать, что нам нужно написать синтаксический анализатор с нуля, или думать, что нам не нужен собственный синтаксический анализатор. Что ж, звучит противоречиво! Загвоздка в том, что у обоих подходов есть свои плюсы и минусы. Поэтому важно знать, когда писать синтаксический анализатор вручную или использовать генератор синтаксического анализатора:
Сгенерированный синтаксический анализатор:
- Простота реализации — Определите грамматику в необходимом формате и сгенерируйте синтаксический анализатор.например: для ANTLR все, что нам нужно, это определить грамматику в формате
.g4. Затем создать синтаксический анализатор так же просто, как запустить одну команду. - Простота обслуживания. Все, что вам нужно сделать, — это обновить правила грамматики и восстановить синтаксический анализатор.
- Может быть компактным по размеру.
- Однако он не имеет преимуществ рукописного синтаксического анализатора (см. Ниже).
Рукописный синтаксический анализатор:
- Написание синтаксического анализатора вручную — умеренно сложная задача.Сложность может возрасти, если грамматика языка сложна. Однако у него есть следующие преимущества.
- Может иметь более качественные и содержательные сообщения об ошибках. Автоматически сгенерированные парсеры могут иногда приводить к совершенно бесполезным ошибкам.
- Может поддерживать устойчивый синтаксический анализ. Другими словами, он может создать действительное дерево синтаксического анализа даже при синтаксической ошибке. Это также означает, что рукописный синтаксический анализатор может одновременно обнаруживать и обрабатывать несколько синтаксических ошибок. В сгенерированных синтаксических анализаторах это может быть достигнуто в определенной степени с помощью обширных настроек, но может быть не в состоянии полностью поддерживать устойчивый синтаксический анализ.
- Может поддерживать инкрементный синтаксический анализ — анализировать только часть кода при обновлении источника.
- Обычно лучше по производительности.
- Легко настроить. Вы владеете кодом и имеете полный контроль над ним — например: в ANTLR4, если вы хотите настроить логику синтаксического анализа, вам придется либо расширить и немного взломать сгенерированный синтаксический анализатор, либо написать некоторую настраиваемую логику в сам файл грамматики на другом языке. Иногда это может быть беспорядочно, и уровень настройки, которую можно выполнить, очень ограничен.
- Может легко обрабатывать контекстно-зависимые грамматики. Не все языки на 100% контекстно-свободны. Могут быть ситуации, когда вы хотите токенизировать ввод или построить дерево синтаксического анализа по-разному в зависимости от контекста. Когда дело касается сгенерированных синтаксических анализаторов, это очень сложная или практически невыполнимая задача.
Итак, в общем, если вы хотите получить устойчивый высокооптимизированный синтаксический анализатор промышленного уровня и если у вас достаточно времени, то рукописный синтаксический анализатор — это то, что вам нужно.С другой стороны, вам нужен достаточно приличный парсер в очень короткие сроки, а производительность или отказоустойчивость не являются одним из ваших требований, сгенерированный парсер сделает свое дело.
Независимо от того, реализовать ли рукописный синтаксический анализатор или использовать сгенерированный синтаксический анализатор, всегда будет нужна одна вещь: четко определенная грамматика (формальная грамматика) для языка, который мы собираемся реализовать. Грамматика определяет лексическую и синтаксическую структуру программы на этом языке.Очень популярным и простым форматом определения контекстно-свободной грамматики является форма Бэкуса-Наура (BNF) или один из ее вариантов, например, расширенная форма Бэкуса-Наура (EBNF).
Хотя синтаксический анализатор часто называют одним компонентом в архитектуре компилятора, он состоит из нескольких компонентов, включая, помимо прочего, лексер, синтаксический анализатор и несколько других абстракций, таких как считыватели ввода / символов и обработчик ошибок. На приведенной ниже диаграмме показаны компоненты и то, как они связаны друг с другом в нашей реализации парсера.
Считыватель символов / считыватель ввода
Считыватель символов, также называемый считывателем ввода, считывает исходный код и предоставляет символы / кодовые точки лексеру по запросу. Исходным кодом может быть множество вещей: файл, входной поток или даже строка.
Также возможно встроить возможности считывателя ввода в сам лексер. Однако преимущество абстрагирования читателя от лексера состоит в том, что, в зависимости от ввода, мы можем подключать разные читатели к одному и тому же лексеру.И лексеру не нужно беспокоиться об обработке различных типов входных данных.
Считыватель ввода состоит из трех наборов важных методов:
- peek () / peek (k) — Получить следующий символ / следующий k-й символ из ввода. Это используется для просмотра символов вперед, не потребляя / не удаляя их из входного потока. Вызов метода
peek ()более одного раза вернет один и тот же символ. - Потребление () / потребление (k) — Получить следующий символ / следующий k-й токен из входа и удалить его из входа.Это означает, что многократный вызов метода
consumer ()будет возвращать новый символ при каждом вызове. Иногда этот методtake ()также называетсяread ()илиnext (). - isEOF () — Проверяет, достиг ли считыватель конца ввода.
Лексер
Лексер считывает символы из устройства чтения / ввода символов и производит токены. Другими словами, он преобразует поток символов в поток токенов.Поэтому его иногда также называют токенизатором. Эти токены производятся в соответствии с определенной грамматикой. Обычно реализация лексера немного сложнее, чем программа чтения символов, но намного проще, чем синтаксический анализатор.
Важным аспектом лексического анализатора является обработка пробелов и комментариев. В большинстве языков семантика языка не зависит от пробелов. Пробелы необходимы только для обозначения конца токена, поэтому их также называют «мелочами» или «мелочами», поскольку они не имеют большого значения для AST.Однако это не относится к каждому языку, потому что пробелы могут иметь семантическое значение в некоторых языках, таких как python. Разные лексеры обрабатывают эти пробелы и комментарии по-разному:
- Отбросить их в лексере. Недостатком этого подхода является то, что он не сможет воспроизвести исходный текст из синтаксического / синтаксического дерева. Это может стать проблемой, если вы планируете использовать дерево синтаксического анализа для таких целей, как форматирование кода и т. Д.
