Фонетический (звуко-буквенный) разбор слова онлайн
Фонетический (звуко-буквенный) разбор слова онлайн
Фонетический (звуко-буквенный) разбор слов онлайн. Транскрипция, слоги и цветовые схемы. Справочные материалы.
Фонетика — раздел науки о языке, в котором изучаются звуки языка, ударение, слог. Освоив их, вы сможете делать фонетический разбор слова.
Слова с буквой ё обязательно пишите через ё. Фонетические разборы слов «еж» и «ёж» будут разными!
Фонетический разбор слова — определение количества букв, звуков, ударения в слове, выделение гласных и согласных звуков, их классификация, то есть подробный анализ слова, с точки зрения его правильного произношения. Для проведения анализа необходимо знать, что такое гласные и согласные звуки, и как составляется транскрипция. Если вы не знакомы с этими понятиями, советуем прочитать материалы о звуках русского языка и правила фонетики. Фонетический разбор помогает определить состав слова с точки зрения букв и звуков, поэтому его ещё называют звуко-буквенным разбором.
Сайт phoneticonline.ru содержит примеры фонетического разбора слов русского языка всех частей речи. Воспользуйтесь формой поиска для просмотра фонетического разбора нужного слова. Разбор слова делается с помощью программы в автоматическом режиме. Советуем использовать фонетический разбор исключительно для самопроверки, так как он может быть неверным либо используемые нами правила могут отличаться от правил вашей учебной программы.
Будьте внимательны! Фонетический разбор различен для слов с одинаковым написанием и различным ударением: доро́га и дорога́ — различные слова, имеют разные значения, сне́га и снега́ — одно и то же слово, но записано в единственном и множественном числе.
Часто вместо буквы ё пишут букву е: елочный, трехкомнатная. В фонетическом разборе есть разница между буквами. Для получения правильного разбора слова должны быть записаны через букву ё: ёлочный, трёхкомнатная.
Смотрите план фонетического разбора с примерами в устной и письменной форме. Примеры также можно найти среди слов, которые проверяли посетители сайта: крупненький, каретка, копуша, томагавк, неплатёж, Русалочке, раздробление, смешу, серединочка, сквернее, Замякина, фразовая, разграничительной, фонетическим, сглаживатель, закадычные, голубеньких, остуженной, беспокоясь, надруб и другие. За всё время посетители запросили более 700 тысяч слов в разных склонениях и формах. Среди них часто запрашиваемых — 198290 слов.
Примеры также можно найти среди слов, которые проверяли посетители сайта: крупненький, каретка, копуша, томагавк, неплатёж, Русалочке, раздробление, смешу, серединочка, сквернее, Замякина, фразовая, разграничительной, фонетическим, сглаживатель, закадычные, голубеньких, остуженной, беспокоясь, надруб и другие. За всё время посетители запросили более 700 тысяч слов в разных склонениях и формах. Среди них часто запрашиваемых — 198290 слов.
phoneticonline.ru — фонетический (звуко-буквенный) разбор слов
строчная — фонетический (звуко-буквенный) разбор слова
Cлово имеет 3 разбора, так как ударение может падать на разные слоги (ударения были указаны пользователями сайта).
Разбор №1
стро́чная
строчная — слово из 3 слогов: стро-чна-я. Ударение падает на 1-й слог.
Транскрипция слова: [строч’най’а]
с — [с] — согласный, глухой парный, твёрдый (парный)
т — [т] — согласный, глухой парный, твёрдый (парный)
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
о — [о] — гласный, ударный
ч — [ч’] — согласный, глухой непарный, мягкий (непарный, всегда произносится мягко), шипящий
н — [н] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
а — [а] — гласный, безударный
я — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
— [а] — гласный, безударный
В слове 8 букв и 9 звуков.
При разборе слова используются правила:
- Сочетание букв -чн- произносится как [шн]
Цветовая схема: строчная
За всё время слово запрашивали 3704 раза
Разбор сделан с помощью программы и не всегда может быть правильным. Представленный результат используется вами исключительно для самопроверки.
Разбор №2
строчна́я
строчная — слово из 3 слогов: стро-чна-я. Ударение падает на 2-й слог.
