Морфологический разбор слова. Онлайн сервис Текстовод.Морфология
{{ info }}
Выполнить
{{ text }} — {{ item.tag }}
Начальная форма — {{ item.normal_form }}
Формы слова
{{ lexem[0] }} — {{ lexem[1] }}
Морфологический разбор слова — это анализ его морфологических признаков.
Морфология — это раздел науки о языке, изучающий слово как часть речи.
Данный сервис поможет определить часть речи любого русского слова и его морфологические признаки онлайн.
Напечатайте проверяемое слово в форме поиска и нажмите «Выполнить».
Возле анализируемого слова вы увидите сокращения морфологических признаков.
Расшифровка всех обозначений находится в Словаре сокращений (ссылка внизу, сразу после разбора).
После указания морфологических признаков, программа ставит слово в начальную форму.
Затем предоставляются варианты форм слова.
После этого приводится морфологический разбор каждой формы слова по отдельности.
Учитывайте, что буквы е и ё — это две разные буквы, соответственно, разбор слов с этими буквами будет разным.
Морфологический разбор всех слов начинается с определения части речи.
Далее порядок отличается.
Разбор существительного.
1. Поставить слово в именительном падеже, единственном числе, т.е. в начальную форму.
2. Затем указать постоянные признаки слова:
- разряд по значению (нарицательное или собственное),
- одушевлённое или неодушевлённое,
- склонение, род, число.


3. После этого, определить непостоянные признаки разбираемого слова: падеж и число.
Выполним разбор слова текстовод.
СУЩ. — существительное,
Од. — одушевлённое,
мр. — мужской род,
Ед. — единственное число,
им. — именительный падеж.
Начальная форма — текстовод.
Формы слова:
текстовод — СУЩ,од,мр ед,им
текстовода — СУЩ,од,мр ед,рд
текстоводу — СУЩ,од,мр ед,дт
текстовода — СУЩ,од,мр ед,вн
текстоводом — СУЩ,од,мр ед,тв
текстоводе — СУЩ,од,мр ед,пр
текстовода — СУЩ,од,мр мн,им,разг
текстоводы — СУЩ,од,мр мн,им
текстоводов — СУЩ,од,мр мн,рд
текстоводам — СУЩ,од,мр мн,дт
текстоводов — СУЩ,од,мр мн,вн
текстоводами — СУЩ,од,мр мн,тв
текстоводах — СУЩ,од,мр мн,пр.
Разбор прилагательного.
1. Найти начальную форму слова. Для этого необходимо поставить слово в именительный падеж, мужской род единственного числа.
2. Затем определить постоянный признак слова — разряд.
3. После найти непостоянные признаки: степень сравнения, форма, число, падеж и род.
Пример: лучший.
ПРИЛ. — прилагательное,
Превосх. — превосходная степень,
Кач. Качественный разряд,
мр. — мужской род,
ед.- единственное число,
им. — именительный падеж.
Начальная форма — хороший.
Формы слова:
хороший — ПРИЛ,кач мр,ед,им
хорошего — ПРИЛ,кач мр,ед,рд
хорошему — ПРИЛ,кач мр,ед,дт
хорошего — ПРИЛ,кач од,мр,ед,вн
хороший — ПРИЛ,кач неод,мр,ед,вн
хорошим — ПРИЛ,кач мр,ед,тв
хорошем — ПРИЛ,кач мр,ед,пр.
И т. д.
Разбор глагола.
1. Записать слово в начальной форме — инфинитиве.
2. Затем определить постоянные признаки слова: вид, спряжение, переходность, возвратность.
3. После найти непостоянные признаки слова: число, наклонение, время, род, лицо.
Пример: помогает.
ГЛ. — глагол.
— глагол.
Несов. — несовершенный вид,
Неперех. — непереходный,
Ед — единственное число,
3л — третье лицо,
Наст. — настоящее время,
Изъяв. — изъявительное наклонение.
Начальная форма — помогать.
Формы слова:
помогать — ИНФ,несов,неперех
помогаю — ГЛ,несов,неперех ед,1л,наст,изъяв
помогаем — ГЛ,несов,неперех мн,1л,наст,изъяв
помогаешь — ГЛ,несов,неперех ед,2л,наст,изъяв.
И т.д.
Разбор причастия.
1. Поставить слово в начальную форму.
2. Указать разряд причастия.
3. Затем написать признаки: форма, число, род, падеж, время, вид, возвратность.
Пример: думающий.
ПРИЧ. — причастие.
Несов. — несовершенный вид,
Неперех. — непереходное,
Наст. — настоящее время,
Действ. — действительный залог,
мр. — мужской род,
ед. — единственное число,
им. — именительный падеж.
Начальная форма — думать.
Формы слова:
думать — ИНФ,несов,неперех
думаю — ГЛ,несов,неперех ед,1л,наст,изъяв
думаем — ГЛ,несов,неперех мн,1л,наст,изъяв
думаешь — ГЛ,несов,неперех ед,2л,наст,изъяв
И т. д.
Разбор деепричастия.
1. Поставить слово в начальную форму.
2. Определить постоянные признаки: возвратность, вид, переходность и спряжение.
3. Затем определить непостоянный признак — неизменяемость.
Например: улыбнувшись.
ДЕЕПР — деепричастие,
Сов. — совершенный вид,
Неперех.- непереходный,
Прош — прошедшее время,
*ши — деепричастие на -ши.
Начальная форма — улыбнуться.
Формы слова:
улыбнуться — ИНФ,сов,неперех
улыбнулся — ГЛ,сов,неперех мр,ед,прош,изъяв
И т. д.
Разбор местоимения.
1. Определить постоянные признаки: разряд, соотношение с другой частью речи, лицо, число.
2. Указать переменные признаки: род и падеж местоимения.
Пример: они.
МС. — местоимение-существительное,
3л — третье лицо,
Анаф. — Анафорическое (местоимение),
Мн — множественное число,
Им — именительный падеж.
Начальная форма — они.
Формы слова:
они — МС,3л,Анаф мн,им
их — МС,3л,Анаф мн,рд
Разбор наречия.
1. Определяются следующие признаки: разряд, степень сравнения, неизменяемость.
Пример: зачем.
Н. — наречие,
Вопр — вопросительное,
Предк? — может выступать в роли предикатива
Начальная форма — зачем.
Разбор частиц.
Самый короткий разбор бывает у частиц.
У этих частей речи указываются начальная форма, неизменяемость, разряд и функция.
Смотрите сами: только.
ЧАСТ. — частица
Начальная форма — только.
Формы слова:
только — ЧАСТ
тока — ЧАСТ искаж.
Фонетический (звуко-буквенный) разбор слова, транскрипция. Онлайн сервис
{{ info }}
Выполнить
Текстовод.Фонетика производит фонетический разбор слова онлайн.
Добавьте слово в форму, и программа автоматически произведёт его разбор.
Такой разбор еще называют звуко-буквенный — т. к. в процессе анализа слова подсчитывается количество букв и звуков.
Также, при фонетическом разборе слово делится на слоги и ставится ударение.
Но основная цель — выполнить фонетическую транскрипцию и произвести характеристику всех звуков.
Порядок проведения фонетического разбора:
1. Постановка ударения.
2. Разбивка на слоги.
Разбивка на слоги.
Здесь предоставляются 2 варианта: слоги для анализа и варианты для переноса слова.
3. Транскрипция слова [в квадратных скобках].
4. Характеристика слова.
5. Транскрипция каждого звука по порядку.
Звук помещается в квадратные скобки.
а) Если он согласный, то определяются следующие его характеристики:
- звонкий/глухой/сонорный,
- парный/непарный,
- твёрдый/мягкий.
Мягкость звука обозначается знаком апострофа [«].
б) Если звук гласный, то устанавливается его ударность.
в) Если у буквы отсутствует звук (ь, ъ и др.), то ставится прочерк [-].
Заметка.
* Не бывает звуков [е], [ё], [ю], [я]. Буквы е, ё, ю, я имеют в разных словах различные звуки.
Пример.
* Также, нет звука у непроизносимых согласных в корне слова.
Например, солнце — [сонц»э]
6. Подсчёт букв и звуков.
7. Составление цветовой схемы слова.
Наш сервис позволяет сделать звуко-буквенный разбор слова русского языка любой части речи.
В качестве бонуса программа определяет часть речи, число, падеж, категории одушевленности и переходности, род, лицо, время; вид, наклонение, степень и форму (глаголов) и др.
Помните, что е и ё — это две разные буквы, влияющие на результат разбора.
Примите, также, во внимание, что омографы (слова с одинаковым написанием, но разным произношением) будут иметь совершенно разный фонетический разбор.
На сайте textovod.com вы найдёте разбор всех возможных омографов.
Учтите, что последовательность нашего разбора может отличаться от порядка анализа вашей учебной программы.
Синтаксический разбор предложения
Каждое наше выражение мыслей состоит из логически связанных предложений. Чтобы грамотно составить предложение, которое полностью передаст весь смысл, нужно знать, из чего оно состоит, и какая структура должна быть для правильного понимания. Чем сложнее формулировка, тем больше составных частей, которые сложно уловить и осмыслить с первого раза. Чтобы упростить понимание, существует синтаксический разбор.
Чем сложнее формулировка, тем больше составных частей, которые сложно уловить и осмыслить с первого раза. Чтобы упростить понимание, существует синтаксический разбор.
Что такое синтаксический разбор предложения?
Синтаксический анализ подразумевает изучение строения текста. Это выражается через выявление взаимосвязей между определенными частями речи. Соединение словосочетаний и предложений между собой также играет важную роль. Синтаксический анализ текста позволяет:
- Разобрать, как построено и из чего состоит каждое отдельное предложение или словосочетание.
- Выявить взаимосвязь между отдельными словами.
- Определить темы, которые относятся к синтаксическим единицам.
- Выявить главные и второстепенные члены предложения.
- Определить грамматические основы.
При таком разборе определяют какого времени и наклонения часть речи, действующие лица, а также количество главных членов предложения.
Какие члены предложения определяют при синтаксическом анализе?
Полный синтаксический разбор выполняется для того, чтобы проанализировать структуру предложения и, тем самым, повысить уровень грамотности в сфере пунктуации. Этот анализ проводится:
- по тексту;
- по предложению;
- по словосочетанию.
Выделяют 5 основных членов предложения:
- Подлежащее
- Сказуемое
- Дополнение
- Обстоятельство
- Определение
Подлежащее и сказуемое являются главными членами предложения (существительное или местоимение + глагол). Остальные 3 части речи являются второстепенными. Определение выражается прилагательным, обстоятельство уточняет место, либо время, а дополнение относится к подлежащему.
Как провести синтаксический разбор предложения онлайн?
Как это работает:
- На сайте нашего сервиса вы вставляете или пишете текст в специальном окне.
- Нажимаете кнопку «Разобрать».
- Сервис производит разбор текста по частям речи и выводит на экран итоговый вариант.

Пользователю будет показано число каждой части речи, содержащейся в тексте. Каждая часть речи выделена в тексте определенным цветом, что наглядно показывает, где в предложении она находится. Наведя на определенную часть речи, всплывает дополнительное окно, где указана информация:
- Какая это часть речи.
- Начальная форма.
- Характеристики (в зависимости от части речи: род, число, падеж, время, изменяемость, вид, одушевленность и т.д.).
Это позволяет детально разобрать каждую составляющую текста и лучше понять их взаимосвязь.
Результаты анализа можно сохранить. После каждого разбора, пользователю предоставляется индивидуальная ссылка на результаты анализа введенного текста.
Кому понадобится синтаксический анализ предложений?
В первую очередь, этот инструмент очень полезен для учащихся и студентов. Они могут использовать его как для более подробного разбора темы и улучшения понимания, так и для проверки своих знаний и закрепления. Также его могут использовать копирайтеры и редакторы, это поможет повысить качество текстов и значительно уменьшит количество стилистических ошибок.
Как можно самостоятельно выполнить синтаксический разбор простого и сложного предложения (схема и план) + 5 лучших онлайн сервисов для ленивых
Просмотров 64.1k. Опубликовано
Обновлено
Синтаксический анализ вызывает у новичка в этом вопросе большие трудности. Особенно пугает длинное предложение, которое имеет множество членов, предикативных частей. На деле выполнять решение не так страшно, и русский язык предельно логичен, как и его синтаксис. Из этой статьи вы узнаете о том, что такое полный синтаксический разбор предложения – образец анализа приведен подробно, в деталях.
Для чего нужен синтаксический анализ
Синтаксический анализ – это выделение членов предложения по их функциональному значению и описание высказывания исходя из его целевых, эмоциональных, структурных особенностей.
Иногда его называют пунктуационным разбором. Такой анализ более глобален, чем орфографический, морфологический или фонетический.
Научившись самостоятельно делать синтаксический анализ на примере, можно разобраться в структуре высказывания, принципах его построения. Синтаксис и пунктуация взаимосвязаны, поэтому определение схемы дает знания о том, как расставлять знаки препинания.
Таблица или образец синтаксического разбора будут помогать как ребенку в начальной школе, так и студенту лингвистической специальности, изучающему русский язык.
Типы простого предложения
Простое предложение – это высказывание, где есть одно подлежащее и одно сказуемое. Также возможен вариант, когда есть только подлежащее или только сказуемое.
По цели бывают:
- повествовательными – автор делится информацией, есть точка в конце;
Катя решила сделать гимнастику.
- вопросительными – автор хочет узнать определенную информацию, есть вопрос в конце;
Когда уже наступит лето?
- побудительные – автор побуждает сделать что-либо, восклицательный знак в конце.
Не сорите в общественном месте!
Побудительные высказывания часто имеют лексические маркеры, которые дают подсказку: давай, будем, сделай, идемте и т.п.
Классификация по эмоциональной окраске включает в себя:
- восклицательные – есть восклицательный знак в конце;
Петя, почему ты не помыл руки?!
- невосклицательные – нет восклицательного знака в конце.
На дворе снежно и солнечно.
По наличию главных членов простые предложения принимают такой вид:
- односоставные – если есть подлежащее, но нет сказуемого, или наоборот;
В городе весна.

В столице пахнет осенью.
- двусоставные – есть и подлежащее, и сказуемое.
Зима настала в городе
Когда нет одного из главных членов:
- назывные – только подлежащее;
Здесь глушь.
- определенно-личные – только сказуемое, которое стоит в 1-м или 2-м лице;
Люблю кататься на коньках.
- неопределенно-личное – сказуемое стоит во множественном числе и 3-м лице;
К вам пришли.
- обобщенно-личное – грамматическая форма сказуемого не важна, важно только значение обобщенности и то, что высказывание можно отнести к любому человеку;
Работаешь, работаешь – и без результата.
- безличное – сказуемое может быть наречием, а также страдательным причастием прошедшего времени или безличным глаголом.
Мне нужно выйти. Ему не спится.
Обобщенно-личный тип включает прежде всего пословицы, поговорки, фразеологизмы и другие устойчивые сочетания.
По наличию второстепенных членов высказывания делятся на:
- нераспространенные – есть только грамматическая основа;
Корабль плывет.
- распространенные – есть другие члены предложения, кроме грамматической основы: обстоятельство, или дополнение, или определение, или все вместе.
Корабль величественно плывет по волнам.
По критерию полноты выражения предложение может быть:
- полным – все члены прописаны, нет недоговоренности;
Мое жилье располагается здесь.
- неполным – определенные члены могут подразумеваться, нередко на их месте стоит тире.
А мое жилье – здесь.

Учитывая все критерии, по которым делятся предложения, и их характеристики, можно сделать подробный синтаксический анализ по плану.
Типы сложного предложения
Сложное – это высказывание, в котором при идеальном раскладе есть два подлежащих и два сказуемых. Но иногда случается, что есть только два сказуемых или только два подлежащих, одно сказуемое и два подлежащих и т.п.
В сложном предложении с несколькими придаточными частями можно найти даже 3 или 4 грамматических основы, а не только 2.
Сложные высказывания делятся по цели и эмоциональной окраске так же, как и простые.
При определении типа сложного предложения нужно смотреть на наличие союза:
- союзное – союз есть;
Если бы на Земле не было воды, здесь бы не зародилась жизнь.
- бессоюзное – союз отсутствует, может стоять запятая или даже двоеточие;
Ярик не пошел в школу и остался дома: он болел.