- Испускать пробелы как отдельные токены, но для другого потока / канала, чем обычный токен.Это хороший подход для языков, в которых пробелы имеют семантическое значение.
- Сохраните их в дереве синтаксического анализа, прикрепив к ближайшему токену. В нашей реализации мы будем использовать этот подход.
Подобно считывателю символов, лексер состоит из двух методов:
- peek () / peek (k) — Получить следующий токен / следующий k-й токен. Это используется для просмотра токенов вперед, не потребляя / не удаляя их из входного потока. Вызов метода
peek ()более одного раза вернет один и тот же токен. - Потребление () / потребление (k) — Получить следующий токен / следующий k-й токен и удалить его из потока токенов. Это означает, что многократный вызов метода
consumer ()будет возвращать новый токен при каждом вызове. Иногда этот методtake ()также называетсяread ()илиnext ().
Как только лексер достигает конца ввода от считывателя символов, он выдает специальный токен, называемый «EOFToken» (токен конца файла).Парсер использует этот EOFToken для завершения анализа.
Синтаксический анализатор
Синтаксический анализатор отвечает за чтение токенов из лексического анализатора и создание синтаксического дерева. Он получает следующий токен от лексера, анализирует его и сравнивает с определенной грамматикой. Затем решает, какое из грамматических правил следует учитывать, и продолжает анализ в соответствии с грамматикой. Однако это не всегда очень просто, поскольку иногда невозможно определить, какой путь выбрать, только взглянув на следующий токен.Таким образом, синтаксическому анализатору, возможно, придется проверить несколько токенов в будущем, чтобы определить путь или грамматическое правило, которое следует учитывать. Подробнее об этом мы поговорим в следующей статье. Однако из-за подобных сложностей синтаксический анализатор также является наиболее сложным компонентом для реализации в архитектуре синтаксического анализатора.
Как правило, синтаксическому анализатору нужен только один метод — метод parse () , который будет выполнять весь синтаксический анализ и возвращает дерево синтаксического анализатора.
Учитывая тот факт, что нашей целью является реализация синтаксического анализатора, который был бы одновременно устойчивым и выдавал правильные сообщения об ошибках, правильная обработка синтаксических ошибок является довольно важным аспектом синтаксического анализатора.Синтаксическая ошибка — это случай, когда достигается неожиданный токен или, другими словами, следующий токен не соответствует определенной грамматике во время синтаксического анализа. В таких случаях синтаксический анализатор просит «обработчик ошибок» (см. Следующий раздел) исправить эту синтаксическую ошибку, и как только обработчик ошибок восстанавливается, синтаксический анализатор продолжает анализировать остальную часть ввода.
Обработчик ошибок
Как обсуждалось в предыдущем разделе, задачей обработчика ошибок является восстановление после синтаксической ошибки. Он играет ключевую роль в современном отказоустойчивом парсере, особенно для того, чтобы иметь возможность создавать действительное дерево парсеров даже с синтаксическими ошибками и выдавать правильные и содержательные сообщения об ошибках.
Возможности обработки ошибок также могут быть встроены в сам анализатор. Преимущество этого заключается в том, что поскольку ошибки будут обрабатываться сразу же в анализаторе, в точке восстановления доступно много контекстной информации. Однако недостатков больше, чем преимуществ встраивания возможностей восстановления в сам анализатор:
- Попытка восстановить каждое место приведет к множеству повторяющихся задач и дублированию кодов
- Логика парсера будет загромождена ошибками логика обработки, которая в конечном итоге сделает кодовую базу трудной для чтения и понимания.
- Имея отдельный обработчик ошибок, можно также подключать разные обработчики ошибок для разных сценариев использования. Например, можно использовать один подход к обработке ошибок для инструментов CLI и другой подход к обработке ошибок для интерактивных IDE. Поскольку IDE могут захотеть облегчить завершение кода и т. Д., И, следовательно, шаблон восстановления будет более близок к шаблону написания пользователя.
Как разобрать JSON в C ++ — Linux Hint
Цель этого руководства — понять данные JSON и понять, как анализировать данные JSON в C ++.Мы обсудим данные JSON, объект, массив, синтаксис JSON, а затем рассмотрим несколько рабочих примеров, чтобы понять механизм анализа данных JSON в C ++.
Что такое JSON?
JSON — это легкое текстовое представление для хранения и передачи структурированных данных организованным способом. Данные JSON представлены в виде упорядоченных списков и пар ключ-значение. JSON означает J ava S cript O bject N otation. Как видно из полного названия, он получен из JavaScript.Однако данные JSON поддерживаются в большинстве популярных языков программирования.
Часто используется для передачи данных с сервера на веб-страницу. Представлять структурированные данные в JSON намного проще и чище, чем в XML.
Правило синтаксиса JSON
Вот правила синтаксиса JSON:
- Данные JSON всегда должны быть в форме пар «ключ-значение».
- JSON Данные разделены запятыми.
- Фигурная скобка используется для представления объекта JSON.
- Квадратная скобка используется для представления массива JSON.
Что такое данные JSON?
Данные JSON представлены в виде пар «ключ-значение». Это похоже на словарь или хеш в других языках программирования.
«Имя»: «Дрейк»
Это пример простых данных JSON. Ключ здесь — «Имя», а «Дрейк» — соответствующее значение. Ключ, то есть «Имя», и значение, то есть «Дрейк», разделяются двоеточием.
Расширение файла JSON
Данные JSON обычно хранятся в файле с расширением «.json ». Например, чтобы сохранить данные сотрудника, вы можете просто назвать файл «employee.json». Это будет простой текстовый файл. Затем вы можете открыть этот файл JSON в любом из ваших любимых текстовых редакторов.
Объект JSON
Объект JSON — это не что иное, как данные JSON, заключенные в фигурные скобки. Вот пример объекта JSON:
{
«Имя»: «Дрейк»,
«Идентификатор сотрудника»: «23547a»,
«Телефон»: «23547»,
«Отдел»: «Финансы»
}
Объект JSON может содержать несколько данных JSON.Все данные JSON разделяются запятой. Данные JSON представлены в виде пар «ключ-значение». Ключ, то есть «Имя», и значение, то есть «Дрейк», разделяются двоеточием. В приведенном выше примере есть четыре пары «ключ-значение». Первый ключ — «Имя»; Соответствующее значение для него — «Дрейк». Точно так же «EmployeeID», «Phone» и «Department» являются тремя другими ключами.