Транскрипция слова: [страч’най’а]
с — [с] — согласный, глухой парный, твёрдый (парный)
т — [т] — согласный, глухой парный, твёрдый (парный)
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
о — [а] — гласный, безударный
ч — [ч’] — согласный, глухой непарный, мягкий (непарный, всегда произносится мягко), шипящий
н — [н] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
а — [а] — гласный, ударный
я — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
— [а] — гласный, безударный
В слове 8 букв и 9 звуков.
Цветовая схема: строчная
3703 / Слово разобрано с помощью программы. Результат разбора используется вами на свой страх и риск.
Разбор №3
строчная́
строчная — слово из 3 слогов: стро-чна-я. Ударение падает на 3-й слог.
Транскрипция слова: [страч’най’а]
с — [с] — согласный, глухой парный, твёрдый (парный)
т — [т] — согласный, глухой парный, твёрдый (парный)
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
о — [а] — гласный, безударный
ч — [ч’] — согласный, глухой непарный, мягкий (непарный, всегда произносится мягко), шипящий
н — [н] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
а — [а] — гласный, безударный
я — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
— [а] — гласный, ударный
В слове 8 букв и 9 звуков.
Цветовая схема: строчная
64 / Слово разобрано с помощью программы. Результат разбора используется вами на свой страх и риск.
Результат разбора используется вами на свой страх и риск.
Слова с буквой ё обязательно пишите через ё. Фонетические разборы слов «еж» и «ёж» будут разными!
Примеры других слов с разборами на буквы и звуки:
Фонетический (звуко-буквенный) разбор слов / Справочник :: Бингоскул
Фонетический анализ слова подразумевает правильное произношение слова, отражение его в транскрипции, указание количества слогов и ударения в слове, подсчет количества букв, подробную характеристику звуков.
Фонетический анализ определяет буквенный и звуковой состав слова, поэтому имеет ещё одно название – звуко-буквенный разбор.
Как сделать фонетический (звуковой) анализ слова?
Работа по проведению фонетического анализа слова заключается:
- в правильном написании слова и определении в нем ударения;
- в разделении на слоги и установлении мест слогового переноса частей словоформы;
- в записи слова согласно произношению – в транскрипции;
- в подробной характеристике каждой фонемы;
- в подсчете количества букв и звуков.


Правила разбора на звуки
Каждая буква в слове – графическая фиксация (написание) звука или звуков. Все звуки русского языка поделены на гласные и согласные. Гласные – [а], [э], [и], [у], [ы], [о] – состоят только из голоса. В образовании согласных участвуют не только голосовые связки и легкие, но и полость рта, поэтому в них присутствует шум.
Среди твердых и мягких согласных имеются глухие: [х/х’], [п/п’], [т/т’], [ф/ф’], [х/х’], [ч’], [ш], [щ’], [ц] и звонкие: [й’], [к/к’], [н/н’] , [г/г’], [з/з’] , [в/в’], [р/р’] , [л/л’], [д/д’], [ж], [м/м’], [б/б’], среди которых выделяют сонорные. В сонорных голоса больше чем шума. Их девять – [м/м’], [н/н’], [р/р’], [л/л’], [й’].
При фонетическом анализе слова необходимо определить, какой звук – гласный или согласный. Если гласный, нужно указать – ударный он (произносится сильно, отчетливо) или безударный (произносится с меньшей силой и отчетливостью).
Согласные звуки характеризуются по следующим параметрам: по глухости и звонкости [п] – [б], твердости и мягкости [п] – [п‘] с указанием парности. Необходимо обозначать, имеет ли звук пару по этим критериям. Например: глухой [п] имеет пару по звонкости – [б] и по мягкости – [п‘].
Необходимо обозначать, имеет ли звук пару по этим критериям. Например: глухой [п] имеет пару по звонкости – [б] и по мягкости – [п‘].
Кроме того, необходимо указывать на «сонорность» звука, если он сонорный.
При более детальной характеристике указывается наличие «шипения» в звуке, пишется – «шипящий».
Также при звуковом анализе необходимо помнить, что не все буквы языка обозначают звуки. Например, разделительные знаки «Ь» и «Ъ» звуков не обозначают. Есть в фонетике непроизносимые согласные, которые тоже не обозначают звуков, например, «счастливый» – [щ’асл’ивый’]. Эту особенность при звуковом анализе необходимо учитывать. При разборе напротив таких букв пишется – «не обозначает звука».