В зависимости от союза высказывания бывают:
- сложносочиненные – союз сочинительный: сюда входят соединительные, противительные и разделительные;
Аня хотела хорошую оценку, но она не сделала домашнее задание.
- сложноподчиненные – союз подчинительный: все остальные союзные группы относятся к этому виду.
Аня должна была сделать домашнее задание, чтобы учитель поставил ей хорошую оценку.
Необходимо указывать, какой союз соединяет предикативные части высказывания; в бессоюзных предложениях это интонация.
После указания типа придаточной каждая из частей разбирается как простое предложение. Порядок синтаксического разбора такой же, но алгоритм начинается с критерия односоставности/двусоставности.
Как составить схему предложения
Рисовать схему нужно после выполнения самого синтаксического разбора. Произведите сперва обобщающий пунктационный разбор, иначе она рискует быть неполной или неверной.
Предлагаем составление схемы по следующей последовательности:
- рисуем скобки – в простом и сложносочиненном высказывании всегда нужны квадратные скобки, т.к. оно не имеет зависимых частей, а в сложноподчиненном –квадратными обозначается главная часть, а круглыми – зависимая;
- делаем графическое отображение предложения внутри, отмечая только грамматическую основу прямыми линиями в логическом порядке, никаких пунктирных или волнистых подчеркиваний.
- если есть союз или союзное слово, оно пишется буквами, а сверху подписывается с. или с. с.
- если сложноподчиненное, нужно нарисовать стрелку от главной части и подписать сверху вопрос к придаточной, на который она отвечает.
Например, схематический анализ сложноподчиненного предложения с разными видами связи выглядит так:
Я не хотел никого обидеть, но Саша надулся и сказал, что теперь он не будет со мной общаться.
[– =], но [– = и =], (что…).
Грамматическую основу рисуют только в главных частях, а союз в придаточной находится только внутри скобок, в отличие от независимых частей.
Образец простого разбора
Высшее общество всегда казалось ей неестественным, лживым и лицемерным.
Повествовательное, невосклицательное, простое, двусоставное, распространенное, полное.
Грамматическая основа: подлежащее – общество, сказуемое – казалось неестественным, лживым, лицемерным. Второстепенные члены: высшее – определение, ей – дополнение. Осложнено однородными составными глагольными сказуемыми.
Образец сложного разбора
Артур, уберись в своей комнате до прихода гостей, иначе я тебя накажу.
Побудительное, невосклицательное, сложносочиненное, состоит из двух предикативных частей, средство связи – сочинительный союз «иначе».
Первая часть: односоставное, определенно-личное, распространенное, полное. Сказуемое – уберись. В своей комнате до прихода гостей – обстоятельство. Осложнено обращением.
В своей комнате до прихода гостей – обстоятельство. Осложнено обращением.
Вторая часть: двусоставное, распространенное, полное. Подлежащее – я, сказуемое – накажу. Тебя – дополнение. Ничем не осложнено.
5 лучших онлайн сервисов
Синтаксический разбор предложения и текста сегодня можно выполнить онлайн и бесплатно.
ТОП-5 сервисов для этого:
- ProgaOnline – делает подчеркивания, определяет не только части речи, но и их формы: падеж, число, лицо и др.;
- Rustxt – яркий понятный дизайн, предоставляет довольно подробный синтаксический анализ;
- Seosin – может выполнять синтаксический разбор не только словосочетание или предложение, но и текст, подчеркивает все члены, делает морфологический анализ;
- GoldLit – неограниченное количество символов, есть анализы художественной литературы, но выдает только полный анализ части речи;
- Школьный помощник – поможет только со справочной информацией по теме, есть схемы анализа и упражнения.
Необходимо помнить, что анализ, который выполняется любой программой, может содержать мелкие неточности.
Проблемы с синтаксическим разбором предложений
Самой распространенной проблемой для школьника становится разделение частей речи от их функций в высказывании. Отсюда вытекает неумение правильно подчеркнуть члены.
Важно помнить: существительное либо местоимение может быть как дополнением, так и подлежащим, для имени прилагательного определение не приговор, числительные могут выступать в любой функции, а предлоги зависимы и закреплены за другими членами.
Побудительные предложения иногда заканчиваются точкой, а повествовательные – восклицательным знаком. Чтобы не запутаться, нужно обратить внимание на семантический аспект (что оно означает), а не только на знаки препинания.
Чтобы не запутаться, нужно обратить внимание на семантический аспект (что оно означает), а не только на знаки препинания.
Возникают проблемы и с тем, какими членами может быть осложнено предложение.
Высказывание часто осложняется:
- вводными конструкциями;
- деепричастием с зависимыми словами;
- причастным оборотом;
- сравнением и другими обособленными оборотами;
- обращением;
- приложением, т.е. определением в форме существительного;
- однородными членами.
Выводы
В этом материале мы рассмотрели, как сделать синтаксический анализ (разбор) простых и сложных предложений, разобрали конкретные примеры письменного анализа, возможные трудности. С использованием такой пошаговой инструкции и памяткой проанализировать высказывание сможет даже новичок.
Как делать полный синтаксический разбор предложения
Просто о синтаксическом разборе предложения
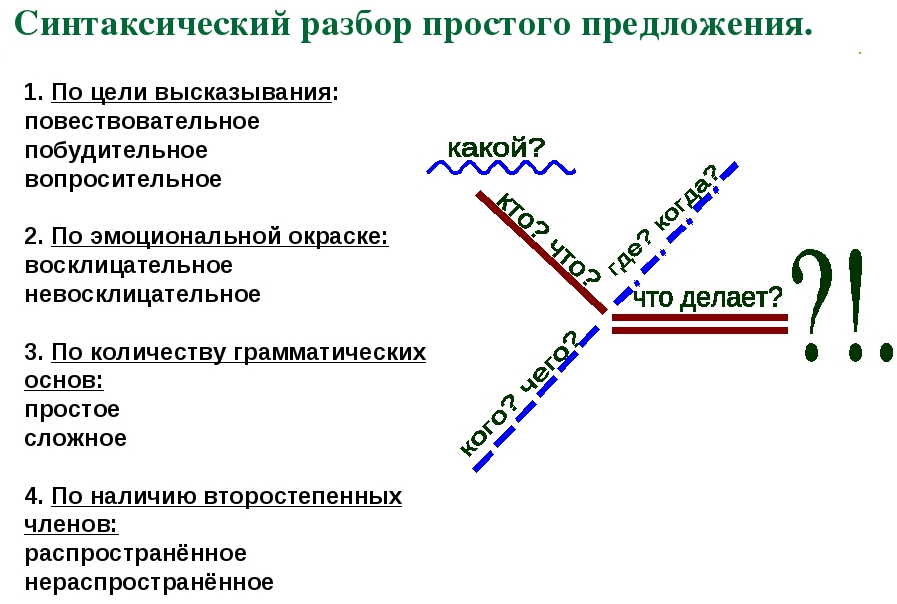
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:
| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |

Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложения
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
Сказуемое
- Отмечаем, чем является сказуемое – простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое – какой формой глагола;
- составное глагольное – из чего оно состоит;
- составное именное – какая употреблена связка, чем выражается именная часть.

В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Справочная информация
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое – это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое – это глагол, т.е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение – второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта – было бы скучно, уж поверьте. Итак, обстоятельство – это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?». А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной – важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» – как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.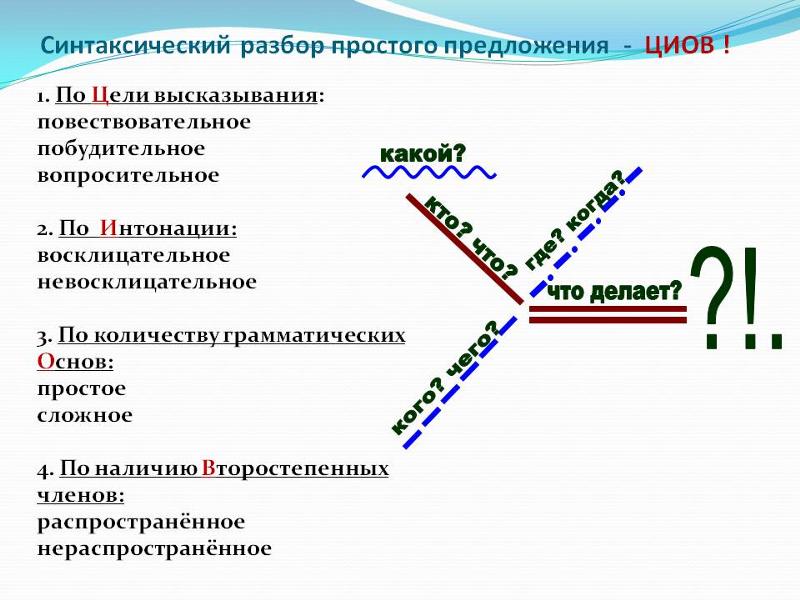
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая – придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой – как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т.е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется – оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола – действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость.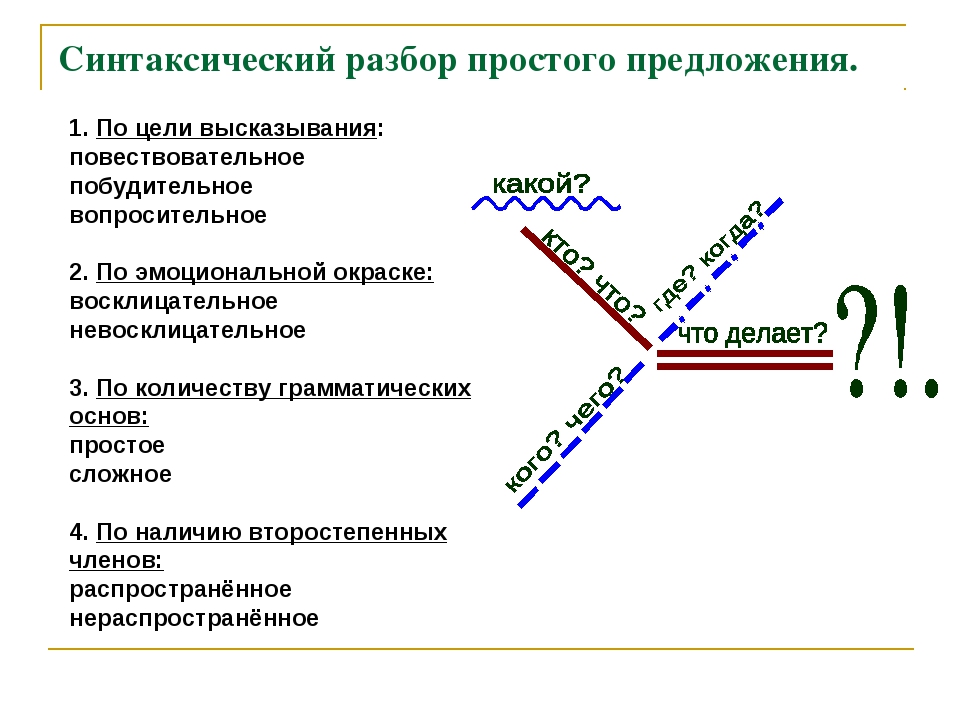 Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны. Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Единицы синтаксиса
Синтаксис изучает связь слов внутри словосочетаний или предложений. Таким образом, единицами синтаксиса являются словосочетания и предложения – простые или сложные. В этой статье мы будем говорить о том, как сделать синтаксический разбор предложения, а не словосочетания, хотя нередко в школе просят сделать и его.
Зачем нужен синтаксический разбор предложения
Синтаксический разбор предложения предполагает подробное рассмотрение его структуры. Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Члены предложения
Среди членов предложения всегда сначала выделяют главные: подлежащее и сказуемое. Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Грамматическая основа может состоять как из двух главных членов, так и включать в себя только один из них: или только подлежащее, или только сказуемое. Во втором случае мы говорим, что предложение односоставное. Если же присутствуют оба главных члена – двусоставное.
Если, кроме грамматической основы, слов в предложении нет, оно называется нераспространённым. В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.
если в предложении есть слова, которые членами предложения не являются (например, обращение), оно все равно считается нераспространенным.
Выполняя разбор, необходимо называть и часть речи, которой выражен тот или иной член предложения. Этот навык ребята отрабатывают, изучая в 5 классе русский язык.
Характеристика предложения
Чтобы дать характеристику предложению, надо указать надо его описать
- по цели высказывания;
- по интонации;
- по количеству грамматических основ и так далее.
Ниже мы предлагаем план характеристики предложения.
По цели высказывания: повествовательное, вопросительное, побудительное.
По интонации: восклицательное или невосклицательное.
Восклицательными могут быть любые по цели высказывания предложения, а не только побудительные.
По количеству грамматических основ: простое или сложное.
Если предложение простое, движемся дальше по плану; если сложное, путь отсюда придется пройти несколько раз: столько, сколько частей в сложном.
По количеству главных членов в грамматической основе: односоставное или двусоставное.
Если предложение односоставное, надо определить его вид: назывное, определённо-личное, неопределённо-личное, безличное.
По наличию второстепенных членов: распространённое или нераспространённое.
Если предложение чем-то осложнено, то это также надо указать. Это план синтаксического разбора предложения; лучше его придерживаться.
Осложнённое предложение
Предложение может быть осложнено обращением, вводными и вставными конструкциями, однородными членами, обособленными членами, прямой речью. Если какой-то из этих видов осложнений присутствует, то надо указать, что предложение осложненное, и написать чем.
Если предложение сложное
Если необходимо сделать разбор сложного предложения, надо сначала указать, что оно сложное, и определить его тип: союзное или бессоюзное, а если союзное, то еще и сложносочиненное или сложноподчиненное. Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
В таблице приведены второстепенные члены и их вопросы.
Второстепенные члены предложения
Вопросы
Кого? чего? кому? чему? кем? чем? о ком? о чем?
Какой? чей? который по счету?
Где? когда? куда? откуда? почему? зачем? как? в какой степени?
Второстепенные члены могут быть выражены разными частями речи, например определение:
шерстяная юбка – прилагательное;
юбка из шерсти – существительное;
юбка отглаженная – причастие;
привычка побеждать – инфинитив…
Пример синтаксического разбора предложения
Подчеркнем грамматические основы. Их две: знал и ты переехала . Определим части речи: знал – сказуемое, выражено глаголом в личной форме и т.д.
Теперь подчеркиваем второстепенные члены:
Переехала откуда? из деревни – обстоятельство, выражено существительным; куда? в город – тоже обстоятельство, тоже выражено существительным. Маша – это обращение, оно не является членом предложения.
Маша – это обращение, оно не является членом предложения.
Теперь дадим характеристику. Предложение повествовательное, невосклицательное, сложное, союзное, сложноподчиненное.
Первая часть «не знал» неполная, нераспространенная.
Вторая часть двусоставная, распространенная. Осложнено обращением.
По окончании разбора надо составить схему сложного предложения.
Что мы узнали?
Синтаксический разбор призван помочь понять структуру предложения, поэтому необходимо указать все, что может быть с ней связано. Выполнять разбор лучше по плану, тогда больше шансов, что вы ничего не забудете. Необходимо не только подчеркнуть члены предложения, но и определить части речи, и дать характеристику предложению.