Массив JSON
Массив JSON может содержать несколько объектов JSON, разделенных запятыми. Массив JSON заключен в квадратные скобки.Давайте посмотрим на пример массива JSON:
«Студенты»: [
{«firstName»: «Шон», «lastName»: «Коричневый»},
{«firstName»: «Дрейк», «lastName»: «Уильямс»},
{«firstName»: «Том», «lastName»: «Миллер»},
{«firstName»: «Питер», «lastName»: «Джонсон»}
]
Это пример массива JSON. Здесь «Студенты» заключены в квадратные скобки, т.е. массив, и он содержит четыре объекта JSON. Каждый из этих объектов представлен в виде пар «ключ-значение» и разделен запятыми.
Пример файла JSON
Теперь, когда мы разобрались с данными JSON, объектами JSON, массивом JSON, давайте рассмотрим пример файла JSON:
{
«firstName»: «Sean»,
«lastName»: «Brown»,
«Student ID»: 21453,
«Department»: «Computer Sc.»,
«Subjects»: [«Math», « Phy »,« Chem »]
}
Библиотеки синтаксического анализа в C ++:
В C ++ нет собственного решения для синтаксического анализа данных JSON. Однако существует несколько библиотек для анализа данных JSON в C ++.В этой статье мы рассмотрим две самые популярные библиотеки для анализа данных JSON на C ++. Вот ссылки GitHub для анализа данных JSON:
- https://github.com/nlohmann/json
- https://github.com/Tencent/rapidjson/
Вы можете загрузить эти библиотеки, чтобы иметь возможность выполнять примеры, показанные ниже.
Примеры
Теперь у нас есть базовое представление о данных JSON, объектах, массивах и доступных библиотеках синтаксического анализа.Давайте теперь рассмотрим несколько примеров для анализа данных JSON на C ++:
- Пример-1: Разбор JSON в C ++
- Пример-2: Разбор и сериализация JSON в C ++
- Пример-3: Разбор JSON в C ++
Для Примера-1 и Примера-2 мы собираемся использовать библиотеку «nlohmann». В случае Примера-3 мы будем использовать библиотеку RapidJSON.
Пример-1: Разбор JSON в C ++
В этом примере программы мы продемонстрируем, как получить доступ к значениям данных JSON в C ++.
#include
#include «json.hpp»
с использованием json = nlohmann :: json;
int main ()
{
// jdEmployees
json jdEmployees =
{
{«firstName», «Sean»},
{«lastName», «Brown»},
{«StudentID», 21453},
{«Кафедра», «Компьютерные науки»}
};
// Доступ к значениям
std :: string fName = jdEmployees.value («firstName», «oops»);
std :: string lName = jdEmployees.значение («lastName», «ой»);
int sID = jdEmployees.value («StudentID», 0);
std :: string dept = jdEmployees.value («Отдел», «ой»);
// Распечатать значения
std :: cout << "Имя:" << fName << std :: endl;
std :: cout << "Фамилия:" << lName << std :: endl;
std :: cout << "Идентификатор студента:" << sID << std :: endl;
std :: cout << "Отдел:" << dept << std :: endl; возврат 0;
}
Пример-2: Разбор и сериализация JSON в C ++
В этом примере программы мы увидим, как анализировать и сериализовать JSON в C ++.Мы используем «json :: parse ()» для анализа данных JSON.
#include
#include «json.hpp»
#include
с использованием json = nlohmann :: json;
int main ()
{
// Вот текст JSON
char text [] = R «(
{
» Книга «: {
» Ширина «: 450,
» Высота «: 30,
» Заголовок «:» Hello World «,
» isBiography «: false,
» NumOfCopies «: 4,
» LibraryIDs «: [2319, 1406, 3854, 987]
}
}
)»;
// Давайте проанализируем и сериализуем JSON
json j_complete = json :: parse (text);
std :: cout << std :: setw (4) << j_complete << std :: endl;
}
Пример-3: Разбор JSON в C ++
Теперь мы продемонстрируем, как анализировать строку JSON с помощью библиотеки RapidJSON.RapidJSON изначально был вдохновлен RapidXML. В этом примере программы мы анализируем строку JSON в DOM. Мы объявили «mydoc» типа «Document», а затем использовали метод «mydoc.parse ()» для анализа строки JSON.
#include
#include «rapidjson / writer.h»
#include «rapidjson / document.h»
#include «rapidjson / stringbuffer.h»
с использованием пространства имен rapidjson;
int main ()
{
const char * json = «{» firstName «:» Шон «,» lastName «:» Коричневый «,» empId «: 21453,
» Department «:» Computer Sc.»}»;
// Разобрать строку JSON в DOM
Document mydoc;
mydoc.Parse (json);
// DOM в строку
StringBuffer buffer;
Writer
mydoc.Accept (писатель);
// Распечатать вывод
std :: cout << buffer.GetString () << std :: endl;
возврат 0;
}
Заключение
В этой статье мы кратко обсудили данные, объект, массив и синтаксис JSON.Как мы знаем, в C ++ нет собственного решения для синтаксического анализа данных JSON; мы использовали две разные библиотеки для анализа данных JSON в C ++. Мы рассмотрели три разных примера, чтобы продемонстрировать механизм синтаксического анализа данных JSON в C ++. По сравнению с библиотекой «nlohmann» RapidJSON маленький, быстрый и удобный для памяти.
Как работает JavaScript: синтаксический анализ, абстрактные синтаксические деревья (AST) + 5 советов по сокращению времени синтаксического анализа | автор: Lachezar Nickolov
Это пост # 14 из серии, посвященной изучению JavaScript и его компонентов.В процессе идентификации и описания основных элементов мы также разделяем некоторые практические правила, которые мы используем при создании SessionStack, приложения JavaScript, которое должно быть надежным и высокопроизводительным, чтобы помогать пользователям видеть и воспроизводить дефекты своего веб-приложения в режиме реального времени.