Не стоит забывать, что некоторые буквы в определенных позициях слова обозначают два звука. Это буквы «е», «ё», «ю», «я». Они, в начале слова, после – «Ь», «Ъ» и гласной, всегда обозначают два звука: [й‘э]; [й‘о]; [й‘у]; [й‘а]. Бывает и вариант [й‘и] – «язык»: [й’изык].
План фонетического анализа слова
Фонетический анализ каждого слова производится не беспорядочно, а по определенному плану.
- Указывается орфографически правильное написание слова.
- Словоформа делится на слоги, обозначается ударение.
- Определяется место возможного переноса частей слова.
- Слово записывается так, как произносится – в транскрипции.
- Дается поочередная характеристика всех звуков слова.
- Указывается количество букв и фонем, случаи несоответствия букв и звуков.
- Создается цветовая схема разобранного слова.
Примеры фонетического (звукового) разбора
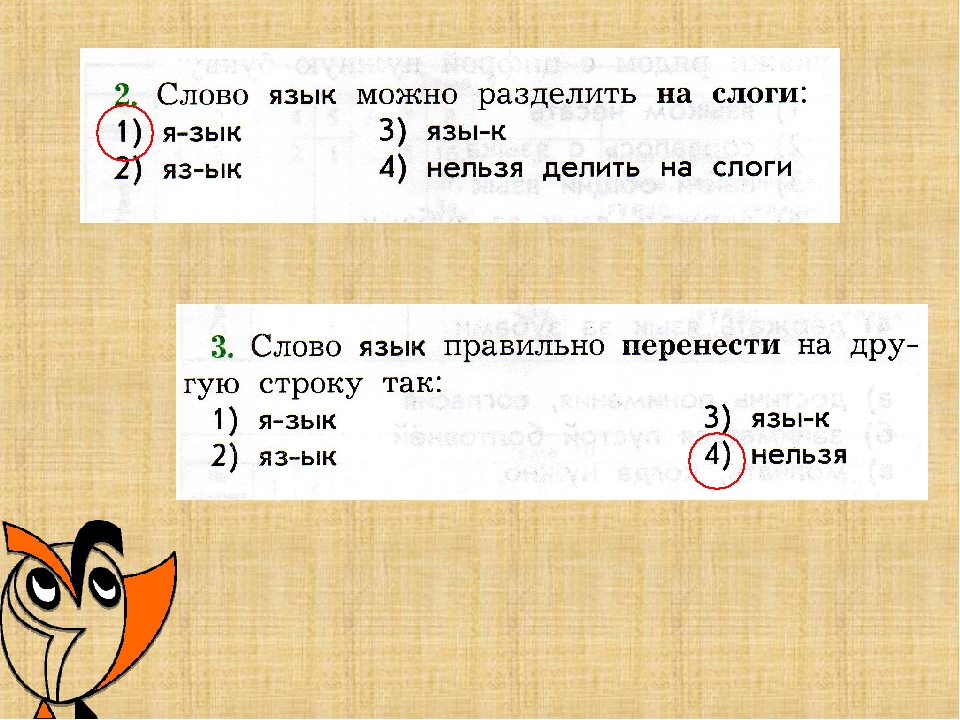
Язык
Слоги: я-зы́к (2 слога; ударение падает на 2-й слог)
Перенос: вариантов не имеется.
Транскрипция: [й’изык]
| я | [й’] | — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко) |
| [и] | — гласный, безударный | |
| з | [з] | — согласный, звонкий парный, твёрдый (парный) |
| ы | [ы] | — гласный, ударный |
| к | [к] | — согласный, глухой парный, твёрдый (парный) |
В слове 4 буквы и 5 звуков.
Буква «я» обозначает 2 звука — [й’], [и].
Цветовая схема слова —
Я
Слоги: я (1 слог; ударный)
Перенос: вариантов не имеется.
Транскрипция: [й’я]
| я | [й’] | — согласный, сонорный, звонкий непарный, мягкий непарный |
| [и] | — гласный, ударный |
1 буква — 2 звука.
Буква «я» обозначает 2 звука — [й’], [а].