3 предложения синтаксический разбор предложения
1. Прочитайте письмо и дневник космонавтов. Какова тема текстов? Обоснуйтесвоё мнение.Текст 1.Текст 2.Дорогие ребята!4 сентябряЧеловек полетел в космо
…
с. Какое этоДоброе утро, мои земляне, зем-замечательное событие! Всю свою исто- ляки! На Земле мечтал о космосе, врию человек с надеждой всматривался космосе снится Земля.в звёздное небо. Но знаете ли вы, зачем Вывел Космическую станцию натак стремиться в космос?орбиту. Приступил к выполнениюВо-первых, космос даёт нам понима- эксперимента Дастархан-6. Будуние многих процессов, которые происхо- есть первое блюдо — мясо по-казах-дят на планете Земля.ски в сублимированном виде.Во-вторых, в космосе нет границ, и5 сентябрялюди учатся сотрудничать, преодолеватьИзучаю системы жизнеобеспе-разногласия. Работа на одной космиче-чения станции. Готовлю скафандрской станции делает коллектив дружным.для выхода в открытый космос.В-третьих, возможно, в недалёком бу-6 сентябрядущем человек сможет жить на другихЗдесь, в бескрайнем космосе, ис-планетах, в других Галактиках. Ведь ре-сурсы нашей планеты не безграничны. следую вопрос: Может ли человекСтаньте, ребята, такими же смелыми,долго находиться в невесомости?как космонавты! Овладевайте знания- 7 сентябрями! От всего сердца приветствую ваше Пять суток прошло. Лечу. Полётстремление усердно учиться и совершать нормальный!добрые дела.Лётчик-космонавт,Лётчик-космонавт,Герой Советского СоюзаНародный Герой КазахстанаЮрий ГагаринАйдын АимбетовОзаглавьте тексты в соответствии с темой. Отражена ли основная мысль взаголовке или только тема? Передайте основную мысль каждого текста однимпредложением.2. Сравните тексты. Заполните таблицу в тетради. Сделайте письменно выводО сходстве и различии текстов.Текст 2Текст 1ТемаОсновная мысльКомпозицияТип речиНовые слова в текстеЖанр79
Лечу. Полётстремление усердно учиться и совершать нормальный!добрые дела.Лётчик-космонавт,Лётчик-космонавт,Герой Советского СоюзаНародный Герой КазахстанаЮрий ГагаринАйдын АимбетовОзаглавьте тексты в соответствии с темой. Отражена ли основная мысль взаголовке или только тема? Передайте основную мысль каждого текста однимпредложением.2. Сравните тексты. Заполните таблицу в тетради. Сделайте письменно выводО сходстве и различии текстов.Текст 2Текст 1ТемаОсновная мысльКомпозицияТип речиНовые слова в текстеЖанр79
235. Прочитай отает писателя Л. Пантелеева на один из вопросовинтервьюМеня спр..сили: «Какую роль с..грала в моей жизн.. кни-га?» А ведь это похоже на
…
то, как если бы спр..сили:«Какую роль играет в моей жизн.. воздух?»Если бы не было друзей — друзей-людей и друзей-кни… я никогда не смог бы стать писател..м.• Запиши текст, вставляя пропущенные буквы• Укажи знакомые тебе служебные части речи.
ДАЮ ВСЕ БАЛЛЫ МОЛЮ ПОМОГИТЕ С КРВыбери правильный ответ для выделенного слова.В этой стране ЕСТЬ область Кашемир.ОТВЕТ:сказуемоеопределениеобстоятельс
…
твоподлежащеедополнение
помогите даю 25 балов
7. Прочитай. Как называются слова, данные в скобках? Подумайдождём», а какие — если он будет называться «После дождя».(Тёплый – х…лодный) вет…р ду
…
ет вл…цо. (Лё…киеТ..жёлые) облака плывут над р…Кой. Д…носятся (сил…ные -слабые) раскаты грома.Запиши понравившийся вариант текста, вставляя пропущенные буквы.Подчеркни главные члены предложения и определения. Обсзначь части речи.
помогите срочно дам 15 баллов
16. Спиши предложения. Выполни их синтаксический разбор(разбери по членам предложения). Обозначь, какой частью речиВыражен каждый член предложения.1.
…
Высоко в небе поёт звонкую песенку жаворонок.2. На стене висели старинные часы.3. Громко звенела весенняя капель.4. За окном звонко пела маленькая птичка. ❗СРОЧНО ПОЖАЛУЙСТА ❗❓можно пожалуйста по фото? ❓
ДАЮ ВСЕ БАЛЛЫ!!!СРОЧНО ПОМОГИТЕ!!ГОДОВАЯ КОНТРОЛЬНАЯВыпиши всевозможное словосочетание с обстоятельством:Математическая олимпиада состоится в среду.
Укажи соединительную гласную в словах: лес..руб, пар..воз, снег..пад:
(Баллов: 5)
О
А
и А, и О
нет верного ответа
597Спишите текст, вставляя на места пропусков предложенные слова и словосочетания.Подчеркните дополнения.Портные шили <…>, гончары лепили <
…
…>, рудокопы до-бывали <…>.И хотя пахари усердно пахали, сеяли и собирали <…>, а ры-баки ловили <…> <…> в Срединном озере, продуктов вскорене стало хватать. Подземным рудокопам пришлось завести <…>с <…>.<…> жители пещеры давали <…>: медь и бронзу, железныеплуги и бороны, стекло, драгоценные камни.(По А. М. Волкову. «Семь подземных королей»)Слова для вставки: руду; рыбу и крабов; горшки; одежду; своиизделия; хлеб; сетями; меновую торговлю; верхними жителями;взамен зерна, масла и фруктов.ПОМОГИТЕ ПОЖАЛУЙСТА!
Подготовка к ВПР. 5-6 класс. Синтаксический разбор. | Методическая разработка по русскому языку (5, 6 класс):
Успех учащихся с ОВЗ (ЗПР) в выполнении Всероссийской проверочной работы зависит от систематической подготовки.
Цель: обобщение и систематизация знаний и способов деятельности учащихся.
Материал рассчитан на одну учебную неделю.
Тема: Синтаксический разбор. 5-6 класс.
Повторение теории занимает несколько минут и эффективно действует на выполнении синтаксического разбора. Теория предлагается в разных интерпретациях.
Теоретический опрос.
- Что такое грамматическая основа?
- Назови второстепенные члены.
- Расскажи об однородных членах предложения.
Индивидуальная работа с последующим обсуждением и ликвидацией ошибок.
Цель высказывания | Интонация | Наличие главных членов | Наличие или отсутствие второстепенных членов | По количеству грамматиче-ских основ |
1. | 1. | 1. | 1. | 1. |
2. | 2. | 2. | 2. | 2. |
3. |

Блиц-опрос (работа в парах).
- На какие вопросы отвечает подлежащее?
- На какие вопросы отвечает сказуемое?
- На какие вопросы отвечает дополнение?
- На какие вопросы отвечает обстоятельство?
- На какие вопросы отвечает определение?
Блиц-опрос (работа в парах).
- Какой член предложения отвечает на вопросы кто? что?
- Какой член предложения отвечает на вопросы что делает? и т.д.
- Какой член предложения отвечает на вопросы какой? чей?
- Какой член предложения отвечает на вопросы косвенных падежей?
- Какой член предложения отвечает на вопросы как? где? Куда? и т.д.
Блиц-опрос (работа в парах).
- Назовите главные члены предложения.
- Назовите второстепенные члены предложения.
- Составьте схему предложения с однородными членами.
- Является ли обращение членом предложения?
- Чем отличается простое предложение от сложного.
Теоретики.
1 группа. Тема: Грамматическая основа.
2 группа Тема: Второстепенные члены предложения.
3 группа Тема: Характеристика предложения.
4 группа. Тема: Однородные члены.
Практикум (первично коллективное выполнение с подробным обсуждением).
Выполните синтаксический разбор.
Весеннее солнце быстро плавит и гонит талые воды с полей.
Практикум (один учащийся выполняет у доски, далее взаимопроверка).
Выполните синтаксический разбор.
Мы резко остановились перед высокими воротами.
Практикум (самостоятельная работа при выполнении которой, сразу выявляется осознанность выполнения. Предоставляется возможность пользоваться алгоритмом.
Выполни синтаксический разбор.
Улыбнулись березки. ( __________., __________ ., __________., __________ ,__________ .)
Улыбнулись сонные березки! ( __________., __________ ., __________., __________ ,__________ .)
Карточка для домашнего задания на оценку.
Серое небо на западе порозовело. ( __________., __________ ., __________., __________ ,__________ .)
Практикум (работа в группах).
Выполните синтаксический разбор.
- Составьте предложение из слов: Ели, стояли, сугробах, в, громадные, высоких.
- Выполните синтаксический разбор.
Практикум (индивидуальная работа-проверка в парах). Коллективное обсуждение.
Подчеркните однородные определения. Составьте схему.
Тишина простёрлась над белой и холодной Волгой._________________________________
Подчеркните однородные дополнения.
Ярко блестела и переливалась на солнце светлая зелень берёз и осин. Составьте схему.__________________________________
Обведите обращение.
Михаил, присоединяйся к нашему обсуждению!
Докажите, что это предложение сложное.
Капли дождя тихонько по листьям текли, шептались могучие деревья, а кукушка кричала вдали.
Практикум (самостоятельная работа-анализ заданий одноклассниками).
- Добавь в предложение подлежащее: Гремел________________________
- Добавь в предложение сказуемое: Месяц______________________ лес и речку.
- Добавь в предложение дополнение: Он был похож на ___________________.
- Добавь в предложение обстоятельство: Андрей _____________ помог другу.
- Добавь в предложение, тот второстепенный член, который ещё не использовал: __________берёза под моим окном.

Пакет
nltk.parse — документация NLTK 3.6
>>> from nltk.parse import DependencyGraph, DependencyEvaluator
>>> из nltk.parse.transitionparser import TransitionParser, Configuration, Transition
>>> gold_sent = DependencyGraph ("" "
... Экономичный JJ 2 ATT
... новости NN 3 SBJ
... имеет корень VBD 0
... маленький JJ 5 ATT
... эффект NN 3 OBJ
... на IN 5 ATT
... финансовый JJ 8 ATT
... рынки NNS 6 ПК
.... . 3 УЕ
... "" ")
>>> conf = Конфигурация (gold_sent)
##################### Проверить исходный элемент ###################### #
>>> print (',' .join (conf.extract_features ()))
STK_0_POS_TOP, BUF_0_FORM_Economic, BUF_0_LEMMA_Economic, BUF_0_POS_JJ, BUF_1_FORM_news, BUF_1_POS_NN, BUF_2_POS_VBD, BUF_3_POS_JJ
##################### Проверить переход ######################
Проверьте инициализированную конфигурацию
>>> print (conf)
Стек: [0] Буфер: [1, 2, 3, 4, 5, 6, 7, 8, 9] Дуги: []
Выполните некоторые проверки перехода для ARC-STANDARD
>>> операция = Переход ('стандарт дуги')
>>> операция.сдвиг (конф)
>>> operation.left_arc (conf, "ATT")
>>> operation.shift (conf)
>>> operation.left_arc (conf, "SBJ")
>>> operation.shift (conf)
>>> operation.shift (conf)
>>> operation.left_arc (conf, "ATT")
>>> operation.shift (conf)
>>> operation.shift (conf)
>>> operation.shift (conf)
>>> operation.left_arc (conf, "ATT")
Средняя проверка конфигурации и функций
>>> print (conf)
Стек: [0, 3, 5, 6] Буфер: [8, 9] Дуги: [(2, ‘ATT’, 1), (3, ‘SBJ’, 2), (5, ‘ATT’, 4) , (8, ‘ATT’, 7)]
>>> print (','.присоединиться (conf.extract_features ()))
STK_0_FORM_on, STK_0_LEMMA_on, STK_0_POS_IN, STK_1_POS_NN, BUF_0_FORM_markets, BUF_0_LEMMA_markets, BUF_0_POS_NNS, BUF_1_FORM_., BUF_1_PAT_., BUF_0_LDEP_0_LDEP
>>> operation.right_arc (conf, "ПК") >>> operation.right_arc (conf, "ATT") >>> operation.right_arc (conf, "OBJ") >>> operation.shift (conf) >>> operation.
 right_arc (conf, "PU")
>>> operation.right_arc (conf, "ROOT")
>>> operation.shift (conf)
right_arc (conf, "PU")
>>> operation.right_arc (conf, "ROOT")
>>> operation.shift (conf)
Завершенная проверка конфигурации
>>> print (conf)
Стек: [0] Буфер: [] Дуги: [(2, ‘ATT’, 1), (3, ‘SBJ’, 2), (5, ‘ATT’, 4), (8, ‘ATT’, 7 ), (6, ‘PC’, 8), (5, ‘ATT’, 6), (3, ‘OBJ’, 5), (3, ‘PU’, 9), (0, ‘ROOT’, 3 )]
Выполните некоторые проверки перехода для ARC-EAGER
>>> conf = Конфигурация (gold_sent)
>>> operation = Transition ('arc-eager')
>>> операция.сдвиг (конф)
>>> operation.left_arc (conf, 'ATT')
>>> operation.shift (conf)
>>> operation.left_arc (conf, 'SBJ')
>>> operation.right_arc (conf, 'ROOT')
>>> operation.shift (conf)
>>> operation.left_arc (conf, 'ATT')
>>> operation.right_arc (conf, 'OBJ')
>>> operation.right_arc (conf, 'ATT')
>>> operation.shift (conf)
>>> operation.left_arc (conf, 'ATT')
>>> operation.right_arc (conf, 'ПК')
>>> operation.reduce (conf)
>>> операция.уменьшить (конф)
>>> operation.reduce (conf)
>>> operation.right_arc (conf, 'PU')
>>> print (conf)
Стек: [0, 3, 9] Буфер: [] Дуги: [(2, 'ATT', 1), (3, 'SBJ', 2), (0, 'ROOT', 3), (5, ' ATT ', 4), (3,' OBJ ', 5), (5,' ATT ', 6), (8,' ATT ', 7), (6,' PC ', 8), (3,' ' ПУ ', 9)]
##################### Проверить функцию обучения ######################
A. Проверьте обучение ARC-STANDARD
>>> импортировать временный файл
>>> import os
>>> input_file = временный файл.NamedTemporaryFile (prefix = ’transition_parse.train’, dir = tempfile.gettempdir (), delete = False)
>>> parser_std = TransitionParser ('стандарт дуги')
>>> print (',' .join (parser_std._create_training_examples_arc_std ([gold_sent], input_file)))
Количество обучающих примеров: 1
Количество валидных (проективных) примеров: 1
SHIFT, LEFTARC: ATT, SHIFT, LEFTARC: SBJ, SHIFT, SHIFT, LEFTARC: ATT, SHIFT, SHIFT, SHIFT, LEFTARC: ATT, RIGHTARC: PC, RIGHTARC: ATT, RIGHTARC: OBJ, SHIFT PU, RIGHTARC: КОРЕНЬ, СДВИГ
>>> parser_std.поезд ([gold_sent], 'temp.
 arcstd.model', verbose = False)
Количество обучающих примеров: 1
Количество валидных (проективных) примеров: 1
>>> удалить (input_file.name)
arcstd.model', verbose = False)
Количество обучающих примеров: 1
Количество валидных (проективных) примеров: 1
>>> удалить (input_file.name)
Проверить курс обучения ARC-EAGER
>>> input_file = tempfile.NamedTemporaryFile (prefix = 'transition_parse.train', dir = tempfile.gettempdir (), delete = False)
>>> parser_eager = TransitionParser ('нетерпеливый')
>>> print (',' .join (parser_eager._create_training_examples_arc_eager ([gold_sent], input_file)))
Количество обучающих примеров: 1
Количество валидных (проективных) примеров: 1
SHIFT, LEFTARC: ATT, SHIFT, LEFTARC: SBJ, RIGHTARC: ROOT, SHIFT, LEFTARC: ATT, RIGHTARC: OBJ, RIGHTARC: ATT, SHIFT, LEFTARC: ATT, RIGHTARC: PC, REDUCE, REDUCE, REDUCE, REDUCE, REDUCE, REDUCE
>>> parser_eager.поезд ([gold_sent], 'temp.arceager.model', verbose = False) Количество обучающих примеров: 1 Количество валидных (проективных) примеров: 1
>>> удалить (имя_входного_файла)
##################### Проверка функции анализа ###################### #
Проверить парсер ARC-STANDARD
>>> результат = parser_std.parse ([gold_sent], 'temp.arcstd.model') >>> de = DependencyEvaluator (результат, [gold_sent]) >>> де.eval ()> = (0, 0) Правда
B. Проверьте парсер ARC-EAGER
>>> result = parser_eager.parse ([gold_sent], ‘temp.arceager.model’)
>>> de = DependencyEvaluator (результат, [gold_sent])
>>> de.eval ()> = (0, 0)
Правда
Удалить тестовые временные файлы
>>> remove (‘temp.arceager.model’)
>>> remove (‘temp.arcstd.model’)
Обратите внимание, что результат очень плохой из-за всего лишь одного обучающего примера.
java — NLTK -> Использование Стэнфордского анализатора зависимостей ->
Кажется, существует много противоречивой документации для NLTK (где окончательный источник документации NLTK / StanfordNLP?).