Если вы пропустили предыдущие главы, вы можете найти их здесь:
Мы все знаем, как все может получиться запутанным, если вы попадете в один большой кусок JavaScript. Этот фрагмент кода необходимо не только передать по сети, но также его нужно проанализировать, скомпилировать в байт-код и, наконец, выполнить.В предыдущих сообщениях мы обсуждали такие темы, как движок JS, среда выполнения и стек вызовов, а также движок V8, который в основном используется Google Chrome и NodeJS. Все они играют жизненно важную роль во всем процессе выполнения JavaScript. Тема, которую мы планируем представить сегодня, не менее важна: мы увидим, как большинство движков JavaScript анализируют текст, выделяя что-то значимое для машины, что происходит после этого, и как мы, веб-разработчики, можем использовать эти знания в своих интересах.
Итак, давайте сделаем шаг назад и посмотрим, как вообще работают языки программирования.Независимо от того, какой язык программирования вы используете, вам всегда понадобится какое-то программное обеспечение, которое может взять исходный код и заставить компьютер действительно что-то делать. Это программное обеспечение может быть интерпретатором или компилятором. Независимо от того, используете ли вы интерпретируемый язык (JavaScript, Python, Ruby) или скомпилированный (C #, Java, Rust), всегда будет одна общая часть: анализ исходного кода как простого текста в структуру данных, называемую абстрактное синтаксическое дерево (AST). AST не только представляют исходный код в структурированном виде, но также играют важную роль в семантическом анализе, когда компилятор проверяет правильность и правильное использование программы и языковых элементов.Позже AST используются для генерации фактического байт-кода или машинного кода.
AST используются не только в языковых интерпретаторах и компиляторах. У них есть множество приложений в компьютерном мире. Один из наиболее распространенных способов их использования — статический анализ кода. Статические анализаторы не выполняют код, заданный на их вход. Тем не менее, им необходимо понимать структуру кода. Например, вы можете реализовать инструмент, который находит общие структуры кода, чтобы вы могли реорганизовать их, чтобы уменьшить дублирование.Вы могли бы сделать это, используя сравнение строк, но реализация будет очень простой и ограниченной. Естественно, если вы заинтересованы в реализации такого инструмента, вам не нужно писать собственный парсер. Существует множество реализаций с открытым исходным кодом, полностью совместимых со спецификациями Ecmascript. Эсприма и Желудь, чтобы назвать пару. Есть также много инструментов, которые могут помочь с выводом, производимым анализатором, а именно AST. AST также широко используются при реализации транспиляторов кода.Так, например, вы можете реализовать транспилятор, который преобразует код Python в JavaScript. Основная идея заключается в том, что вы должны использовать транспилятор Python для генерации AST, который затем будет использоваться для генерации обратного кода JavaScript. Вы можете спросить, как такое вообще возможно. Дело в том, что AST — это просто другой способ представления некоторого языка. Перед синтаксическим анализом он представлен в виде текста, который следует некоторым правилам, составляющим язык. После синтаксического анализа он представлен в виде древовидной структуры, которая содержит точно такую же информацию, что и входной текст.Следовательно, мы всегда можем сделать противоположный шаг и вернуться к текстовому представлению.
Итак, давайте посмотрим, как строится AST. В качестве примера у нас есть простая функция JavaScript:
Парсер выдаст следующий AST.
Обратите внимание, что для целей визуализации это упрощенная версия того, что будет производить синтаксический анализатор. Настоящая AST намного сложнее. Идея здесь, однако, состоит в том, чтобы понять, что в первую очередь произойдет с исходным кодом, прежде чем он будет выполнен.Если вы хотите увидеть, как выглядит фактический AST, вы можете проверить AST Explorer. Это онлайн-инструмент, в котором вы передаете некоторый JavaScript, а он выводит AST для этого кода.
Зачем мне нужно знать, как работает парсер JavaScript, спросите вы. В конце концов, ответственность за его работу лежит на браузере. И вы вроде как правы. На приведенном ниже графике показано общее время, выделенное на различные этапы процесса выполнения JavaScript. Присмотритесь и посмотрите, не найдете ли вы что-нибудь интересное.
Вы это видели? Присмотритесь. В среднем браузеру требуется от 15% до 20% от общего времени выполнения, чтобы проанализировать JavaScript. Я не придумывала цифр. Это статистика из реальных приложений и веб-сайтов, которые так или иначе используют JavaScript. Сейчас 15% могут показаться вам не много, но поверьте мне, это так. Типичный SPA загружает около 0,4 МБ JavaScript, и браузеру требуется около 370 мс для его анализа. Опять же, вы можете сказать: ну, это не так уж и много.Само по себе это не так уж и много. Однако имейте в виду, что это только время, необходимое для синтаксического анализа кода JavaScript в AST. Это не включает само выполнение или какие-либо другие процессы, происходящие во время загрузки страницы, такие как рендеринг CSS и HTML. И все это относится только к десктопам. Когда мы переходим на мобильные устройства, все быстро усложняется. Время, затрачиваемое на синтаксический анализ, на телефонах может быть в два-пять раз больше, чем на настольных компьютерах.
На приведенном выше графике показано время синтаксического анализа пакета JavaScript размером 1 МБ на мобильных и настольных устройствах различного класса.
Более того, веб-приложения становятся все сложнее с каждой минутой, поскольку все больше бизнес-логики переходит на сторону клиента, чтобы обеспечить более естественный пользовательский интерфейс. Вы можете легко понять, насколько это влияет на ваше приложение / веб-сайт. Все, что вам нужно сделать, это открыть инструменты разработчика браузера и позволить ему измерить количество времени, затрачиваемого на синтаксический анализ, компиляцию и все остальное, что происходит в браузере, пока страница не загрузится полностью.
К сожалению, в мобильных браузерах нет инструментов разработчика.Но не беспокойтесь. Это не значит, что вы ничего не можете с этим поделать. Вот почему существуют такие инструменты, как DeviceTiming. Это может помочь вам измерить время синтаксического анализа и выполнения скриптов в контролируемой среде. Он работает, обертывая локальные скрипты кодом инструментария, так что каждый раз, когда ваши страницы открываются с разных устройств, вы можете локально измерять время синтаксического анализа и выполнения.