Цветовая схема слова —
Листья
Слоги: ли́-стья (2 слога; ударение падает на 1-й слог)
Перенос: лис–тья
Транскрипция: [л’ист’й’а]
| Л | [л] | — согласный, непарный звонкий, сонорный, парный мягкий |
| и | [и] | — гласный, ударный |
| с | [с] | — согласный, парный глухой, парный твёрдый |
| т | [т] | — согласный, парный глухой, парный мягки |
| ь | [-] | — не обозначает звука |
| я | [й’] | — согласный, непарный звонкий, сонорный, непарный мягкий |
| [а] | — гласный, безударны |
В слове 6 букв и 6 звуков.
Буква «ь» не обозначает звука, «я» — обозначает 2 звука — [й’], [а].
Цветовая схема слова —
Лёгкий
Слоги: лёг-кий (2 слога; ударение падает на 1-й слог)
Перенос: лёг-кий
Транскрипция: [л’охк’ий’]
| Л | [л,] | — согласный, непарный звонкий, сонорный, парный мягкий |
| ё | [о] | — гласный, ударный |
| г | [х] | — согласный, непарный глухой, парный твёрдый |
| к | [к,] | — согласный, парный глухой, парный мягкий |
| и | [и] | — гласный, безударный |
| й | [й’] | — согласный, непарный звонкий, сонорный, непарный мягкий |
В слове 6 букв и 6 звуков.
- Буква «ё» обозначает звук [о],
- Буква «г» обозначает звук [к].
Цветовая схема слова —
Смотри также:
Фонетический разбор слов онлайн — правила и примеры
Фонетикой называют раздел языкознания, который изучает звуковую систему языка и звуки речи в целом. Фонетика —
это наука о сочетании звуков в речи.
Фонетический разбор, или звуко-буквенный, — это анализ строения слогов и звуковой системы слова. Такой анализ
предлагается выполнять как упражнение в учебных целях.
Под анализом понимается:
- подсчитывание количества букв;
- определение числа звуков в слове;
- постановка ударения;
- распределение звуков на согласные и гласные;
- классификация каждого звука;
- составление транскрипции (графической формы слова).

При разборе важно различать понятия «буква» и «звук». Ведь первые соответствуют орфографическим правилам, а
вторые — речевым (то есть звуки анализируются с точки зрения произношения).
Прежде чем приступить к звуко-буквенному разбору, следует запомнить
В русском языке десять гласных звуков:
| [А] | [О] | [У] | [Ы] | [Э] | [ЙА] буква «Я» | [ЙО] буква «Ё» | [ЙУ] буква «Ю» | [И] | [ЙЭ] буква «Е» |
Первые пять обозначают, что предшествующий согласный является твердым, а вторые — мягким.
И двадцать один согласный звук:
| звонкие непарные звуки | [Й’] | [Л] | [М] | [Н] | [Р] | |
| глухие непарные | [Х] | [Ц] | [Ч’] | [Щ’] | ||
| звонкие парные | [Б] | [В] | [Г] | [Д] | [Ж] | [З] |
| глухие парные | [П] | [Ф] | [К] | [Т] | [Ш] | [С] |
Звонкими называют согласные, которые образуются с участием звука, а глухие — с помощью шума. Парными называют те
Парными называют те
согласные, которые образуют пару глухой/звонкий. Например, [Б]/[П], [В]/[Ф], [Г]/[К]. Непарными — те, которые не
образуют пары: [Л], [М], [Р].
При фонетическом анализе слова стоит помнить, что согласные [Ч’], [Щ’], [Й’] — всегда мягкие, вне зависимости от
того, какой гласный образует с ними слог. Согласные [Ж], [Ш] и [Ц] — всегда твердые.
[Й’], [Л], [Л’], [М], [М’], [Н], [Н’], [Р], [Р’] — сонорные звуки. А значит, при произношении этих согласных звук
образуется преимущественно голосом, но не шумом. Все сонорные — звонкие звуки.
В русском алфавите есть также буквы Ь, Ъ. Они не образуют звука. Ь (мягкий знак) служит для того, чтобы смягчать
согласные, после которых он ставится. Ъ (твердый знак) имеет разделительную функцию.
Правила разбора на звуки
- Транскрипция записывается в квадратных скобках: [ ].