Мой вопрос: какой метод является предпочтительным для вызова StanfordParser из nltk? Это мой код, но что-то не так в вызове java.
из nltk.parse.stanford import StanfordDependencyParser
импорт ОС
parser_home = '/ Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 /'
# os.environ ['CLASSPATH'] = parser_home
parser = StanfordDependencyParser (
model_path = parser_home + 'stanford-parser.jar',
path_to_models_jar = parser_home + 'stanford-parser-3.9.1-models.jar ',
verbose = True
)
result = parser.raw_parse ('Вот пример предложения.')
Вот моя ошибка. Любая помощь приветствуется. Я не нашел точного совпадения со своим. Я устанавливаю путь к классам, но не уверен, что это требуется.
[Найдено stanford-parser \ .jar: /Users/myname/Documents/nlp/stanford-parser-full-2018-02-27/stanford-parser.jar]
[Найдено stanford-parser - (\ d +) (\. (\ D +)) + - models \ .jar: / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford-parser- 3.9.1-models.jar]
/Users/myname/anaconda3/envs/nlp/lib/python3.6/site-packages/ipykernel_launcher.py:12: DeprecationWarning: StanfordDependencyParser будет устаревшим
Вместо этого используйте nltk.parse.corenlp.StanforCoreNLPDependencyParser.
если sys.path [0] == '':
SLF4J: не удалось загрузить класс org.slf4j.impl.StaticLoggerBinder.
SLF4J: По умолчанию реализация регистратора без операции (NOP)
SLF4J: дополнительные сведения см. На http://www.slf4j.org/codes.html#StaticLoggerBinder.
Исключение в потоке "main" java.lang.RuntimeException: /Users/myname/Documents/nlp/stanford-parser-full-2018-02-27/stanford-parser.jar: ожидается блок BEGIN; получил PK��aL META-INF / ��PKPK��aLMETA-INF / MANIFEST.MFE��
в edu.stanford.nlp.parser.lexparser.LexicalizedParser.confirmBeginBlock (LexicalizedParser.java:536)
в edu.stanford.nlp.parser.lexparser.LexicalizedParser.getParserFromTextFile (LexicalizedParser.java:546)
в edu.stanford.nlp.parser.lexparser.LexicalizedParser.getParserFromFile (LexicalizedParser.java:406)
в edu.stanford.nlp.parser.lexparser.LexicalizedParser. loadModel (LexicalizedParser.java:186)
в edu.stanford.nlp.parser.lexparser.LexicalizedParser.main (LexicalizedParser.java:1400)
-------------------------------------------------- -------------------------
OSError Traceback (последний вызов последним)
в ()
----> 1 результат = parser.raw_parse ('Вот пример предложения.')
~ / anaconda3 / envs / nlp / lib / python3.6 / сайты-пакеты / nltk / parse / stanford.py в raw_parse (сам, предложение, подробный)
132: rtype: iter (Дерево)
133 "" "
-> 134 вернуться далее (self.raw_parse_sents ([предложение], подробный))
135
136 def raw_parse_sents (я, предложения, подробный = ложный):
~ / anaconda3 / envs / nlp / lib / python3.6 / site-packages / nltk / parse / stanford.py в raw_parse_sents (сам, предложения, подробный)
150 '-outputFormat', self._OUTPUT_FORMAT,
151]
-> 152 вернуть self._parse_trees_output (self._execute (cmd, '\ n'.присоединиться (предложения), подробный))
153
154 def tagged_parse (self, предложение, verbose = False):
~ / anaconda3 / envs / nlp / lib / python3.6 / site-packages / nltk / parse / stanford.py в _execute (self, cmd, input_, verbose)
216 cmd.append (имя_файла)
217 stdout, stderr = java (cmd, classpath = self._classpath,
-> 218 stdout = PIPE, stderr = PIPE)
219
220 стандартный вывод = стандартный вывод.replace (b '\ xc2 \ xa0', b '')
~ / anaconda3 / envs / nlp / lib / python3.6 / site-packages / nltk / __ init__.py в java (cmd, classpath, stdin, stdout, stderr, блокировка)
134, если p.returncode! = 0:
135 печать (_decode_stdoutdata (stderr))
-> 136 поднять OSError ('Ошибка команды Java:' + str (cmd))
137
138 возврат (stdout, stderr)
OSError: сбой команды Java: ['/ usr / bin / java', '-mx1000m', '-cp', '/ Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford- parser-3.9.1-models.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford-parser-3. 9.1-javadoc.jar: /Users/myname/Documents/nlp/stanford-parser-full-2018-02-27/ejml-0.23.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018- 02-27 / stanford-parser-3.9.1-sources.jar: /Users/myname/Documents/nlp/stanford-parser-full-2018-02-27/slf4j-api.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford-parser-3.9.1-models.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford-parser .jar: / Пользователи / мое имя / Документы / nlp / stanford-parser-full-2018-02-27 / slf4j-api-1.7.12-sources.jar ',' edu.stanford.nlp.parser.lexparser.LexicalizedParser ',' -model ',' / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford- parser.jar ',' -sentences ',' newline ',' -outputFormat ',' conll2007 ',' -encoding ',' utf8 ',' / var / folder / kg / y1g8nszj77z0pm6mzplqv7580000gp / T / tmp93uyyya_ ']
 loadModel (LexicalizedParser.java:186)
в edu.stanford.nlp.parser.lexparser.LexicalizedParser.main (LexicalizedParser.java:1400)
-------------------------------------------------- -------------------------
OSError Traceback (последний вызов последним)
loadModel (LexicalizedParser.java:186)
в edu.stanford.nlp.parser.lexparser.LexicalizedParser.main (LexicalizedParser.java:1400)
-------------------------------------------------- -------------------------
OSError Traceback (последний вызов последним)
 9.1-javadoc.jar: /Users/myname/Documents/nlp/stanford-parser-full-2018-02-27/ejml-0.23.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018- 02-27 / stanford-parser-3.9.1-sources.jar: /Users/myname/Documents/nlp/stanford-parser-full-2018-02-27/slf4j-api.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford-parser-3.9.1-models.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford-parser .jar: / Пользователи / мое имя / Документы / nlp / stanford-parser-full-2018-02-27 / slf4j-api-1.7.12-sources.jar ',' edu.stanford.nlp.parser.lexparser.LexicalizedParser ',' -model ',' / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford- parser.jar ',' -sentences ',' newline ',' -outputFormat ',' conll2007 ',' -encoding ',' utf8 ',' / var / folder / kg / y1g8nszj77z0pm6mzplqv7580000gp / T / tmp93uyyya_ ']
9.1-javadoc.jar: /Users/myname/Documents/nlp/stanford-parser-full-2018-02-27/ejml-0.23.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018- 02-27 / stanford-parser-3.9.1-sources.jar: /Users/myname/Documents/nlp/stanford-parser-full-2018-02-27/slf4j-api.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford-parser-3.9.1-models.jar: / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford-parser .jar: / Пользователи / мое имя / Документы / nlp / stanford-parser-full-2018-02-27 / slf4j-api-1.7.12-sources.jar ',' edu.stanford.nlp.parser.lexparser.LexicalizedParser ',' -model ',' / Users / myname / Documents / nlp / stanford-parser-full-2018-02-27 / stanford- parser.jar ',' -sentences ',' newline ',' -outputFormat ',' conll2007 ',' -encoding ',' utf8 ',' / var / folder / kg / y1g8nszj77z0pm6mzplqv7580000gp / T / tmp93uyyya_ ']
Анализ
— Как использовать Stanford Parser в NLTK с использованием Python
Начиная с NLTK v3.3, пользователям следует избегать тегов Stanford NER или POS из nltk.tag и избегают токенизатора / сегментера Stanford из nltk. tokenize .
Вместо этого используйте новый nltk.parse.corenlp.CoreNLPParser API.
См. Https://github.com/nltk/nltk/wiki/Stanford-CoreNLP-API-in-NLTK
(избегая ответа только по ссылке, я вставил документы из NLTK github wiki ниже)
Сначала обновите свой NLTK
pip3 install -U nltk # Убедитесь, что> = 3.3
Затем загрузите необходимые пакеты CoreNLP:
кд ~
wget http: // nlp.stanford.edu/software/stanford-corenlp-full-2018-02-27.zip
разархивируйте stanford-corenlp-full-2018-02-27.zip
cd stanford-corenlp-full-2018-02-27
# Получите китайскую модель
wget http://nlp.stanford.edu/software/stanford-chinese-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent. com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-chinese.properties
# Получите арабскую модель
wget http://nlp.stanford.edu/software/stanford-arabic-corenlp-2018-02-27-models.jar
wget https: // raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-arabic.properties
# Получите французскую модель
wget http://nlp.stanford.edu/software/stanford-french-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-french.properties
# Получите немецкую модель
wget http://nlp.stanford.edu/software/stanford-german-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-german.характеристики
# Получите испанскую модель
wget http://nlp.stanford.edu/software/stanford-spanish-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-spanish.properties
 com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-chinese.properties
# Получите арабскую модель
wget http://nlp.stanford.edu/software/stanford-arabic-corenlp-2018-02-27-models.jar
wget https: // raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-arabic.properties
# Получите французскую модель
wget http://nlp.stanford.edu/software/stanford-french-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-french.properties
# Получите немецкую модель
wget http://nlp.stanford.edu/software/stanford-german-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-german.характеристики
# Получите испанскую модель
wget http://nlp.stanford.edu/software/stanford-spanish-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-spanish.properties
com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-chinese.properties
# Получите арабскую модель
wget http://nlp.stanford.edu/software/stanford-arabic-corenlp-2018-02-27-models.jar
wget https: // raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-arabic.properties
# Получите французскую модель
wget http://nlp.stanford.edu/software/stanford-french-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-french.properties
# Получите немецкую модель
wget http://nlp.stanford.edu/software/stanford-german-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-german.характеристики
# Получите испанскую модель
wget http://nlp.stanford.edu/software/stanford-spanish-corenlp-2018-02-27-models.jar
wget https://raw.githubusercontent.com/stanfordnlp/CoreNLP/master/src/edu/stanford/nlp/pipeline/StanfordCoreNLP-spanish.properties
По-прежнему находится в каталоге stanford-corenlp-full-2018-02-27 , запустите сервер:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer \
-preload tokenize, ssplit, pos, lemma, ner, parse, depparse \
-status_port 9000 -port 9000 -timeout 15000 &
Затем в Python:
>>> из nltk.анализировать импорт CoreNLPParser
# Лексический парсер
>>> parser = CoreNLPParser (url = 'http: // localhost: 9000')
# Разобрать токенизированный текст.
>>> list (parser.parse ('Какая скорость у порожней ласточки?'. split ()))
[Дерево ('КОРЕНЬ', [Дерево ('SBARQ', [Дерево ('WHNP', [Дерево ('WP', ['Что']])]), Дерево ('SQ', [Дерево ('VBZ', ['is']), Tree ('NP', [Tree ('NP', [Tree ('DT', ['the'])), Tree ('NN', ['airspeed'])]), Tree ('PP', [Tree ('IN', ['of']), Tree ('NP', [Tree ('DT', ['an']), Tree ('JJ', ['unladen']) )])]), Tree ('S', [Tree ('VP', [Tree ('VB', ['ласточка'])])])])]), Tree ('. ', ['? '])])])]
# Разобрать необработанную строку.
>>> list (parser.raw_parse ('Какая скорость у порожней ласточки?'))
[Дерево ('КОРЕНЬ', [Дерево ('SBARQ', [Дерево ('WHNP', [Дерево ('WP', ['What'])])), Дерево ('SQ', [Дерево ('VBZ', ['is']), Tree ('NP', [Tree ('NP', [Tree ('DT', ['the'])), Tree ('NN', ['airspeed'])]), Tree ('PP', [Tree ('IN', ['of']), Tree ('NP', [Tree ('DT', ['an']), Tree ('JJ', ['unladen']) )])]), Tree ('S', [Tree ('VP', [Tree ('VB', ['swallow'])])])])]), Tree ('.', ['? '])])])]
# Парсер нейронных зависимостей
>>> от nltk.parse.corenlp импорт CoreNLPDependencyParser
>>> dep_parser = CoreNLPDependencyParser (url = 'http: // localhost: 9000')
>>> parses = dep_parser.parse ('Какая скорость у порожней ласточки?'. split ())
>>> [[(губернатор, деп, зависимый) для губернатора, деп, зависимый в parse.triples ()] для синтаксического анализа в синтаксическом анализе]
[[(('What', 'WP'), 'cop', ('is', 'VBZ')), (('What', 'WP'), 'nsubj', ('airspeed', 'NN ')), ((' воздушная скорость ',' NN '),' det ', (' the ',' DT ')), ((' airspeed ',' NN '),' nmod ', (' глотать ', 'VB')), (('ласточка', 'VB'), 'case', ('of', 'IN')), (('ласточка', 'VB'), 'det', ('an ',' DT ')), ((' глотать ',' VB '),' amod ', (' без груза ',' JJ ')), ((' Что ',' WP '),' punct ', ( '?', '.'))]]
# Токенизатор
>>> parser = CoreNLPParser (url = 'http: // localhost: 9000')
>>> list (parser.tokenize ('Какая скорость у порожней ласточки?'))
['What', 'is', 'the', 'airspeed', 'of', 'an', 'без нагрузки', 'ласточка', '?']
# POS Tagger
>>> pos_tagger = CoreNLPParser (url = 'http: // localhost: 9000', tagtype = 'pos')
>>> list (pos_tagger.tag ('Какая скорость у порожней ласточки?'. split ()))
[('What', 'WP'), ('is', 'VBZ'), ('the', 'DT'), ('airspeed', 'NN'), ('of', 'IN') , ('an', 'DT'), ('незагруженный', 'JJ'), ('ласточка', 'VB'), ('?', '.')]
# NER Tagger
>>> ner_tagger = CoreNLPParser (url = 'http: // localhost: 9000', tagtype = 'ner')
>>> list (ner_tagger.tag (('Рами Эйд учится в Университете Стоуни-Брук в Нью-Йорке'. split ())))
[('Rami', 'PERSON'), ('Eid', 'PERSON'), ('is', 'O'), ('учеба', 'O'), ('at', 'O') , ('Stony', 'ORGANIZATION'), ('Brook', 'ORGANIZATION'), ('University', 'ORGANIZATION'), ('in', 'O'), ('NY', 'STATE_OR_PROVINCE') ]
 ', ['? '])])])]
# Разобрать необработанную строку.
>>> list (parser.raw_parse ('Какая скорость у порожней ласточки?'))
[Дерево ('КОРЕНЬ', [Дерево ('SBARQ', [Дерево ('WHNP', [Дерево ('WP', ['What'])])), Дерево ('SQ', [Дерево ('VBZ', ['is']), Tree ('NP', [Tree ('NP', [Tree ('DT', ['the'])), Tree ('NN', ['airspeed'])]), Tree ('PP', [Tree ('IN', ['of']), Tree ('NP', [Tree ('DT', ['an']), Tree ('JJ', ['unladen']) )])]), Tree ('S', [Tree ('VP', [Tree ('VB', ['swallow'])])])])]), Tree ('.', ['? '])])])]
# Парсер нейронных зависимостей
>>> от nltk.parse.corenlp импорт CoreNLPDependencyParser
>>> dep_parser = CoreNLPDependencyParser (url = 'http: // localhost: 9000')
>>> parses = dep_parser.parse ('Какая скорость у порожней ласточки?'. split ())
>>> [[(губернатор, деп, зависимый) для губернатора, деп, зависимый в parse.triples ()] для синтаксического анализа в синтаксическом анализе]
[[(('What', 'WP'), 'cop', ('is', 'VBZ')), (('What', 'WP'), 'nsubj', ('airspeed', 'NN ')), ((' воздушная скорость ',' NN '),' det ', (' the ',' DT ')), ((' airspeed ',' NN '),' nmod ', (' глотать ', 'VB')), (('ласточка', 'VB'), 'case', ('of', 'IN')), (('ласточка', 'VB'), 'det', ('an ',' DT ')), ((' глотать ',' VB '),' amod ', (' без груза ',' JJ ')), ((' Что ',' WP '),' punct ', ( '?', '.'))]]
# Токенизатор
>>> parser = CoreNLPParser (url = 'http: // localhost: 9000')
>>> list (parser.tokenize ('Какая скорость у порожней ласточки?'))