Хорошо то, что движки JavaScript многое делают, чтобы избежать лишней работы и стать более оптимизированными.Вот несколько вещей, которые движки делают в основных браузерах.
V8, например, выполняет потоковую передачу скриптов и кэширование кода. Потоковая передача сценариев означает, что асинхронные и отложенные сценарии анализируются в отдельном потоке, как только начинается загрузка. Это указывает на то, что синтаксический анализ выполняется почти сразу после загрузки сценария. Это приводит к тому, что страницы загружаются примерно на 10% быстрее.
Код JavaScript обычно компилируется в байт-код при каждом посещении страницы. Однако этот байт-код затем отбрасывается, когда пользователь переходит на другую страницу.Это происходит потому, что скомпилированный код во многом зависит от состояния и контекста машины во время компиляции. Здесь Chrome 42 представляет кеширование байт-кода. Это метод, при котором скомпилированный код хранится локально, поэтому, когда пользователь возвращается на ту же страницу, все шаги, такие как загрузка, синтаксический анализ и компиляция, могут быть пропущены. Это позволяет Chrome сэкономить около 40% времени на синтаксический анализ и компиляцию. Кроме того, это также приводит к экономии заряда аккумулятора мобильных устройств.
В Opera механизм Carakan может повторно использовать вывод компилятора из другой программы, которая была недавно скомпилирована.Не требуется, чтобы код был с той же страницы или даже домена. Этот метод кеширования на самом деле очень эффективен и позволяет полностью пропустить этап компиляции. Он основан на типичном поведении пользователя и сценариях просмотра: всякий раз, когда пользователь следует определенному пути пользователя в приложении / веб-сайте, загружается один и тот же код JavaScript. Однако двигатель Carakan давно был заменен на двигатель V8 от Google.
Движок SpiderMonkey, используемый Firefox, не кэширует все. Он может перейти в стадию мониторинга, где подсчитывает, сколько раз выполняется данный скрипт.На основе этого подсчета он определяет, какие части кода наиболее актуальны и нуждаются в оптимизации.
Очевидно, некоторые принимают решение ничего не делать. Мацей Стаховяк, ведущий разработчик Safari, заявляет, что Safari не кэширует скомпилированный байт-код. Это то, что они рассматривали, но они не реализовали, поскольку генерация кода составляет менее 2% от общего времени выполнения.
Эти оптимизации не влияют напрямую на синтаксический анализ исходного кода JavaScript, но они определенно делают все возможное, чтобы полностью его пропустить.Что может быть лучшей оптимизацией, чем совсем ее не делать?
Есть много вещей, которые мы можем сделать, чтобы улучшить время начальной загрузки наших приложений. Мы можем минимизировать объем поставляемого JavaScript: меньше скриптов, меньше синтаксического анализа, меньше выполнения. Для этого мы можем доставить только код, необходимый для определенного маршрута, вместо того, чтобы загружать один большой двоичный объект всего. Например, шаблон PRPL проповедует этот тип доставки кода. В качестве альтернативы, мы можем проверить наши зависимости и посмотреть, есть ли что-нибудь лишнее, что могло бы делать не что иное, как раздувание нашей кодовой базы.Однако эти вещи заслуживают отдельной темы.
Цель этой статьи — обсудить, что мы, как веб-разработчики, можем сделать, чтобы помочь синтаксическому анализатору JavaScript выполнять свою работу быстрее. Так и есть. Современные парсеры JavaScript используют эвристику, чтобы определить, будет ли определенный фрагмент кода выполняться немедленно или его выполнение будет отложено на некоторое время в будущем. На основе этой эвристики синтаксический анализатор будет выполнять либо нетерпеливый, либо отложенный синтаксический анализ. Активный синтаксический анализ запускает функции, которые необходимо немедленно скомпилировать.Он выполняет три основные задачи: строит AST, строит иерархию областей видимости и находит все синтаксические ошибки. С другой стороны, отложенный синтаксический анализ используется только для функций, которые еще не нужно компилировать. Он не создает AST и не находит всех синтаксических ошибок. Он только строит иерархию областей видимости, что экономит примерно половину времени по сравнению с активной оценкой.
Понятно, что это не новая концепция. Даже такие браузеры, как IE 9, поддерживают такой тип оптимизации, хотя и довольно элементарно по сравнению с тем, как работают современные парсеры.
Давайте посмотрим, как это работает. Скажем, у нас есть некоторый JavaScript, который имеет следующий фрагмент кода:
Как и в предыдущем примере, код загружается в синтаксический анализатор, который выполняет синтаксический анализ и выводит AST. Итак, у нас есть что-то вроде:
Объявление функции foo , которая принимает один аргумент (x). Он имеет одно выражение возврата. Функция возвращает результат операции + над x и 10.
Объявление функции bar , которая принимает два аргумента (x и y).Он имеет одно выражение возврата. Функция возвращает результат операции + над x и y.
Выполните вызов функции для bar с двумя аргументами 40 и 2.
Сделайте вызов функции console.log с одним аргументом как результат предыдущего вызова функции.
Так что же только что произошло? Парсер видел объявление функции foo, объявление функции bar, вызов функции bar и вызов функции console.log. Но подождите … синтаксический анализатор проделал некоторую дополнительную работу, которая совершенно не имеет значения.Это синтаксический анализ функции foo. Почему это неактуально? Потому что функция foo никогда не вызывается (или, по крайней мере, не в этот момент). Это простой пример, который может выглядеть необычно, но во многих реальных приложениях многие из заявленных функций никогда не вызываются.
Здесь вместо анализа функции foo мы можем отметить, что она объявлена без указания того, что она делает. Фактический анализ происходит при необходимости, непосредственно перед выполнением функции. И да, ленивый синтаксический анализ все еще должен найти все тело функции и сделать для нее объявление, но это все.Ему не нужно синтаксическое дерево, потому что оно еще не будет обрабатываться. Кроме того, он не выделяет память из кучи, которая обычно занимает изрядное количество системных ресурсов. Короче говоря, пропуск этих шагов приводит к значительному повышению производительности.
Итак, в предыдущем примере синтаксический анализатор действительно сделал бы что-то вроде следующего.