- Мягкость звука обозначается символом «’».
- Перед глухими звонкие согласные оглушаются: ногти — [нокт’и].
- Звуки [с], [з] в приставках слов смягчаются: разъединить — [раз’й’эд’ин’ит’].
- Некоторые согласные в словах не читаются: костный — [косный’].
- Сочетание букв «сч», «зч» читаются как «щ»: счастье — [щ’аст’й’э].
- Удвоенный согласный обозначается «:»: постепенный — [паст’ип’эн:ый’].

Образец звуко-буквенного разбора слова
- Записать слово по правилам орфографии.
- Разделить слово по слогам.
- Обозначить ударный слог.
- Произнести слово вслух и на основании этого выполнить транскрипцию.
- Описать гласные звуки по порядку, обозначить, какие из них являются ударными, а какие — безударными. Описать
согласные. Охарактеризовать их: парные/непарные, звонкие/глухие, твердые/мягкие. - Подсчитать количество звуков и букв в слове.

Примеры фонетического разбора
Для примера ниже подобраны слова с наиболее интересными вариантами фонетического разбора:
шестнадцатью,
яростного,
съестного,
шестнадцатого,
ерошиться,
ёжиться,
ёжится,
ёршится,
разъезжаться,
съезжаться,
для выполнения фонетического разбора других слов воспользуйтесь формой поиска:
Фонетический разбор слова — план, примеры
Как правильно сделать фонетический разбор слова?
Фонетический разбор – это характеристика структуры слогов и состава слова из звуков.
Памятка
План фонетического разбора
- Записать слово орфографически правильно.
- Разделить слово на слоги и найти место ударения.
- Отметить возможности переноса слова по слогам.
- Фонетическая транскрипция слова.
- По порядку характеризовать все звуки: а. согласный – звонкий – глухой (парный или непарный), твёрдый или мягкий, какой буквой он обозначен; б. гласный: ударный или безударный.
- Подсчитать количество букв и звуков.
- Отметить случаи, если звук не соответствует букве.

Образцы фонетического разбора слов:
Я очень люблю есть морковь.
Фонетический разбор слова люблю:
- люблю
- люб – лЮ (на второй слог падает ударение, 2 слога)
- люб-лю
- [л’убл’у]
- Л – [л’] согласный, мягкий, звонкий и непарный;
Ю – [у] – гласный и безударный;
Б – [б] – согласный, твердый, звонкий и парный
Л – [л’] – согласный, мягкий, звонкий и непарный;
Ю – [у] – гласный и ударный - В слове 5 букв и 5 звуков.
https://uchim.org/russkij-yazyk/foneticheskij-razbor-slova — uchim. org
org
Фонетический разбор слова морковь:
- морковь
- мор-кОвь (на второй слог падает ударение, 2 слога).
- Перенос: мор-ковь
- [маркоф’]
- М – [м] – согласный, твердый, звонкий и непарный.
О – [а] – гласный и безударный.
Р – [р] – согласный, твердый, звонкий и непарный.
К – [к] – согласный, твердый, глухой и парный.
О – [о] – гласный и ударный.
В – [ф’] – согласный, мягкий, глухой и парный.
Ь —————————– - В слове 7 букв и 6 звуков.
- о – а, в – глухой звук ф, ь смягчает в.
Видео про фонетическую транскрипцию
Полезные советы:
- Делая фонетический разбор, нужно произнести слово вслух.
- Важно всегда проверять транскрипцию.
- Обязательно обращать внимание на орфограммы при фонетическом анализе.
- Также обращать внимание на звуки, которые произносятся в слабых позициях, таких как: стечение согласных или стечение гласных, согласные шипящие, непарные согласные по твёрдости и мягкости или звонкости и глухости.

Возможно, вам также понадобится Морфологический разбор.
Всё для учебы » Русский язык » Фонетический разбор слова — план, примеры
Слоговая теория Р. И. Аванесова
Р. И. Аванесов разработал сонорную теорию слога русского языка, которая объясняет две важных вещи: что такое слог и как правильно разделить слово на фонетические слоги. Начнем с первого.