['What', 'is', 'the', 'airspeed', 'of', 'an', 'без нагрузки', 'ласточка', '?']
# POS Tagger
>>> pos_tagger = CoreNLPParser (url = 'http: // localhost: 9000', tagtype = 'pos')
>>> list (pos_tagger.tag ('Какая скорость у порожней ласточки?'. split ()))
[('What', 'WP'), ('is', 'VBZ'), ('the', 'DT'), ('airspeed', 'NN'), ('of', 'IN') , ('an', 'DT'), ('незагруженный', 'JJ'), ('ласточка', 'VB'), ('?', '.')]
# NER Tagger
>>> ner_tagger = CoreNLPParser (url = 'http: // localhost: 9000', tagtype = 'ner')
>>> list (ner_tagger.tag (('Рами Эйд учится в Университете Стоуни-Брук в Нью-Йорке'.
', ['? '])])])]
# Разобрать необработанную строку.
>>> list (parser.raw_parse ('Какая скорость у порожней ласточки?'))
[Дерево ('КОРЕНЬ', [Дерево ('SBARQ', [Дерево ('WHNP', [Дерево ('WP', ['What'])])), Дерево ('SQ', [Дерево ('VBZ', ['is']), Tree ('NP', [Tree ('NP', [Tree ('DT', ['the'])), Tree ('NN', ['airspeed'])]), Tree ('PP', [Tree ('IN', ['of']), Tree ('NP', [Tree ('DT', ['an']), Tree ('JJ', ['unladen']) )])]), Tree ('S', [Tree ('VP', [Tree ('VB', ['swallow'])])])])]), Tree ('.', ['? '])])])]
# Парсер нейронных зависимостей
>>> от nltk.parse.corenlp импорт CoreNLPDependencyParser
>>> dep_parser = CoreNLPDependencyParser (url = 'http: // localhost: 9000')
>>> parses = dep_parser.parse ('Какая скорость у порожней ласточки?'. split ())
>>> [[(губернатор, деп, зависимый) для губернатора, деп, зависимый в parse.triples ()] для синтаксического анализа в синтаксическом анализе]
[[(('What', 'WP'), 'cop', ('is', 'VBZ')), (('What', 'WP'), 'nsubj', ('airspeed', 'NN ')), ((' воздушная скорость ',' NN '),' det ', (' the ',' DT ')), ((' airspeed ',' NN '),' nmod ', (' глотать ', 'VB')), (('ласточка', 'VB'), 'case', ('of', 'IN')), (('ласточка', 'VB'), 'det', ('an ',' DT ')), ((' глотать ',' VB '),' amod ', (' без груза ',' JJ ')), ((' Что ',' WP '),' punct ', ( '?', '.'))]]
# Токенизатор
>>> parser = CoreNLPParser (url = 'http: // localhost: 9000')
>>> list (parser.tokenize ('Какая скорость у порожней ласточки?'))
['What', 'is', 'the', 'airspeed', 'of', 'an', 'без нагрузки', 'ласточка', '?']
# POS Tagger
>>> pos_tagger = CoreNLPParser (url = 'http: // localhost: 9000', tagtype = 'pos')
>>> list (pos_tagger.tag ('Какая скорость у порожней ласточки?'. split ()))
[('What', 'WP'), ('is', 'VBZ'), ('the', 'DT'), ('airspeed', 'NN'), ('of', 'IN') , ('an', 'DT'), ('незагруженный', 'JJ'), ('ласточка', 'VB'), ('?', '.')]
# NER Tagger
>>> ner_tagger = CoreNLPParser (url = 'http: // localhost: 9000', tagtype = 'ner')
>>> list (ner_tagger.tag (('Рами Эйд учится в Университете Стоуни-Брук в Нью-Йорке'. split ())))
[('Rami', 'PERSON'), ('Eid', 'PERSON'), ('is', 'O'), ('учеба', 'O'), ('at', 'O') , ('Stony', 'ORGANIZATION'), ('Brook', 'ORGANIZATION'), ('University', 'ORGANIZATION'), ('in', 'O'), ('NY', 'STATE_OR_PROVINCE') ]
split ())))
[('Rami', 'PERSON'), ('Eid', 'PERSON'), ('is', 'O'), ('учеба', 'O'), ('at', 'O') , ('Stony', 'ORGANIZATION'), ('Brook', 'ORGANIZATION'), ('University', 'ORGANIZATION'), ('in', 'O'), ('NY', 'STATE_OR_PROVINCE') ]
Запустите сервер немного иначе, по-прежнему из каталога `stanford-corenlp-full-2018-02-27:
java -Xmx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer \
-serverProperties StanfordCoreNLP-chinese.properties \
-preload tokenize, ssplit, pos, lemma, ner, parse \
-status_port 9001 -port 9001 -timeout 15000
В Python:
>>> parser = CoreNLPParser ('http: // localhost: 9001')
>>> список (parser.tokenize (u '我 家 没有 电脑。'))
['我 家', '没有', '电脑', '。']
>>> список (parser.parse (parser.tokenize (u '我 家 没有 电脑。')))
[Дерево ('КОРЕНЬ', [Дерево ('IP', [Дерево ('IP', [Дерево ('NP', [Дерево ('NN', ['我 家'])]), Дерево ('VP', [Дерево ('VE', ['没有']), Дерево ('NP', [Дерево ('NN', ['电脑'])])])]), Дерево ('PU', ['。' ])])])]
Запустить сервер:
java -Xmx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer \
-serverProperties StanfordCoreNLP-arabic.properties \
-preload tokenize, ssplit, pos, parse \
-status_port 9005 -port 9005 -timeout 15000
В Python:
>>> из nltk.parse import CoreNLPParser
>>> parser = CoreNLPParser ('http: // localhost: 9005')
>>> text = u 'انا حامل'
# Парсер.
>>> parser.raw_parse (текст)
<объект list_iterator в 0x7f0d894c9940>
>>> список (parser.raw_parse (текст))
[Дерево ('КОРЕНЬ', [Дерево ('S', [Дерево ('NP', [Дерево ('PRP', ['انا'])])), Дерево ('NP', [Дерево ('NN', ['حامل'])])])])]
>>> список (parser.parse (parser.tokenize (текст)))
[Дерево ('КОРЕНЬ', [Дерево ('S', [Дерево ('NP', [Дерево ('PRP', ['انا'])])), Дерево ('NP', [Дерево ('NN', ['حامل'])])])])]
# Токенизатор / Сегментер.
>>> список (parser.tokenize (текст))
['انا', 'حامل']
# POS tagg
>>> pos_tagger = CoreNLPParser ('http: // localhost: 9005', tagtype = 'pos')
>>> список (pos_tagger. tag (parser.tokenize (текст)))
[('انا', 'PRP'), ('حامل', 'NN')]
# NER тег
>>> ner_tagger = CoreNLPParser ('http: // localhost: 9005', tagtype = 'ner')
>>> список (ner_tagger.тег (parser.tokenize (текст)))
[('انا', 'O'), ('حامل', 'O')]
 tag (parser.tokenize (текст)))
[('انا', 'PRP'), ('حامل', 'NN')]
# NER тег
>>> ner_tagger = CoreNLPParser ('http: // localhost: 9005', tagtype = 'ner')
>>> список (ner_tagger.тег (parser.tokenize (текст)))
[('انا', 'O'), ('حامل', 'O')]
tag (parser.tokenize (текст)))
[('انا', 'PRP'), ('حامل', 'NN')]
# NER тег
>>> ner_tagger = CoreNLPParser ('http: // localhost: 9005', tagtype = 'ner')
>>> список (ner_tagger.тег (parser.tokenize (текст)))
[('انا', 'O'), ('حامل', 'O')]
Запустить сервер:
java -Xmx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer \
-serverProperties StanfordCoreNLP-french.properties \
-preload tokenize, ssplit, pos, parse \
-status_port 9004 -port 9004 -timeout 15000
В Python:
>>> parser = CoreNLPParser ('http: // localhost: 9004')
>>> список (parser.parse ('Je suis enceinte'.split ()))
[Дерево ('КОРЕНЬ', [Дерево ('ОТПРАВЛЕН', [Дерево ('NP', [Дерево ('PRON', ['Je']), Дерево ('ГЛАГОЛ', ['suis']]), Дерево ( 'AP', [Дерево ('ADJ', ['enceinte'])])])])])]
>>> pos_tagger = CoreNLPParser ('http: // localhost: 9004', tagtype = 'pos')
>>> pos_tagger.тег ('Je suis enceinte'.split ())
[('Je', 'PRON'), ('suis', 'ГЛАГОЛ'), ('enceinte', 'ADJ')]
Запустить сервер:
java -Xmx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer \
-serverProperties StanfordCoreNLP-german.properties \
-preload tokenize, ssplit, pos, ner, parse \
-status_port 9002 -port 9002 -timeout 15000
В Python:
>>> parser = CoreNLPParser ('http: // localhost: 9002')
>>> список (parser.raw_parse ('ПЯ бин швангер'))
[Дерево ('КОРЕНЬ', [Дерево ('NUR', [Дерево ('S', [Дерево ('PPER', ['Ich']), Дерево ('VAFIN', ['bin']), Дерево ( 'AP', [Дерево ('ADJD', ['schwanger'])])])])])]
>>> список (parser.parse ('Ich bin schwanger'.split ()))
[Дерево ('КОРЕНЬ', [Дерево ('NUR', [Дерево ('S', [Дерево ('PPER', ['Ich']), Дерево ('VAFIN', ['bin']), Дерево ( 'AP', [Дерево ('ADJD', ['schwanger'])])])])])]
>>> pos_tagger = CoreNLPParser ('http: // localhost: 9002', tagtype = 'pos')
>>> pos_tagger.tag ('Ich bin schwanger'.split ())
[('Ich', 'PPER'), ('bin', 'VAFIN'), ('schwanger', 'ADJD')]
>>> pos_tagger = CoreNLPParser ('http: // localhost: 9002', tagtype = 'pos')
>>> pos_tagger. tag ('Ich bin schwanger'.split ())
[('Ich', 'PPER'), ('bin', 'VAFIN'), ('schwanger', 'ADJD')]
>>> ner_tagger = CoreNLPParser ('http: // localhost: 9002', tagtype = 'ner')
>>> ner_tagger.tag ('Дональд Трамп обесценил Ангелу Меркель в Берлине.'. split ())
[('Дональд', 'ЧЕЛОВЕК'), ('Трамп', 'ЛИЦО'), ('besuchte', 'О'), ('Ангела', 'ЛИЦО'), ('Меркель', 'ЛИЦО') , ('in', 'O'), ('Berlin', 'LOCATION'), ('.', 'O')]
 tag ('Ich bin schwanger'.split ())
[('Ich', 'PPER'), ('bin', 'VAFIN'), ('schwanger', 'ADJD')]
>>> ner_tagger = CoreNLPParser ('http: // localhost: 9002', tagtype = 'ner')
>>> ner_tagger.tag ('Дональд Трамп обесценил Ангелу Меркель в Берлине.'. split ())
[('Дональд', 'ЧЕЛОВЕК'), ('Трамп', 'ЛИЦО'), ('besuchte', 'О'), ('Ангела', 'ЛИЦО'), ('Меркель', 'ЛИЦО') , ('in', 'O'), ('Berlin', 'LOCATION'), ('.', 'O')]
tag ('Ich bin schwanger'.split ())
[('Ich', 'PPER'), ('bin', 'VAFIN'), ('schwanger', 'ADJD')]
>>> ner_tagger = CoreNLPParser ('http: // localhost: 9002', tagtype = 'ner')
>>> ner_tagger.tag ('Дональд Трамп обесценил Ангелу Меркель в Берлине.'. split ())
[('Дональд', 'ЧЕЛОВЕК'), ('Трамп', 'ЛИЦО'), ('besuchte', 'О'), ('Ангела', 'ЛИЦО'), ('Меркель', 'ЛИЦО') , ('in', 'O'), ('Berlin', 'LOCATION'), ('.', 'O')]
Запустить сервер:
java -Xmx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer \
-serverProperties StanfordCoreNLP-spanish.properties \
-preload tokenize, ssplit, pos, ner, parse \
-status_port 9003 -port 9003 -timeout 15000
В Python:
>>> pos_tagger = CoreNLPParser ('http: // localhost: 9003', tagtype = 'pos')
>>> pos_tagger.tag (u'Barack Obama salió con Michael Jackson. '. split ())
[('Barack', 'PROPN'), ('Obama', 'PROPN'), ('salió', 'VERB'), ('con', 'ADP'), ('Michael', 'PROPN') , ('Джексон', 'ПРОПН'), ('.',' PUNCT ')]
>>> ner_tagger = CoreNLPParser ('http: // localhost: 9003', tagtype = 'ner')
>>> ner_tagger.tag (u'Barack Obama salió con Michael Jackson. '. split ())
[('Barack', 'PERSON'), ('Obama', 'PERSON'), ('salió', 'O'), ('con', 'O'), ('Michael', 'PERSON') , ('Джексон', 'ЛИЦО'), ('.', 'O')]
yzhangcs / parser: Коллекция современных моделей для синтаксического анализа зависимостей, постоянного и семантического анализа зависимостей.
SuPar предоставляет набор современных моделей синтаксического анализа с Biaffine Parser (Dozat and Manning, 2017) в качестве базовой архитектуры:
Вы можете загрузить выпущенные предварительно обученные модели для вышеуказанных синтаксических анализаторов и очень удобно получить деревья синтаксического анализа зависимостей / постоянных участников, как подробно описано в разделе Использование.
В этот пакет также интегрированы реализации нескольких популярных и хорошо известных алгоритмов, таких как MST (ChuLiu / Edmonds), Eisner, CKY, MatrixTree, TreeCRF.
Помимо встраивания тегов POS, используемых обычным синтаксическим анализатором Biaffine в качестве вспомогательных входов для кодировщика, опционально SuPar также позволяет использовать слои CharLSTM / BERT для создания функций уровня символа / подслова.
Среди них CharLSTM выбран в качестве опции по умолчанию, что позволяет избежать дополнительных требований для создания тегов POS, а также неэффективности BERT.Модуль BERT в SuPar извлекает представления BERT из предварительно обученной модели в трансформаторах .
Он также совместим с другими языковыми моделями, такими как XLNet, RoBERTa, ELECTRA и т. Д.
Модели CRF для анализа зависимостей / постоянных групп — это наши недавние работы, опубликованные в ACL 2020 и IJCAI 2020 соответственно.
Если они вам интересны, просьба указать:
@inproceedings {zhang-etal-2020-effective,
title = {Эффективный {T} ree {CRF} второго порядка для анализа нейронных зависимостей},
author = {Чжан, Ю и Ли, Чжэнхуа и Чжан Минь},
booktitle = {Протоколы ACL},
год = {2020},
url = {https: // www.aclweb.org/anthology/2020.acl-main.302},
pages = {3295–3305}
}
@inproceedings {zhang-etal-2020-fast,
title = {Быстрый и точный анализ нейронных {CRF} групп},
author = {Чжан, Ю и Чжоу, Хоуцюань и Ли, Чжэнхуа},
booktitle = {Протоколы IJCAI},
год = {2020},
doi = {10.24963 / ijcai.2020 / 560},
url = {https://doi.org/10.24963/ijcai.2020/560},
страницы = {4046-4053}
} Содержание
Установка
SuPar может быть установлен через pip:
Или также разрешена установка из исходников:
$ git clone https: // github.com / yzhangcs / parser && cd parser $ python setup.py установить
В качестве предварительного условия должны быть выполнены следующие требования:
Производительность
В настоящее время SuPar предоставляет предварительно обученные модели для английского и китайского языков.
Английские модели обучаются на Penn Treebank (PTB) с 39 832 обучающими предложениями, тогда как китайские модели обучаются на Penn Chinese Treebank версии 7 (CTB7) с 46 572 обучающими предложениями.