Обратите внимание, что объявление функции foo подтверждено, но это все. Больше ничего не было сделано для включения в тело самой функции.В этом случае тело функции было всего лишь одним оператором возврата. Однако, как и в большинстве реальных приложений, он может быть намного больше, содержать несколько операторов возврата, условий, циклов, объявлений переменных и даже вложенных объявлений функций. И все это будет пустой тратой времени и системных ресурсов, поскольку функция никогда не будет вызвана.
Это довольно простая концепция, но на самом деле ее реализация далеко не проста. Здесь мы показали один пример, который, безусловно, не единственный.Весь метод применяется к функциям, циклам, условным операторам, объектам и т. Д. В основном, ко всему, что нужно проанализировать.
Например, вот один довольно распространенный шаблон для реализации модулей в JavaScript.
Этот шаблон распознается большинством современных синтаксических анализаторов JavaScript и является сигналом о том, что код внутри должен быть быстро проанализирован.
Так почему же парсеры не всегда выполняют синтаксический анализ лениво? Если что-то анализируется лениво, это должно быть выполнено немедленно, и это фактически замедлит его работу.Он будет производить один ленивый синтаксический анализ и еще один активный синтаксический анализ сразу после первого. Это приведет к 50% замедлению по сравнению с простым анализом.
Теперь, когда у нас есть базовое представление о том, что происходит за кулисами, пора подумать о том, что мы можем сделать, чтобы помочь синтаксическому анализатору. Мы можем написать наш код таким образом, чтобы функции анализировались в нужное время. Есть один шаблон, который распознается большинством синтаксических анализаторов: заключение функции в круглые скобки. Это почти всегда положительный сигнал для парсера о том, что функция будет выполнена немедленно.Если синтаксический анализатор видит открывающую скобку и сразу после этого объявление функции, он с готовностью проанализирует функцию. Мы можем помочь синтаксическому анализатору, явно объявив функцию как таковую, которая будет выполняться немедленно.
Допустим, у нас есть функция с именем foo.
Поскольку нет очевидных признаков того, что функция будет выполнена немедленно, браузер будет выполнять ленивый синтаксический анализ. Однако мы уверены, что это неверно, поэтому можем сделать две вещи.
Сначала мы сохраняем функцию в переменной:
Обратите внимание, что мы оставили имя функции между ключевым словом функции и открывающей скобкой перед аргументами функции.Это не обязательно, но рекомендуется, поскольку в случае сгенерированного исключения трассировка стека будет содержать фактическое имя функции, а не просто <анонимный>.
Синтаксический анализатор все еще будет выполнять ленивый синтаксический анализ. Этого можно избежать, добавив одну небольшую деталь: заключив функцию в круглые скобки.
На этом этапе, когда синтаксический анализатор видит открывающую скобку перед ключевым словом функции, он немедленно приступит к синтаксическому анализу.
Это может быть довольно сложно управлять вручную, поскольку нам нужно знать, в каких случаях синтаксический анализатор решит анализировать код лениво или нетерпеливо.Кроме того, нам нужно будет подумать, будет ли определенная функция вызвана немедленно или нет. Мы определенно не хотим этого делать. И последнее, но не менее важное: это затруднит чтение и понимание нашего кода. Чтобы помочь нам в этом, на помощь приходят такие инструменты, как Optimize.js. Их единственная цель — оптимизировать время начальной загрузки исходного кода JavaScript. Они выполняют статический анализ вашего кода и модифицируют его таким образом, что функции, которые необходимо выполнить в первую очередь, заключаются в круглые скобки, чтобы браузер мог быстро проанализировать их и подготовить к выполнению.
Итак, мы кодируем как обычно, и есть фрагмент кода, который выглядит так:
Кажется, все в порядке, работает, как ожидалось, и это быстро, потому что перед объявлением функции стоит открывающая скобка. Отлично. Конечно, перед запуском в производство нам нужно минимизировать наш код, чтобы сохранить байты. Следующий код является выводом минификатора:
Вроде нормально. Код работает как раньше. Однако чего-то не хватает. Минификатор удалил круглую скобку, заключающую функцию, и вместо этого поместил один восклицательный знак перед функцией.Это означает, что синтаксический анализатор пропустит это и выполнит ленивый синтаксический анализ. Сверху, чтобы иметь возможность выполнить функцию, он будет выполнять быстрый синтаксический анализ сразу после ленивого. Все это замедляет работу нашего кода. К счастью, у нас есть такие инструменты, как Optimize.js, которые делают за нас всю тяжелую работу. Передача миниатюрного кода через Optimize.js приведет к следующему результату:
Это больше похоже на это. Теперь у нас есть лучшее из обоих миров: код минимизирован, а синтаксический анализатор правильно определяет, какие функции нужно анализировать быстро, а какие нет.
Но почему мы не можем выполнить всю эту работу на стороне сервера? В конце концов, гораздо лучше сделать это один раз и предоставить результаты клиенту, чем заставлять каждого клиента выполнять свою работу каждый раз. Что ж, продолжается дискуссия о том, должны ли движки предлагать способ выполнения предварительно скомпилированных сценариев , чтобы это время не тратилось зря в браузере. По сути, идея состоит в том, чтобы иметь инструмент на стороне сервера, который может генерировать байт-код, который нам нужно будет только передать по сети и выполнить на стороне клиента.Тогда мы увидим некоторые существенные различия во времени запуска. Это может показаться заманчивым, но не все так просто. Это может иметь противоположный эффект, поскольку он будет больше и, скорее всего, потребуется подписать код и обработать его по соображениям безопасности. Команда V8, например, работает над внутренним избеганием повторного анализа, чтобы предварительная компиляция на самом деле не была такой полезной.
- Проверьте свои зависимости. Избавьтесь от всего ненужного.
- Разделите код на более мелкие части вместо загрузки одного большого двоичного объекта.
- По возможности отложите загрузку JavaScript. Вы можете загрузить только необходимые фрагменты кода на основе текущего маршрута.
- Используйте инструменты разработчика и DeviceTiming, чтобы выяснить, где находится узкое место.
- Используйте такие инструменты, как Optimize.js, чтобы помочь синтаксическому анализатору решить, когда выполнять синтаксический анализ быстро, а когда нет.