Рубен Иванович Аванесов (1902—1982)
Слог, по Аванесову, это совокупность разных по степени сонорности звуков. Любой слог — это переход от менее сонорных к более сонорным звукам. Самый звучный — такой звук, который является вершиной слога. Уровни звучности обозначаются следующим образом:
- 4 — гласные;
- 3 — сонорные звонкие согласные;
- 2 — шумные звонкие согласные;
- 1 — шумные глухие согласные;
- 0 — пауза.
Получается, что любое русское слово можно представить схематически. Отметим каждый звук точкой на шкале от 0 до 4 и затем соединим получившиеся точки. Помним, что цифрами мы обозначаем именно характер звука, а не буквы, поэтому опираемся не на графическую запись слова, а на его транскрипцию, которую предварительно следует составить.
Помним, что цифрами мы обозначаем именно характер звука, а не буквы, поэтому опираемся не на графическую запись слова, а на его транскрипцию, которую предварительно следует составить.
Разбор слова позёмка
Каждый слог — это волна сонорности. Количество слогов равно количеству вершин сонорности. В данном примере таких вершин у нас три, значит в слове три слога. Но теория Аванесова позволяет не только верно определить количество слогов, но и не ошибиться с их границей. Главный ее постулат гласит: слог в русском языке строится по закону восходящей звучности — от наименее звучного звука к наиболее звучному, то есть слоговому. Из этой теории есть следующие следствия:
- Большинство слогов русского языка стремится к открытости, то есть к тому, чтобы оканчиваться на гласный. Например, [нα-у́-къ] наука, [ва́-зъ] ваза.
- Слог может заканчиваться на согласный звук только в трех случаях:
- в конце слова: [плα-то́к] платок, [рα-ш’-о́т] расчёт.
- на стыке сонорного и шумного в неначальном слоге. В таком случае сонорный отходит к предшествующему слогу, а шумный — к последующему: [за́м-шъ] замша, [бαл-ко́н] балкон.
- на стыке [u̯] и любого согласного. Звук [u̯] отходит к предшествующему слогу, а согласный — к последующему: [вαu̯-на́] война, [ма́u̯-къ] майка.

Последние два пункта требуют объяснения. Почему именно так? Дело в том, что в каждом из них рядом оказываются звуки, близость которых нарушает слоговую теорию восходящей звучности.
Например, сочетание сонорного и шумного согласного звука в переводе на цифровой индекс выглядело бы следующие образом: 3 (сонорный) и 2 или 1 (шумный). А внутри слога невозможно понижение, поэтому их необходимо разделить на разные слоги для возрастания звучности в последующем. То есть до гласного звучность должна только нарастать, а падать в других местах.
В случае же сочетания [u̯] и любого согласного у нас вновь то же самое нарушение, которое требует разделения этих двух звуков на разные слоги. Индексы: 3,5 (у [u̯] более высокий индекс, чем у остальных сонорных) и 1, 2 или 3 (любой согласный).
Индексы: 3,5 (у [u̯] более высокий индекс, чем у остальных сонорных) и 1, 2 или 3 (любой согласный).
Удивительно, как эта теория может описывать даже самые малые нюансы произнесения слов. Например, слово лбы. При произнесении этого слова мы вынуждены немного приглушать сонорный [л] до индекса последующего шумного согласного звука, иначе получится, что в слове два слога, а не один. И действительно, сравните звучание [л] в словах лира и лбы.
Именно из-за слоговой теории можно услышать скандирование [ша́u̯-бу] Шайбу!, а не *[ша́-u̯бу].
Еще один пример. Слово карман будет делиться на два слога и граница следующая: [кα-рма́н].
Наконец, нужно помнить о том, что фонетические слоги часто не совпадают с морфемным строением слова и правилам переноса.
| Фонетические слоги | Морфемное членение | Перенос слова |
| [ма-u̯о́р] | майор | май-ор |
| [сα-гла́-снъ] | со-глас-н-а | со-глас-на / сог-ла-сна |
Задания
- Определите, где по сонорной теории проходит слогораздел, если слово состоит из звуков с такими индексами сонорности.
4 2 3 4 3 4 3,5 4 1 4 3,5 1 4 - Разделите на слоги слово сентябрь.
- Подберите слово, состоящее из звуков следующей звучности и определите место слогораздела по теории Р. И. Аванесова.