Производительность и скорость анализа этих моделей указаны в следующей таблице.Примечательно, что пунктуация игнорируется во всех оценочных показателях для PTB, но зарезервирована для CTB7.
| Набор данных | Тип | Имя | Метрическая | Производительность | Скорость (Sents / s) | |
|---|---|---|---|---|---|---|
| PTB | Зависимость | biaffine-dep-en | UAS / LAS | 96,03 | 94,37 | 1826.77 |
biaffine-dep-bert-en | UAS / LAS | 96,69 | 95,15 | 646,66 | ||
crfnp-dep-en | UAS / LAS | 96,01 | 94,42 | 2197,15 | ||
crf-dep-en | UAS / LAS | 96,12 | 94,50 | 652,41 | ||
crf2o-dep-en | UAS / LAS | 96.14 | 94,55 | 465,64 | ||
| Округ | crf-con-en | Ф. 1 | 94,18 | 923,74 | ||
crf-con-bert-en | Ф. 1 1 | 95,26 | 503,99 | |||
| CTB7 | Зависимость | биаффин-деп-ж | UAS / LAS | 88.77 | 85,63 | 1155,50 |
биаффин-деп-берт-ж | UAS / LAS | 91,81 | 88,94 | 395,28 | ||
crfnp-dep-zh | UAS / LAS | 88,78 | 85,64 | 1323,75 | ||
crf-dep-zh | UAS / LAS | 88,98 | 85,84 | 354.65 | ||
crf2o-dep-zh | UAS / LAS | 89,35 | 86,25 | 217,09 | ||
| Округ | crf-con-zh | Ф. 1 | 88,67 | 639,27 | ||
crf-con-bert-zh | Ф. 1 | 91,40 | 300,15 | |||
Все результаты протестированы на машине с процессором Intel (R) Xeon (R) CPU E5-2650 v4 @ 2.20 ГГц и графический процессор Nvidia GeForce GTX 1080 Ti.
Использование
SuPar очень прост в использовании. Вы можете загрузить предварительно обученную модель и запустить синтаксический анализ предложений с помощью нескольких строк кода:
>>> из supar import Parser
>>> parser = Parser.load ('biaffine-dep-en')
>>> dataset = parser.predict ([['Она', 'любит', 'играет', 'теннис', '. ']], prob = True, verbose = False)
100% | ################################################################################### | 1/1 00:00 <00:00, 85.15ит / с  ']], prob = True, verbose = False)
100% | ################################################################################### | 1/1 00:00 <00:00, 85.15ит / с
']], prob = True, verbose = False)
100% | ################################################################################### | 1/1 00:00 <00:00, 85.15ит / с Вызов parser.predict вернет экземпляр supar.utils.Dataset , содержащий предсказанные синтаксические деревья.
Для синтаксического анализа зависимостей вы можете получить доступ к каждому предложению, содержащемуся в наборе данных , или к отдельному полю всех деревьев.
>>> печать (набор данных. Предложения [0])
1 Она _ _ _ _ 2 nsubj _ _
2 пользуется _ _ _ _ 0 root _ _
3 играет _ _ _ _ 2 xcomp _ _
4 теннис _ _ _ _ 3 добдж _ _
5._ _ _ _ 2 пункта _ _
>>> print (f "arcs: {dataset.arcs [0]} \ n"
f "rels: {dataset.rels [0]} \ n"
f "probs: {dataset.probs [0] .gather (1, torch.tensor (dataset.arcs [0]). unsqueeze (1)). squeeze (-1)}")
дуги: [2, 0, 2, 3, 2]
rels: ['nsubj', 'root', 'xcomp', 'dobj', 'punct']
probs: тензор ([1.0000, 0.9999, 0.9642, 0.9686, 0.9996]) Вероятности могут быть возвращены вместе с результатами, если prob = True .
Что касается парсеров CRF, маргиналы доступны, если mbr = True , т.е.е., используя декодирование MBR.
Обратите внимание, что для SuPar требуются предварительно размеченные предложения в качестве входных данных.
Если вы хотите проанализировать не токенизированные необработанные тексты, вы можете позвонить nltk.word_tokenize , чтобы сначала выполнить токенизацию:
>>> импорт nltk
>>> text = nltk.word_tokenize ('Ей нравится играть в теннис.')
>>> print (parser.predict ([текст], verbose = False) .sentences [0])
100% | ################################################################################### | 1/1 00:00 <00:00, 74,20ит / с
1 Она _ _ _ _ 2 nsubj _ _
2 пользуется _ _ _ _ 0 root _ _
3 играет _ _ _ _ 2 xcomp _ _
4 теннис _ _ _ _ 3 добдж _ _
5._ _ _ _ 2 пункта _ _ Если есть много предложений для синтаксического анализа, SuPar также поддерживает их загрузку из файла и сохранение в файл pred , если это указано.
>>> набор данных = parser.predict ('данные / ptb / test.conllx', pred = 'pred.conllx')
2020-07-25 18:13:50 ИНФОРМАЦИЯ Загрузка данных
2020-07-25 18:13:52 ИНФОРМАЦИЯ
Набор данных (n_sentences = 2416, n_batches = 13, n_buckets = 8)
2020-07-25 18:13:52 INFO Создание прогнозов на основе набора данных
100% | ################################################################################### | 13/13 00:01 <00:00, 10.58ит / с
2020-07-25 18:13:53 ИНФОРМАЦИЯ Сохранение предсказанных результатов в pred.conllx
2020-07-25 18:13:54 ИНФОРМАЦИЯ 0: 00: 01.335261 с истекло, 1809.38 отправлено / с Убедитесь, что файл имеет формат CoNLL-X. Если некоторые поля отсутствуют, вы можете использовать символы подчеркивания в качестве заполнителей.
Предоставляется интерфейс для преобразования текста в строку формата CoNLL-X.
>>> из supar.utils import CoNLL >>> print (CoNLL.toconll (['Она', 'любит', 'играет', 'теннис', '.'])) 1 Она _ _ _ _ _ _ _ _ 2 пользуется _ _ _ _ _ _ _ _ 3 играет _ _ _ _ _ _ _ _ 4 теннис _ _ _ _ _ _ _ _ 5._ _ _ _ _ _ _ _
Для универсальных зависимостей (UD) также разрешен файл CoNLL-U, в то время как строки комментариев в файле могут быть зарезервированы перед предсказанием и восстановлены во время постобработки.
>>> импорт ОС >>> импортировать временный файл >>> text = '' '# text = Но мне понравилось это место, а соседи очень добры. 1 \ tНо \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 2 \ tI \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 3 \ tfound \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 4 \ t \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 5 \ t расположение \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 6 \ twonderful \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 7 \ tи \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 7.1 \ tfound \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 8 \ t \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 9 \ tсоседи \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 10 \ tvery \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 11 \ tkind \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ 12 \ t.
 \ T_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_
'' '
>>> путь = os.path.join (tempfile.mkdtemp (), 'data.conllx')
>>> с open (path, 'w') как f:
... f.write (текст)
...
>>> print (parser.predict (path, verbose = False) .sentences [0])
100% | ################################################################################### | 1/1 00:00 <00:00, 68,60ит / с
# text = Но я нашел это место чудесным, а соседи очень добрыми.1 Но _ _ _ _ 3 куб.
2 I _ _ _ _ 3 nsubj _ _
3 найдено _ _ _ _ 0 корень _ _
4 _ _ _ _ 5 det _ _
5 место _ _ _ _ 6 nsubj _ _
6 замечательных _ _ _ _ 3 xcomp _ _
7 и _ _ _ _ 6 куб.
7.1 найдено _ _ _ _ _ _ _ _
8 _ _ _ _ 9 det _ _
9 соседей _ _ _ _ 11 деп _ _
10 очень _ _ _ _ 11 advmod _ _
11 род _ _ _ _ 6 кон _ _
12. _ _ _ _ 3 пункта _ _
\ T_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_ \ t_
'' '
>>> путь = os.path.join (tempfile.mkdtemp (), 'data.conllx')
>>> с open (path, 'w') как f:
... f.write (текст)
...
>>> print (parser.predict (path, verbose = False) .sentences [0])
100% | ################################################################################### | 1/1 00:00 <00:00, 68,60ит / с
# text = Но я нашел это место чудесным, а соседи очень добрыми.1 Но _ _ _ _ 3 куб.
2 I _ _ _ _ 3 nsubj _ _
3 найдено _ _ _ _ 0 корень _ _
4 _ _ _ _ 5 det _ _
5 место _ _ _ _ 6 nsubj _ _
6 замечательных _ _ _ _ 3 xcomp _ _
7 и _ _ _ _ 6 куб.
7.1 найдено _ _ _ _ _ _ _ _
8 _ _ _ _ 9 det _ _
9 соседей _ _ _ _ 11 деп _ _
10 очень _ _ _ _ 11 advmod _ _
11 род _ _ _ _ 6 кон _ _
12. _ _ _ _ 3 пункта _ _ Деревья избирательных округов можно анализировать аналогичным образом.Возвращенный набор данных содержит все предсказанные деревья, представленные с использованием объектов nltk.Tree .
>>> parser = Parser.load ('crf-con-en')
>>> dataset = parser.predict ([['Она', 'любит', 'играет', 'теннис', '.']], verbose = False)
100% | ################################################################################### | 1/1 00:00 <00:00, 75,86 бит / с
>>> print (f "деревья: \ n {dataset.trees [0]}")
деревья:
(ВЕРШИНА
(S
(НП (_ Она))
(VP (_ наслаждается) (S (VP (_ играет) (NP (_ теннис)))))
(_.)))
>>> набор данных = парсер.предсказать ('data / ptb / test.pid', pred = 'pred.pid')
2020-07-25 18:21:28 ИНФОРМАЦИЯ Загрузка данных
2020-07-25 18:21:33 ИНФОРМАЦИЯ
Набор данных (n_sentences = 2416, n_batches = 13, n_buckets = 8)
2020-07-25 18:21:33 INFO Создание прогнозов на основе набора данных
100% | ################################################################################### | 13/13 00:02 <00:00, 5,30ит / с
2020-07-25 18:21:36 ИНФОРМАЦИЯ Сохранение прогнозируемых результатов в pred.pid
2020-07-25 18:21:36 ИНФОРМАЦИЯ 0: 00: 02.455740 с истекло, 983.82 отправлено / с Аналогично синтаксическому анализу зависимостей, предложение может быть преобразовано в пустой nltk. удобно: Дерево
Дерево
>>> из дерева импорта supar.utils >>> print (Tree.totree (['Она', 'любит', 'играет', 'теннис', '.'], root = 'TOP')) (TOP (_ Она) (_ любит) (_ играет) (_ теннис) (_.))
Обучение
Для обучения модели с нуля предпочтительно использовать параметр командной строки, который является более гибким и настраиваемым.
Вот несколько примеров обучения:
# Синтаксический анализатор зависимостей Biaffine
# некоторые общие аргументы и аргументы по умолчанию хранятся в config.ini
$ python -m supar.cmds.biaffine_dependency train -b -d 0 \
-c config.ini \
-p exp / ptb.biaffine.dependency.char / модель \
-f char
# для использования BERT необходимо указать `-f` и` --bert` (по умолчанию bert-base-cased)
# если вы хотите использовать XLNet, вы можете ввести `--bert xlnet-base-cased`
$ python -m supar.cmds.biaffine_dependency train -b -d 0 \
-p exp / ptb.biaffine.dependency.bert / модель \
-f bert \
--берт берт-цоколь
# CRF Dependency Parser
# для парсеров зависимостей CRF вы должны использовать `--proj`, чтобы отбросить все непроективные обучающие экземпляры
# опционально, вы можете использовать `--mbr` для выполнения декодирования MBR
$ python -m supar.cmds.crf_dependency поезд -b -d 0 \
-p exp / ptb.crf.dependency.char / модель \
-f char \
--mbr \
--proj
# CRF Parser Constituency Parser
# обучение парсера постоянных клиентов CRF ведет себя как парсеры зависимостей
$ python -m supar.cmds.crf_constituency train -b -d 0 \
-p exp / ptb.crf.constituency.char / model -f char \
--mbr Для получения дополнительных инструкций по обучению введите python -m supar.cmds. .
В качестве альтернативы, SuPar предоставляет некоторые эквивалентные точки ввода команд, зарегистрированные в настройке .py :
biaffine-dependency , crfnp-dependency , crf-dependency , crf2o-dependency и crf-constituency .
$ biaffine-dependency train -b -d 0 -c config.ini -p exp / ptb.biaffine.dependency.char / model -f char
Для работы с большими моделями также поддерживается распределенное обучение:
$ python -m torch.distributed.launch --nproc_per_node = 4 --master_port = 10000 \
-m supar.cmds.biaffine_dependency train -b -d 0,1,2,3 \
-p exp / ptb.biaffine.dependency.char / модель \
-f char Для получения дополнительных сведений обратитесь к документации и руководствам PyTorch.
Оценка
Процесс оценки похож на прогноз:
>>> parser = Parser.load ('biaffine-dep-en')
>>> потеря, метрика = parser.evaluate ('data / ptb / test.conllx')
2020-07-25 20:59:17 ИНФОРМАЦИЯ Загрузка данных
2020-07-25 20:59:19 ИНФОРМАЦИЯ
Набор данных (n_sentences = 2416, n_batches = 11, n_buckets = 8)
2020-07-25 20:59:19 ИНФОРМАЦИЯ Оценка набора данных
2020-07-25 20:59:20 ИНФО проигрыш: 0.2326 - UCM: 61,34% LCM: 50,21% UAS: 96,03% LAS: 94,37%
2020-07-25 20:59:20 ИНФОРМАЦИЯ 0: 00: 01,253601 с истекло, 1927,25 отправлений / с TODO
Список литературы
- Тимоти Дозат и Кристофер Д. Мэннинг. 2017. Глубокое внимание Биаффина к синтаксическому анализу нейронных зависимостей.
- Тао Цзи, Юаньбинь У и Ман Лан. 2019. Анализ зависимостей на основе графов с помощью графических нейронных сетей.
- Терри Ку, Амир Глоберсон, Ксавье Каррерас и Майкл Коллинз. 2007. Структурированные модели прогнозирования с помощью теоремы о дереве матрицы.
- Сюэчжэ Ма и Эдуард Хови. 2017. Нейронно-вероятностная модель для непроективного анализа MST.
- Сюэчжэ Ма, Цзеконг Ху, Цзинчжоу Лю, Нанюн Пэн, Грэм Нойбиг и Эдуард Хови. 2018. Сети с указателями стека для анализа зависимостей.
- Синью Ван, Цзинсянь Хуан и Кэвэй Ту. 2019. Анализ семантических зависимостей второго порядка с помощью сквозных нейронных сетей.
- Юй Чжан, Хоуцюань Чжоу и Чжэнхуа Ли. 2020. Быстрый и точный нейронный синтаксический анализ CRF.
- Ю Чжан, Чжэнхуа Ли и Минь Чжан. 2020. Эффективный TreeCRF второго порядка для анализа нейронных зависимостей.

Эрланг - yecc
Комментарии в стиле Erlang, начинающиеся с '%', являются
разрешено в файлах грамматики.
Каждое объявление или правило заканчивается точкой (
персонаж '.').
Грамматика начинается с необязательного раздела заголовка. В
заголовок помещается первым в сгенерированном файле, перед модулем
декларация.Цель заголовка - предоставить средства для
сделать документацию, созданную EDoc, лучше. Каждый
строка заголовка должна быть заключена в двойные кавычки, а символы новой строки
будет вставлен между строками. Например:
Заголовок "%% Copyright (C)" "%% @частный" "%% @ Автор Джон".
Далее следует объявление нетерминальных категорий.
для использования в правилах. Например:
Нетерминальное предложение глагольная фраза существительное.
Нетерминальная категория может использоваться в левой части (=
lhs, или глава) правила грамматики.Он также может
появляются справа от правил.
Далее следует объявление категорий терминалов,
которые представляют собой категории токенов, производимых сканером. Для
пример:
Терминалы артикль прилагательное существительное глагол.
Категории терминалов могут появляться только в правой части (=
rhs) правил грамматики.
Далее следует объявление символа корня или начала
категория грамматики. Например:
Этот символ должен появляться в левой части хотя бы одной грамматики.
правило.Это самая общая синтаксическая категория, которую
parser в конечном итоге проанализирует каждую входную строку в.
После объявления rootymbol следует необязательное объявление
символа end_of_input, который ожидается от вашего сканера
использовать. Например:
Например:
Далее следует одно или несколько объявлений приоритетов операторов, если необходимо. Они используются для решения
конфликты сдвига / уменьшения (см. документацию yacc).