SessionStack — это инструмент, который визуально воссоздает все, что происходило с конечными пользователями в то время, когда они столкнулись с проблемой при взаимодействии с веб-приложением.Инструмент не воспроизводит сеанс как реальное видео, а скорее моделирует все события в изолированной среде браузера. Это имеет некоторые последствия, например, в сценариях, когда кодовая база загруженной в данный момент страницы становится большой и сложной.
Вышеупомянутые методы — это то, что мы недавно начали включать в процесс разработки SessionStack. Такая оптимизация позволяет нам быстрее загружать SessionStack. Чем быстрее SessionStack может освободить ресурсы браузера, тем более плавный и естественный пользовательский интерфейс будет предлагать инструмент при загрузке и просмотре пользовательских сеансов.
Существует бесплатный план, если вы хотите попробовать SessionStack.
Ресурсы
Как автоматически копировать данные из ваших электронных писем
eBay отправлено по электронной почте — кто-то заказал что-то в вашем магазине. Ваш банк отправил вам по электронной почте ежемесячный отчет, ваша кредитная карта напоминает вам об оплате счета, а Apple напоминает вам о приложении, которое вы купили вчера вечером. И контактная форма на вашем сайте хороша, но каждое сообщение — это еще одна вещь, которая накапливается в вашем почтовом ящике.
В вашем почтовом ящике уведомления — это только больше беспорядка, больше вещей, которые нужно архивировать и забыть.Было бы проще сортировать эту информацию и управлять ею в электронной таблице или базе данных, но для этого вам потребуется время, чтобы скопировать текст из электронных писем и вставить его в другое место.
Или вы можете позволить приложению сделать эту работу за вас. Вот как автоматически анализировать текст электронных писем и эффективно использовать их данные.
Что такое анализатор электронной почты?
Когда ваш босс или лучший друг пишет по электронной почте, вы, вероятно, читаете каждое слово.
В остальное время, скорее всего, вы просматриваете сообщение.Ваш взгляд быстро бегает по экрану, выбирая ключевые слова и фразы, например, , Новая распродажа, и , 4,99 доллара, и Срок платежа: пятница, 3 ноября, .
Парсеры электронной почты работают таким же образом. Вы учите эти программы распознавать закономерности в ваших электронных письмах, сообщаете им, какие данные на самом деле важны и что все остальное можно игнорировать, а затем заставляете их сохранять только важные данные. Затем подключите анализатор электронной почты к инструменту автоматизации, например Zapier, чтобы сохранить этот важный текст в других приложениях, чтобы вы могли регистрировать заказы, например, в электронной таблице или получать напоминание об оплате счета по кредитной карте завтра.Поскольку все электронные письма в целом составлены одинаково, анализатор электронной почты должен уметь определять, что важно, и копировать данные за вас.
Понял? ОК. Давайте сделаем резервную копию и шаг за шагом создадим парсер электронной почты, который может копировать текст из ваших писем и заставлять его работать. Мы будем использовать парсер электронной почты Zapier — бесплатный инструмент для копирования текста из ваших писем. Если вы используете другой инструмент синтаксического анализа электронной почты, эти указания по-прежнему будут применяться — основы работают одинаково в каждом приложении, и как только вы знаете, как анализировать одно электронное письмо, вы знаете, как анализировать их все.
и далее.
Создайте новый почтовый ящик парсера электронной почты
Отправьте электронное письмо парсеру
Научите синтаксический анализатор читать вашу электронную почту
Автоматически пересылать электронные письма парсеру
Поместите проанализированное письмо данные для работы
1. Создайте новый почтовый ящик парсера электронной почты
Первый шаг — самый простой. Просто перейдите на parser.zapier.com, войдите в свою учетную запись Zapier или создайте новую учетную запись, затем нажмите любую из кнопок Create Mailbox (обозначены стрелками на снимке экрана ниже), чтобы добавить новый почтовый ящик.
Email Parser покажет вам адрес электронной почты, например [email protected].
Скопируйте этот адрес и держите его под рукой, потому что именно по нему вам нужно будет отправлять электронные письма для последующего анализа.
2. Отправьте электронное письмо синтаксическому анализатору
Теперь, когда у вас скопирован новый адрес электронной почты, откройте приложение электронной почты, найдите (или напишите) электронное письмо, подобное тем, которые вы хотите использовать с анализатором электронной почты. Я хочу, чтобы Email Parser сообщал мне о новых сообщениях в блоге Zapier (мета, я знаю), поэтому я пересылаю недавнее электронное письмо от Деб из Zapier.
Нажмите кнопку, чтобы переслать электронное письмо, введите свой адрес электронной почты @ robot.zapier.com в поле Кому: и нажмите Отправить .
3. Научите синтаксический анализатор читать вашу электронную почту.
Выберите текст, который синтаксический анализатор должен скопировать, затем присвойте ему уникальное имя.
Пора надеть шляпу учителя. Как только Zapier Email Parser получит ваше письмо, он покажет текстовую версию вашего письма в поле Initial Template . Все, что вам нужно сделать, это найти важные данные и сказать парсеру, что именно это нужно скопировать.
Прокрутите вниз до текста, который вы хотите, чтобы анализатор электронной почты скопировал, и выберите его. Используя электронную почту, которую я использовал, я хочу знать заголовки в разделе «Рекомендуемая литература от команды блога Zapier», поэтому я выбираю текст из каждого из них. Для каждого выделенного фрагмента текста введите имя этого элемента в поле и нажмите Сохранить . Анализатор электронной почты заменит текст на имя в фигурных скобках, например {{headline1}} .
Повторите это для каждого фрагмента текста, который анализатор электронной почты должен скопировать.Я тоже выбрал каждую тему и дал каждому элементу уникальное имя.
Как только это будет сделано, нажмите синюю кнопку Сохранить адрес и шаблон внизу — и ваш анализатор электронной почты готов к работе.
Анализатор электронной почты будет работать лучше всего, если выбранный вами текст будет написан одинаково в каждом электронном письме — возможно, цифра после слова Всего или ссылка, написанная после слова Щелкните здесь . Значение может измениться, но анализатор электронной почты будет работать лучше всего, если предыдущий текст будет всегда одинаковым и в одном и том же месте.