4 1 3 4 1 4 1

Правила создания слова из букв и слогов
- Составление двухбуквенного слога, правило очень простое берется значение первой буквы и зеркальное отражение второй буквы.
Пример: БД = Б (внешнее, видимое, заметное) + Д (отделить, остановить), получаем «внешнее отделить, видимое выделение, выступ отделенный»
- Составление трехбуквенного слога, на примере разбора слова, правило очень простое, но не путайте с корнем слова.
Пример 1: РАЗ = Р (выделить, разделить) + АЗ (начало, источник), получаем «выделить начало, разделить начало, выделять источник и т. д.»
Пример 2: РА-З = РА (выделить, разделить) + З (завершено), получаем «выделение завершено, разделение завершить и т.д.»
- Составление четырехбуквенного слога, на примере разбора слова, правило очень простое, но не путайте с корнем слова.
- разбивка на 2 слога и первым что нужно сделать разбить на 2 слога: БР—ОД = БР (внешнее соединение, видимое соединение) + ОД (закреплено, ограничено, сужено), получаем «суженое видимое соединение, закрепленное внешнее соединение и т.д.».
- разбивка на букву и трехбуквенный слог: Б—РОД Б (внешне, видимо, выступ) + РОД (Р = выделять, разделять + ОД = закреплено, ограничено, сужено), получаем «внешнее выделение закреплено, видимое разделение закреплено и т.д.».
- разбивка на трехбуквенный слог и букву: БРО—Д БРО (Б = внешне, видимо, выступ + РО = выделение объема, разделять увеличивая объем) + Д (делать, создавать), получаем «внешнее выделение объема делает, создает видимое выделение/разделение и т. д.».
- Составление пятибуквенного слога, правило очень простое, но не путайте с корнем слова.
Пример: КОМОД = КО (увеличение, увеличение объема) + М (основа, внутри открыто) + ОД (закреплено, ограничено, сужено), получаем «увеличение основы закрепленной, т.е. выдвигаются ящики». Не буду приводить примеры разбивки на: К—ОМ—ОД, КО—МО—Д, попробуйте сами. Вы должны понимать в большинстве слов, основа именно КО—М—ОД, это правило разбивки 5-буквенных слов, если оно является корнем!
- И так далее, думаю вы поняли принцип. Например слово состоит из букв «АБВГДЕ», значит мы можем разбить на «АБВ-ГДЕ», «АБ-ВГ-ДЕ».
- БУКВА «Е» есть слова в которых скачут буквы как Р и ЕР (дЕРево, дРево | жРебий, жЕРебьёвка), Н и ЕН (камЕНь, камНи), то скорее всего это нужно рассматривать как Д-Р-ЕВ, К-АМ-Н.
- БУКВА «А», также может быть и буква «О» объединяющая, к примеру «АЦИЯ», как объединение
- БУКВА «И» также может быть и буква «О» объединяющая, как объединение
- БУКВА «ИА», также может быть и буква «О» объединяющая, к примеру «ИАТОР», как объединение
 д.»
д.» д.».
д.».
Корень слова может визуально совпадать со слогом, к примеру слово «ТЫ» и слог «ТЫ», слово «ТЫ» состоит из «Т и Ы», тоже самое и «ВЫ» и другие слова.
BayBenj / english-syllabifier: Инструмент для разбора английских фонем на слоги.
GitHub — BayBenj / english-syllabifier: Инструмент для разбора английских фонем на слоги.
Инструмент для разбора английских фонем на слоги.
Файлы
Постоянная ссылка
Не удалось загрузить последнюю информацию о фиксации.
Тип
Имя
Последнее сообщение фиксации
Время фиксации
Не хотите использовать словарь для данных по слогам? Я тоже! Сллабификатор позволяет вам разбирать фонемы на слоги, просто следуя фонотаксическим правилам языка.
Английский язык имеет 14 фонотаксических правил. Этот синтаксический анализатор слогов использует четырнадцать фонотаксических правил английского языка для создания слоговых последовательностей фонем.
Алгоритм работает:
- маркировка ядер слова ν
- добавление начала фонемы ω к каждому ядру ν при нарушении нофонотактического правила
- добавление остающихся кодовых фонем κ к каждому ядру ν при отсутствии нарушения фонотактического правила
Некоторые слова, нарушающие эти правила (например, слова неанглийского происхождения), могут быть неверно преобразованы в слоги.