Примеры заявлений оператора:
Правый 100 '='.Nonassoc 200 '==' '= / ='. Осталось 300 '+'. Осталось 400 '*'. Унарный 500 '-'.
Эти объявления означают, что '=' определяется как
правоассоциативный бинарный оператор с приоритетом 100,
'==' и '= / =' - операторы без ассоциативности, '+' и '*' - левоассоциативные бинарные операторы, где '*' принимает
приоритет над '+' (нормальный случай), а '-'
унарный оператор с более высоким приоритетом, чем '*'.
Тот факт, что '==' не имеет ассоциативности, означает, что выражение
как a == b == c считается синтаксической ошибкой.
Определенным правилам назначается приоритет: каждое правило получает свой
приоритет от последнего терминального символа, упомянутого справа
стороны правила. Также можно объявить приоритет
для нетерминалов - «на один уровень выше». Это практично, когда
оператор перегружен (см. также пример 3 ниже).
Далее следуют грамматические правила. Каждое правило имеет общее
форма
Левая_сторона -> Правая_сторона: связанный_код.
Левая часть - нетерминальная категория.Правая рука
сторона - это последовательность из одного или нескольких нетерминальных или оконечных
символы с пробелами между ними. Соответствующий код представляет собой последовательность
из нуля или более выражений Erlang (с запятыми ',' как
разделители). Если связанный код пуст, разделяющий
двоеточие ':' также опускается. Последняя точка отмечает конец
правило.
Такие символы, как '{', '.' И т. Д., Должны быть
заключен в одинарные кавычки, когда используется как терминал или нет
символы в правилах грамматики.Использование символов
'$ empty', '$ end' и '$ undefined' должны
избегать.
Последняя часть файла грамматики - это необязательный раздел с
Код Erlang (= определения функций), который включен "как есть"
в получившемся файле парсера. Этот раздел должен начинаться с
псевдодекларация, или ключевые слова
Никакие определения правил синтаксиса или другие объявления не могут следовать
эта секция. Чтобы избежать конфликтов с внутренними переменными, не
используйте имена переменных, начинающиеся с двух символов подчеркивания
('__') в коде Erlang в этом разделе или в коде
связанные с отдельными правилами синтаксиса.
Необязательное объявление ожидаемого значения может быть размещено где угодно
перед последним необязательным разделом с кодом Erlang. Это использовано
для подавления предупреждения о конфликтах, которое обычно
дается, если грамматика неоднозначна. Пример:
Предупреждение выдается, если количество конфликтов сдвига / уменьшения
отличается от 2, или если есть конфликты уменьшения / уменьшения.
bllipparser · PyPI
Синтаксический анализатор BLLIP (также известный как синтаксический анализатор Чарняка-Джонсона или
Brown Reranking Parser) описан в статье Чарняка.
и Джонсон (Ассоциация компьютерной лингвистики, 2005).Этот пакет
предоставляет среду выполнения синтаксического анализатора BLLIP вместе с интерфейсом Python. Примечание
что он не поставляется с моделями синтаксического анализа, но включает модель
загрузчик. Первичное обслуживание парсера происходит по адресу
GitHub.
Мы просим упоминания в любых публикациях, в которых это
программное обеспечение и любой код, полученный из этого программного обеспечения. Пожалуйста, сообщите
дата выпуска программного обеспечения, которое вы используете, так как это позволит
другие, чтобы сравнить свои результаты с вашими.
Основное использование
Основным классом в bllipparser является класс парсера RerankingParser.
который обеспечивает интерфейс для парсера первого этапа и второго этапа
перерейранкер. Самый простой способ создать объект RerankingParser - это
Самый простой способ создать объект RerankingParser - это
с помощью fetch_and_load (см. выше) или from_unified_model_dir
методы класса. Единая модель - это каталог, содержащий два
подкаталоги: parser / и reranker /, каждый с соответствующими
файлы моделей:
>>> из bllipparser import RerankingParser
>>> rrp = RerankingParser.from_unified_model_dir ('/ путь / к / модели /')
Если вам нужен только наиболее вероятный синтаксический анализ предложения в Penn Treebank
формат, используйте метод simple_parse ():
>>> rrp.simple_parse ('Это просто.')
'(S1 (S (NP (DT This)) (VP (VBZ есть) (ADJP (JJ простой))) (..)))'
Если вам нужна дополнительная информация о синтаксическом анализе, вы можете использовать
parse (), который возвращает объект NBestList. Парсер
производит n-лучший список из n наиболее вероятных синтаксических разборов предложения
(по умолчанию: n = 50 ). Обычно вам нужен только верхний синтаксический анализ, а остальные
также есть в наличии:
>>> nbest_list = rrp.parse ('Это предложение.')
Чтобы получить информацию о верхнем синтаксическом анализе (обратите внимание, что ptb_parse
property - это объект Tree, более подробно описанный ниже):
>>> печать (repr (nbest_list [0]))
ScoredParse ('(S1 (S (NP (DT This)) (VP (VBZ) (NP (DT a) (предложение NN))) (.)))', Parser_score = -29.620656470412328, reranker_score = -7.13760513405013)
>>> print (nbest_list [0] .ptb_parse)
(S1 (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (NN предложение))) (..)))
>>> print (nbest_list [0] .parser_score)
-29.6206564704
>>> print (nbest_list [0] .reranker_score)
-7.13760513405
>>> печать (len (nbest_list))
50
Синтаксическое слияние можно выполнить с помощью метода fuse (). Этот
объединяет синтаксические анализы из n-лучшего списка в одно дерево (которое
может быть синтаксический анализ, уже присутствующий в списке n-лучших или новый):
>>> печать (nbest_list.
 fuse ())
(S1 (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (NN предложение))) (..)))
fuse ())
(S1 (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (NN предложение))) (..)))
Если у вас есть пакет PyStanfordDependencies,
вы можете выполнить синтаксический анализ прямо в Stanford Dependencies:
>>> tokens = nbest_list [0].ptb_parse.sd_tokens () >>> для токена в токенах: ... печать (токен) ... Токен (index = 1, form = u'This ', cpos = u'DT', pos = u'DT ', head = 4, deprel = u'nsubj') Токен (индекс = 2, form = u'is ', cpos = u'VBZ', pos = u'VBZ ', head = 4, deprel = u'cop') Токен (индекс = 3, form = u'a ', cpos = u'DT', pos = u'DT ', head = 4, deprel = u'det') Токен (index = 4, form = u'sentence ', cpos = u'NN', pos = u'NN ', head = 0, deprel = u'root') Токен (индекс = 5, form = u '.', Cpos = u '.', Pos = u '.', Head = 4, deprel = u'punct ')
Будет предпринята попытка использовать конвертер по умолчанию, но см. Документацию о том, как
настроить преобразование зависимостей (или если вы столкнетесь с проблемами версии Java).
Если у вас есть существующий токенизатор, можно также указать токенизацию
передавая список строк:
>>> nbest_list = rrp.parse (['Это', 'есть', 'a', 'предварительно токенизировано', 'предложение', '.'])
Если вы хотите отключить повторное ранжирование (снижает точность, поэтому обычно не
готово), установите rerank = False:
>>> nbest_list = rrp.parse ('Только парсер!', Rerank = False)
Вы также можете анализировать текст с помощью существующих тегов POS (они действуют как мягкие
ограничения).В этом примере токен 0 («Время») должен иметь тег VB и
токен 1 («мухи») должен иметь тег NNS:
.
>>> rrp.parse_tagged (['Время', 'летит'], possible_tags = {0: 'VB', 1: 'NNS'}) [0]
ScoredParse ('(S1 (NP (VB Time) (NNS летает)))', parser_score = -54.05083561918019, reranker_score = -15.079632500107973)
Необязательно указывать тег для всех слов: здесь токен 0 («Время») должен
иметь тег VB и токен 1 («летает») не ограничен:
>>> rrp.parse_tagged (['Время', 'летит'], possible_tags = {0: 'VB'}) [0]
ScoredParse ('(S1 (S (VP (VB Time) (NP (VBZ летает)))))', parser_score = -54. 3497715 5750189, reranker_score = -16.681734375725263)
 3497715 5750189, reranker_score = -16.681734375725263)
3497715 5750189, reranker_score = -16.681734375725263)
Для каждого токена можно указать несколько тегов. Когда вы это сделаете,
теги для токена будут использоваться для уменьшения приоритета. токен 0 («Время»)
должен иметь тег VB, JJ или NN, а токен 1 («летает») не ограничен:
>>> rrp.parse_tagged (['Время', 'летит'], possible_tags = {0: ['VB', 'JJ', 'NN']}) [0]
ScoredParse ('(S1 (NP (NN Time) (VBZ летает)))', parser_score = -42.9961920777843, reranker_score = -12.57069545767032)
Если вы пометили ограничения диапазона, вы можете потребовать, чтобы все синтаксические анализы следовали за ними с помощью parse_constrained.Следующее требует, чтобы синтаксический анализ содержал
ПО, покрывающее налево на Фолклендские острова:
>>> rrp.parse_constrained ('Британцы оставили вафли на Фолклендах.'. Split (),
... constraints = {(1, 5): ['VP']}) [0]
ScoredParse ('(S1 (S (NP (NNPS British)) (VP (VBD слева) (NP (NNS waffles)) (PP (IN on) (NP (NNP Falklands)))) (.)))', parser_score = -93.73622897543436, reranker_score = -25.60347808581542)
Чтобы заставить британское левое слово быть существительным:
>> rrp.parse_constrained ('Британцы оставили вафли на Фолклендах.'. split (),
... constraints = {(0, 2): ['NP']}) [0]
ScoredParse ('(S1 (S (NP (JJ British) (NN слева)) (VP (вафли VBZ) (PP (IN вкл.) (NP (NNP Falklands)))) (.)))', Parser_score = - 89.59447837562135, reranker_score = -25.480236524298025)
Есть много параметров синтаксического анализатора, которые можно настроить (хотя значения по умолчанию
должен хорошо работать в большинстве случаев) с set_parser_options. Этот
изменит размер n-лучшего списка и выберет значения по умолчанию для всех
другие варианты.Возвращает словарь текущих опций:
>>> rrp.set_parser_options (nbest = 10)
{'language': 'En', 'case_insensitive': False, 'debug': 0, 'small_corpus': True, 'overparsing': 21, 'smooth_pos': 0, 'nbest': 10}
>>> nbest_list = rrp.parse ('Список теперь меньше. ', rerank = False)
>>> len (nbest_list)
10
 ', rerank = False)
>>> len (nbest_list)
10
', rerank = False)
>>> len (nbest_list)
10
Синтаксический анализатор также может использоваться как теггер:
>>> rrp.tag («Время летит, пока развлекаешься.»)
[('Время', 'NNP'), ('летает', 'VBZ'), ('пока', 'IN'), ('ты', 'PRP'), ("re", 'VBP' ), ('имеющий', 'VBG'), ('веселье', 'NN'), ('.','. ')]
Используйте это, если вам нужен токенизатор в стиле Penn Treebank:
>>> из bllipparser import tokenize >>> tokenize («Обозначьте это предложение, пожалуйста.») ['Tokenize', 'this', 'предложение', ',', 'please', '.']
Оболочка синтаксического анализа
BLLIP Parser включает интерактивную оболочку для визуализации парсеров:
оболочка% python -mbllipparser модель
(для Python 2.6 необходимо запустить: python -mbllipparser.ParsingShell model)
Модель
может быть унифицированной моделью синтаксического анализа или моделью синтаксического анализа первого этапа на
диск или имя модели, известной ModelFetcher, и в этом случае он будет
быть загруженным и установленным, если он еще не был загружен.Если нет модели
указано, в нем будут перечислены устанавливаемые модели синтаксического анализа.
Оказавшись в оболочке, введите предложение, чтобы синтаксический анализатор проанализировал его:
bllip> Я видел астронома в телескоп.
Жетоны: Я видел астронома в телескоп.
Разбор парсера:
(S1 (S (NP (PRP I))
(ВП (пила ВБД)
(Н.П. (НП (ДТ) (Н.Н. астроном))
(ПП (В с) (НП (ДТ) (телескоп НН)))))
(..)))
Разбор реранкера: (индекс парсера 2)
(S1 (S (NP (PRP I))
(ВП (пила ВБД)
(Н.П. (ДТ) (Н.Н. астроном))
(ПП (В с) (НП (ДТ) (телескоп НН))))
(..)))
Если у вас установлен nltk, вы можете использовать его древовидную визуализацию для
см. вывод:
bllip> visual Покажи мне этот синтаксический анализ. Токены: Покажите мне этот синтаксический анализ. [появляется графическое отображение синтаксического анализа]
Если у вас установлен PyStanfordDependencies, вы можете анализировать прямо
в Стэнфордский филиал:
bllip> sdparse Теперь с интеграцией Стэнфордских зависимостей! Токены: теперь с интеграцией Stanford Dependencies! Парсер и реранкер: Теперь [root] + - с [преп] | + - интеграция [pobj] | + - Стэнфорд [nn] | + - Зависимости [nn] + -! [пункт]
Пакет asciitree необходим для визуализации Стэнфордских зависимостей
как дерево. Если он недоступен, зависимости будут показаны в
Если он недоступен, зависимости будут показаны в
Формат CoNLL-X.
Более подробная справка находится внутри оболочки под командой справки.
Класс дерева
Синтаксический анализатор предоставляет простой класс Tree, который предоставляет информацию о
Деревья в стиле Penn Treebank:
>>> tree = bllipparser.Tree ('(S1 (S (NP (DT This)) (VP (VBZ is) (NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) ( NN дерево))) (..))) ')
>>> print (дерево)
(S1 (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (NN parse) (NN tree))) (..)))
pretty_string () обеспечивает строковую привязку:
>>> печать (tree.pretty_string ())
(S1 (S (NP (DT Это))
(ВП (ВБЗ есть)
(NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) (NN tree)))
(..)))
Вы можете получить жетоны и теги дерева:
>>> печать (tree.tokens ())
('Это', 'есть', 'a', 'справедливо', 'просто', 'разобрать', 'дерево', '.')
>>> печать (tree.tags ())
('DT', 'VBZ', 'DT', 'RB', 'JJ', 'NN', 'NN', '.')
>>> print (tree.tokens_and_tags ())
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('справедливо', 'RB'), ('simple', 'JJ') , ('синтаксический анализ', 'NN'), ('дерево', 'NN'), ('.', '.')]
Или получите информацию о помеченных пролетах в дереве:
>>> печать (tree.span ()) (0, 8) >>> print (tree.label) S1
Вы можете перемещаться по деревьям и не только:
>>> tree.subtrees ()
[Дерево ('(S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (NN parse) (NN tree))) (..)) ')]
>>> tree [0] # первое поддерево
Дерево ('(S (NP (DT This)) (VP (VBZ) (NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) (NN tree))) (.)) ')
>>> tree [0] .label
'S'
>>> tree [0] [0] # первое поддерево первого поддерева
Дерево ('(NP (DT This))')
>>> tree [0] [0] .label
«НП»
>>> tree [0] [0] .span () # [начало, конец) индексы для диапазона
(0, 1)
>>> tree [0] [0] .tags () # теги в этом диапазоне
('DT',)
>>> tree [0] [0] . tokens () # кортеж всех токенов в этом диапазоне
('Этот',)
>>> дерево [0] [0] [0]
Дерево ('(DT This)')
>>> дерево [0] [0] [0].жетон
'Этот'
>>> tree [0] [0] [0] .label
'DT'
>>> tree [0] [0] [0] .is_preterminal ()
Правда
>>> len (tree [0]) # количество поддеревьев
3
>>> для поддерева в дереве [0]: # итерация работает
... печать (поддерево)
...
(НП (DT Это))
(VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (NN parse) (NN tree)))
(..)
>>> для поддерева в tree.all_subtrees (): # все поддеревья (рекурсивно)
... print ('% s% s'% (subtree.is_preterminal (), поддерево))
...
Ложь (S1 (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (синтаксический анализ NN) (дерево NN))) (..)))
Ложь (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) (NN tree))) (.))