Хотите сделать парсер электронной почты более надежным? Перешлите другое аналогичное электронное письмо на тот же адрес, затем щелкните View Emails рядом с именем вашего парсера в списке Zapier Email Parser Mailboxes , чтобы просмотреть все электронные письма, полученные этим почтовым ящиком.
Щелкните Показать на одном из элементов, чтобы увидеть текст сообщения электронной почты, при этом текст Email Parser выделен желтым цветом.
Если что-то выглядит неправильно (как в моем примере выше), щелкните ссылку Изменить дополнительный шаблон внизу.Выберите тот же текст, который вы изначально хотели скопировать из своих писем, дайте ему те же имена, а затем сохраните новый шаблон. Вы можете повторить это несколько раз, чтобы сделать ваш синтаксический анализатор более надежным.
Вы можете использовать ту же технику для анализа любого обычного электронного письма, которое вы получаете. Например, вы можете научить его распознавать названия продуктов и цены в электронных письмах с подтверждением покупки от Amazon или Apple.
4. Автоматическая пересылка новых писем в анализатор
Созданный вами анализатор электронной почты теперь готов копировать текст из других похожих писем — в данном случае из новостной рассылки Zapier Blog.Нам нужно отправлять каждую новую рассылку на анализатор электронной почты.
Лучший вариант — автоматизировать работу с помощью фильтра в приложении электронной почты для автоматической пересылки сообщений, соответствующих тому, которое вы отправили в Email Parser. Как правило, все ваши электронные письма с уведомлениями имеют что-то общее — они исходят от одного и того же отправителя и часто имеют одну и ту же тему. В моем примере эти электронные письма приходят с адреса [email protected] и содержат слова «Рекомендуемая литература от команды разработчиков блога Zapier».
Чтобы отслеживать эти электронные письма в Gmail, вам сначала нужно добавить свой адрес парсера электронной почты в Gmail для автоматической пересылки писем.Вот как это сделать:
Откройте настройки пересылки Gmail — щелкните значок шестеренки, выберите Настройки , затем щелкните вкладку Пересылка .
Нажмите кнопку Добавить адрес пересылки там.
Введите адрес электронной почты вашего парсера электронной почты @ robot.zapier.com в текстовое поле и щелкните рядом с .
Проверьте свою электронную почту — Zapier должен отправить вам письмо с подтверждением от Gmail. Если вы его не видите, проверьте почтовый ящик приложения Email Parser — в нем должен быть адрес электронной почты.В любом случае скопируйте код подтверждения , затем вставьте его в поле в настройках Gmail Forwarding .
Теперь вы можете настроить автоматическую пересылку писем в Gmail парсеру электронной почты. Сначала найдите адрес электронной почты и / или тему сообщений, которые вы будете обрабатывать парсером электронной почты; Я вхожу с: [email protected] И «Рекомендуемая литература от команды блогов Zapier». Щелкните крошечную стрелку вниз справа от строки поиска, чтобы увидеть все параметры расширенного поиска — затем щелкните кнопку Создать фильтр или ссылку в правом нижнем углу.Попросите этот фильтр пересылать электронное письмо на адрес парсера электронной почты, который вы только что добавили, и все должно быть настроено.
После небольшого упражнения с мышью и клавиатурой все готово. Каждый раз, когда Деб из Zapier отправляет вам последний информационный бюллетень Zapier — или всякий раз, когда вы получаете любые другие сообщения электронной почты, которые хотите проанализировать, — Gmail отправляет их парсеру электронной почты.
Если вы используете другую службу электронной почты, проверьте свою документацию, чтобы узнать, может ли ваше приложение или служба автоматически пересылать сообщения электронной почты.
5. Заставьте ваши проанализированные данные электронной почты работать
Одного копирования текста из электронных писем недостаточно — вам нужно что-то делать с этими данными. Самый простой вариант — подключить парсер электронной почты к приложениям автоматизации Zapier, что позволяет отправлять данные из ваших писем в тысячи других популярных рабочих приложений — от Airtable до Zoho.
Посетите Zapier и войдите в систему или зарегистрируйтесь, если вы еще этого не сделали. Затем нажмите Make a Zap , чтобы начать. Выберите Email Parser в качестве триггерного приложения, затем выберите триггерное событие New Email .Подключите свою учетную запись парсера электронной почты, если вы еще этого не сделали, и выберите адрес парсера, который вы только что настроили.
Zapier может использовать текст, который анализатор электронной почты находит, но вы хотите
После этого вы можете использовать данные электронной почты. На шаге Action выберите приложение, в которое вы хотите отправить данные электронной почты. Я хотел получать SMS-уведомление о последних заголовках, поэтому я выбрал действие SMS приложения Zapier Отправить SMS .
Чтобы использовать данные электронной почты, щелкните любое из полей действия Zap и выберите любое значение из триггера Zap.Здесь я добавил темы и заголовки из имени и цены из Email Parser в SMS-уведомления — вы, возможно, можете добавить имена и адреса электронной почты в свой информационный бюллетень по электронной почте, записывать информацию о продажах в строки электронной таблицы или, тем не менее, использовать свои данные электронной почты. ты хочешь.
Протестируйте Zap, чтобы убедиться, что все работает так, как вы хотите, включите его, и все готово!
Еще не знаете, куда отправлять эти электронные письма? Начните сохранять их с помощью этих Zap
Если вы похожи на меня, у вас есть много писем, которые, как вы знаете, вы уже хотите автоматизировать, но вы не совсем уверены, куда нужно отправлять всю информацию. еще.В таких случаях может быть удобно запустить Zap, который анализирует электронные письма и сохраняет их в электронную таблицу, чтобы вы могли позже вернуться к хорошо организованным данным.
Нажмите Попробовать в одном из этих рекомендуемых Zap-файлов, чтобы сразу же начать сохранять проанализированные электронные письма в Google Sheets или Airtable, или чтобы настроить собственное SMS-уведомление для электронной почты:
Теперь, когда вы анализируете свою электронную почту, узнайте больше способы автоматизации этой информации и использования ее в других приложениях.