Ложь (NP (DT This))
Правда (DT This)
Ложь (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) (NN tree)))
Верно (ВБЗ есть)
Ложь (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (синтаксический анализ NN) (дерево NN))
Верно (DT a)
Ложь (ADJP (RB справедливо) (JJ simple))
Верно (РБ справедливо)
Верно (JJ простой)
Истина (анализ NN)
Истина (дерево NN)
Правда (. .)
 tokens () # кортеж всех токенов в этом диапазоне
('Этот',)
>>> дерево [0] [0] [0]
Дерево ('(DT This)')
>>> дерево [0] [0] [0].жетон
'Этот'
>>> tree [0] [0] [0] .label
'DT'
>>> tree [0] [0] [0] .is_preterminal ()
Правда
>>> len (tree [0]) # количество поддеревьев
3
>>> для поддерева в дереве [0]: # итерация работает
... печать (поддерево)
...
(НП (DT Это))
(VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (NN parse) (NN tree)))
(..)
>>> для поддерева в tree.all_subtrees (): # все поддеревья (рекурсивно)
... print ('% s% s'% (subtree.is_preterminal (), поддерево))
...
Ложь (S1 (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (синтаксический анализ NN) (дерево NN))) (..)))
Ложь (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) (NN tree))) (.))
Ложь (NP (DT This))
Правда (DT This)
Ложь (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) (NN tree)))
Верно (ВБЗ есть)
Ложь (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (синтаксический анализ NN) (дерево NN))
Верно (DT a)
Ложь (ADJP (RB справедливо) (JJ simple))
Верно (РБ справедливо)
Верно (JJ простой)
Истина (анализ NN)
Истина (дерево NN)
Правда (. .)
tokens () # кортеж всех токенов в этом диапазоне
('Этот',)
>>> дерево [0] [0] [0]
Дерево ('(DT This)')
>>> дерево [0] [0] [0].жетон
'Этот'
>>> tree [0] [0] [0] .label
'DT'
>>> tree [0] [0] [0] .is_preterminal ()
Правда
>>> len (tree [0]) # количество поддеревьев
3
>>> для поддерева в дереве [0]: # итерация работает
... печать (поддерево)
...
(НП (DT Это))
(VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (NN parse) (NN tree)))
(..)
>>> для поддерева в tree.all_subtrees (): # все поддеревья (рекурсивно)
... print ('% s% s'% (subtree.is_preterminal (), поддерево))
...
Ложь (S1 (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (синтаксический анализ NN) (дерево NN))) (..)))
Ложь (S (NP (DT This)) (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) (NN tree))) (.))
Ложь (NP (DT This))
Правда (DT This)
Ложь (VP (VBZ есть) (NP (DT a) (ADJP (RB справедливо) (JJ simple)) (NN parse) (NN tree)))
Верно (ВБЗ есть)
Ложь (NP (DT a) (ADJP (RB справедливо) (JJ простой)) (синтаксический анализ NN) (дерево NN))
Верно (DT a)
Ложь (ADJP (RB справедливо) (JJ simple))
Верно (РБ справедливо)
Верно (JJ простой)
Истина (анализ NN)
Истина (дерево NN)
Правда (. .)
Поваренная книга
Python Argparse - mkaz.blog
Я использую Python в качестве основного инструмента для сценариев командной строки, которые часто требуют синтаксического анализа аргументов командной строки.Поскольку я использую разные языки программирования, я ничего не помню, поэтому создаю справочные документы для себя и, надеюсь, других.
Я написал эту документацию для синтаксического анализа аргументов командной строки в Python, что очень похоже на мою книгу Python String Format Cookbook, которая представляет собой примеры форматирования строк и чисел.
Какую библиотеку использовать
Я не знаю истории, но есть пара стандартных библиотек, которые вы можете использовать для анализа аргументов командной строки. Вы хотите использовать модуль argparse .По названию похож на optparse , но это более старый устаревший модуль.
Вы хотите использовать модуль argparse .По названию похож на optparse , но это более старый устаревший модуль.
Также сбивает с толку модуль getopt , который обрабатывает синтаксический анализ аргументов командной строки, но является более сложным и требует написания большего количества кода.
Просто используйте модуль argparse , он отлично работает как для Python2, так и для Python3.
Базовый пример
Во-первых, вам может не понадобиться модуль. Если все, что вам нужно сделать, это получить один аргумент и не передать флаги или другие параметры, вы можете просто использовать sys.argv массив, содержащий все параметры командной строки.
Первым элементом в sys.argv является сам сценарий. Таким образом, переданный параметр будет во втором элементе: sys.argv [1]
импорт систем
если len (sys.argv)> 1:
print ("~ Скрипт:" + sys.argv [0])
print ("~ Arg:" + sys.argv [1])
еще:
print («Без аргументов») Сохранение как test.py и запуск дает:
$ python test.py Foo
~ Скрипт: test.py
~ Arg: Foo Несколько аргументов с sys.argv
Поскольку sys.argv - это просто список, вы можете собирать блоки аргументов вместе или нарезать их, как любой другой список.
Последний аргумент: sys.argv [-1]
Все аргументы после первого: "" .join (sys.argv [2:])
Параметры флага
Вам нужно начать использовать модуль, если вы хотите начать, включая такие флаги, как --help , или хотите иметь необязательные аргументы или параметры переменной длины.Как уже упоминалось, лучший стандартный модуль для использования - argparse .
Справка и подробные примеры
импорт argparse
parser = argparse. ArgumentParser (описание = 'Демо')
parser.add_argument ('- подробный',
действие = 'store_true',
help = 'подробный флаг')
args = parser.parse_args ()
если args.verbose:
print ("~ Подробно!")
еще:
print ("~ Не очень подробный")
 ArgumentParser (описание = 'Демо')
parser.add_argument ('- подробный',
действие = 'store_true',
help = 'подробный флаг')
args = parser.parse_args ()
если args.verbose:
print ("~ Подробно!")
еще:
print ("~ Не очень подробный")
ArgumentParser (описание = 'Демо')
parser.add_argument ('- подробный',
действие = 'store_true',
help = 'подробный флаг')
args = parser.parse_args ()
если args.verbose:
print ("~ Подробно!")
еще:
print ("~ Не очень подробный")
Вот как запустить приведенный выше пример:
$ python test.ру
~ Не так многословно
$ python test.py --verbose
~ Подробно!
Параметр действия указывает argparse сохранять значение true, если флаг найден, в противном случае - значение false. Также в использовании argparse замечательно то, что вы получаете встроенную справку. Вы можете попробовать это, передав неизвестный параметр, -h или --help
$ python test.py --help
использование: test.py [-h] [--verbose]
Демо
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
--verbose подробный вывод
Побочный эффект использования argparse: вы получите сообщение об ошибке, если пользователь передаст неожиданный аргумент командной строки, включая флаги или просто дополнительный аргумент.
$ python test.py имя файла
использование: test.py [-h] [--verbose]
test.py: ошибка: нераспознанные аргументы: имя файла Множественные, короткие или длинные флажки
Вы можете указать несколько флагов для одного аргумента, обычно это опускается с помощью коротких и длинных флагов, например --verbose и -v
импорт argparse
parser = argparse.ArgumentParser ()
parser.add_argument ('- подробный', '-v',
действие = 'store_true',
help = 'подробный флаг')
args = парсер.parse_args ()
если args.verbose:
print ("~ Подробно!")
еще:
print ("~ Не очень подробный") Необходимые флаги
Вы можете сделать флаг обязательным, установив required = True , это вызовет ошибку, если флаг не указан.
parser = argparse.ArgumentParser ()
parser.add_argument ('- limit', required = True, type = int)
args = parser.parse_args ()
Позиционные аргументы
Примеры до сих пор относились к флагам, параметрам, начинающимся с - , argparse также обрабатывает позиционные аргументы, которые только что указаны без флага.Вот пример для иллюстрации.
parser = argparse.ArgumentParser ()
parser.add_argument ('имя файла')
args = parser.parse_args ()
print ("~ Имя файла: {}". формат (args.filename))
Выход:
$ python test.py filename.txt
~ Имя файла: filename.txt
Количество аргументов
Argparse определяет количество аргументов на основе указанного действия, для нашего подробного примера действие store_true не принимает аргументов.По умолчанию argparse будет искать единственный аргумент, показанный выше в примере имени файла.
Если вы хотите, чтобы ваши параметры принимали список элементов, вы можете указать nargs = n для количества принимаемых аргументов. Обратите внимание: если вы установите nargs = 1 , он вернет в виде списка, а не одно значение.
импорт argparse
parser = argparse.ArgumentParser ()
parser.add_argument ('число', nargs = 2)
args = parser.parse_args ()
print ("~ Nums: {}". format (args.nums)) Выход:
$ python test.ру 5 2
~ Числа: ['5', '2'] Переменное количество параметров
Аргумент nargs принимает несколько дополнительных специальных параметров. Если вы хотите, чтобы аргумент принимал все параметры, вы можете использовать * , который вернет все параметры, если они есть, или пустой список, если их нет.
parser = argparse.ArgumentParser ()
parser. add_argument ('число', nargs = '*')
args = parser.parse_args ()
print ("~ Nums: {}". format (args.nums))  add_argument ('число', nargs = '*')
args = parser.parse_args ()
print ("~ Nums: {}". format (args.nums))
add_argument ('число', nargs = '*')
args = parser.parse_args ()
print ("~ Nums: {}". format (args.nums)) Выход:
$ python test.ру 5 2 4
~ Числа: ['5', '2', '4'] Если вы хотите потребовать один или несколько параметров, используйте nargs = '+'
Позиционные аргументы определяются указанной позицией. Это можно комбинировать с nargs = '*' , например, если вы хотите определить имя файла и список значений для хранения.
parser = argparse.ArgumentParser ()
parser.add_argument ('имя файла')
parser.add_argument ('число', nargs = '*')
args = parser.parse_args ()
print ("~ Имя файла: {}".формат (args.filename))
print ("~ Nums: {}". format (args.nums)) Выход:
$ python test.py file.txt 5 2 4
~ Fileanme: file.txt
~ Числа: ['5', '2', '4'] Также можно указать nargs = '?' , если вы хотите сделать позиционный аргумент необязательным, но вам нужно быть осторожным, как вы комбинируете? и * параметры, особенно если вы помещаете необязательный позиционный параметр перед другим.
Это имеет смысл, не требуя последних аргументов:
парсер = argparse.ArgumentParser ()
parser.add_argument ('имя файла')
parser.add_argument ('число', nargs = '?')
args = parser.parse_args () Выход:
$ python test.py test.txt 3
~ Имя файла: test.txt
~ Кол-во: 3
$ python test.py test.txt
~ Имя файла: test.txt
~ Числа: Нет Однако, используя nargs = '?' сначала даст неожиданные результаты при отсутствии аргументов, например:
parser = argparse.ArgumentParser ()
parser.add_argument ('имя файла', nargs = '?')
парсер.add_argument ('число', nargs = '*')
args = parser.parse_args () Выход:
$ python test. py 3 2 1
~ Имя файла: 3
~ Числа: ['2', '1']  py 3 2 1
~ Имя файла: 3
~ Числа: ['2', '1']
py 3 2 1
~ Имя файла: 3
~ Числа: ['2', '1'] Вы также можете использовать nargs с аргументами флага.
parser = argparse.ArgumentParser ()
parser.add_argument ('- geo', nargs = 2)
parser.add_argument ('- pos', nargs = 2)
parser.add_argument ('тип')
args = parser.parse_args () Выход:
$ python test.py --geo 5 10 --pos 100 50 квадрат
~ Geo: ['5', '10']
~ Pos: ['100', '50']
~ Тип: квадрат Тип переменной
Вы могли заметить, что переданные параметры обрабатываются как строки, а не числа. Вы можете указать тип переменной, указав type = int . Если указать тип, argparse также завершится ошибкой, если будет передан недопустимый тип.
parser = argparse.ArgumentParser ()
parser.add_argument ('число', nargs = 2, type = int)
args = парсер.parse_args ()
print ("~ Nums: {}". format (args.nums)) Выход:
$ python test.py 5 2
~ Числа: [5, 2] Типы файлов
Argparse имеет встроенные типы файлов, которые упрощают открытие файлов, указанных в командной строке. Вот пример чтения файла, вы можете сделать то же самое при записи файла.
parser = argparse.ArgumentParser ()
parser.add_argument ('f', type = argparse.FileType ('r'))
args = parser.parse_args ()
для строки в аргументах.f:
печать (line.strip ()) Значение по умолчанию
Вы можете указать значение по умолчанию, если пользователь его не вводит. Вот пример использования флага.
parser = argparse.ArgumentParser ()
parser.add_argument ('- limit', по умолчанию = 5, type = int)
args = parser.parse_args ()
print ("~ Ограничение: {}". формат (args.limit)) Выход:
$ python test.py
~ Лимит: 5 остаток
Если вы хотите собрать переданные дополнительные аргументы, вы можете использовать остаток, который собирает все аргументы, не указанные в списке.
импорт argparse
parser = argparse.ArgumentParser ()
parser.add_argument ('- подробный',
действие = 'store_true',
help = 'подробный флаг')
parser.add_argument ('аргументы', nargs = argparse.REMAINDER)
args = parser.parse_args ()
печать (args.args) Указание остатка создаст список всех оставшихся аргументов:
$ python test.py --verbose foo bar
['foo', 'bar'] Действия
Действие по умолчанию - присвоить указанную переменную, но можно указать еще несколько действий.
Логические
Мы уже видели действие логического флага action = 'store_true' , которое также имеет встречное действие для action = 'store_false'
Счетчик
Вы можете использовать действие count, которое вернет, сколько раз был вызван флаг, это может быть полезно для многословных или тихих флагов.
parser = argparse.ArgumentParser ()
parser.add_argument ('- подробный', '-v', действие = 'количество')
args = парсер.parse_args ()
print ("~ Подробно: {}". формат (args.verbose)) Выход:
$ python test.py
~ Подробно: Нет
$ python test.py --verbose
~ Подробно: 1
$ python test.py --verbose -v --verbose
~ Подробно: 3 Приложение
Вы также можете использовать действие добавления для создания списка, если передано несколько флагов.
parser = argparse.ArgumentParser ()
parser.add_argument ('- c', действие = 'добавить')
args = parser.parse_args ()
print ("~ C: {}".формат (args.c)) Выход:
$ python test.py
~ C: Нет
$ python test.py -c привет
~ C: ['привет']
$ python test.py -c привет -c привет -c привет
~ C: [«привет», «привет», «привет»] вариантов
Если вы хотите, чтобы использовался только набор разрешенных значений, вы можете установить список вариантов, который будет отображать ошибку при недопустимой записи.
парсер = argparse.ArgumentParser (prog = 'roshambo.py')
parser.add_argument ('бросок', choices = ['камень', 'бумага', 'ножницы'])
args = парсер.parse_args ()
print ("~ Throw: {}". format (args.throw)) Примеры
Я закончу двумя полными примерами; многие из приведенных выше примеров не так полны, они были краткими, чтобы сосредоточить внимание на иллюстрированной идее.
Пример сценария копирования
импорт argparse
import sys
parser = argparse.ArgumentParser (description = 'сценарий для копирования одного файла в другой')
parser.add_argument ('- v', '--verbose',
action = "store_true",
help = "подробный вывод")
парсер.add_argument ('- R',
action = "store_false",
help = "Рекурсивно копировать все файлы и каталоги")
parser.add_argument ('infile',
type = argparse.FileType ('r'),
help = "файл для копирования")
parser.add_argument ('выходной файл',
type = argparse.FileType ('w'),
help = "файл для создания")
args = parser.parse_args ()
Пример сценария ошибки
Вот пример скрипта, закрывающего ошибку
импорт argparse
import sys
parser = argparse.ArgumentParser (description = 'закрыть ошибку')
парсер.add_argument ('- v', '--verbose',
action = "store_true",
help = "подробный вывод")
parser.add_argument ('- s',
по умолчанию = "закрыто",
choices = ['закрыто', 'wontfix', 'notabug'],
help = "статус ошибки")
parser.add_argument ('ошибка',
type = int,
help = "Номер ошибки, которую необходимо закрыть")
parser.add_argument ('сообщение',
nargs = '*',
help = "необязательное сообщение")
args = parser.parse_args ()
print ("~ Номер ошибки: {}". format (args.bugnum))
print ("~ Подробно: {}". формат (args.verbose))
print ("~ Status: {}". format (arg.s))
print ("~ Сообщение: {}". format ("" .join (args.message)))
ресурсов
- Официальная документация Argparse - официальная документация включает все доступные параметры и пример руководства с использованием argparse.