Слоговое произведение
Слово — это последовательность слогов.Слог состоит из начала ω, ядра ν и кода κ. Ядро — это центральная гласная фонема. Начало — это согласная фонема (ы), предшествующая ядру. Кода — это согласная фонема (ы), следующая за ядром. И начало, и код могут быть пустыми.
Около
Инструмент для разбора английских фонем на слоги.
ресурсов
Вы не можете выполнить это действие в настоящее время.Вы вошли в систему с другой вкладкой или окном. Перезагрузите, чтобы обновить сеанс.
Вы вышли из системы на другой вкладке или в другом окне. Перезагрузите, чтобы обновить сеанс.
(PDF) Разбор слогов на английском и французском языках
Разбор слогов / стр.45
11. Ссылки
Ссылки
Блэк, Х. А. (1993) Ранговое определение по ограничению: последовательный подход к оптимизации
, Ph.D. диссертация, UCSC.
Брэдли, округ Колумбия, Санчес-Касас, Р.М., Гарсия-Альбеа, Дж.E. (1993) «Язык
,
специфические стратегии сегментации: I. Эффективность по сравнению с материалами на родном языке
», Язык и когнитивные процессы 8, 197-233.
Катлер А., Мехлер Дж., Норрис Д. и Сегуи Дж. (1983) «Стратегия понимания языка
», Nature 304, 159-160.
Катлер А., Мелер Дж., Норрис Д. и Сеги Дж. (1986) «Различная роль слога
в сегментации французского и английского языков», Journal of Memory
и Language 25, 385-400.
Дэвис, Стюарт (1985) «Вес слога в некоторых австралийских языках», BLS 11,
398-407.
Делл, Ф. (1973) Les règles et les sons, Герман, Париж.
Дюпу, Э. и Хаммонд, М. (в подпункте) «Слоговые эффекты в английском языке: роль
качества гласных».
Дюпу Э., Хаммонд М. , Мидор Д. и Охала Д. (1995) «Силлабификация в
, Мидор Д. и Охала Д. (1995) «Силлабификация в
английском языке и сложение ограничений».
Эллисон, Т. М. (1995) «Фонологический вывод в теории оптимальности»,
Труды пятнадцатой международной конференции по
Компьютерная лингвистика, 1007-1013.
Фонтан, А. (1994) «Просодическая структура в западных апачах», представлена на
WCCFL.
Хаммонд, М. (1992) «Поэтический метр и древесная сетка», Language 67,
240-259.
Хаммонд, М. (1993) «Ресиллабификация на английском языке», FLSM 4, 104-122.
Хаммонд, М. (1994) «Необязательность в стрессе Валматьяри», доктор медицины, Университет Аризоны,
Архив оптимальности Рутгерса.
Хейс, Брюс (1981) Метрическая теория правил стресса, докторская диссертация MIT 1980 г.
, пересмотренная версия, распространенная IULC, позже опубликованная
Гарланд, Нью-Йорк.
Hayes, B. (1982) «Экстреметричность и английское ударение», Linguistic Inquiry 13,
227-276.
Хейс, Б. (1987) «Пересмотренная параметрическая метрическая теория», NELS 17, 274-289.
Hayes, B. (1989) «Компенсаторное удлинение в моральной фонологии»,
Linguistic Inquiry 20, 253-306.
Ито, Дж., Р. А. Местер и Дж. Пэджетт (в печати) «NC», Linguistic Inquiry.
Кан, Д. (1976) Слоговые обобщения в английской фонологии, MIT
докторская диссертация, распространяется IULC.
Кипарский П. (1979) «Назначение метрической структуры циклично», Лингвистика
Справка 10, 421-441.
Китахара, М. (1994) «Генератор псевдослов», доктор философии, Университет Киото.
Маккарти, Дж. И А. Принс (1993) Взаимодействие с ограничениями и просодика
Морфология, доктор медицины, UMass & Rutgers.
Мидор, Д. и Д. Охала (1992) «Статус амбисложности в английском языке»,
представлен на LSA.
Принц А. (1990). «Количественные последствия ритмической организации»,
CLS 26.
Алгоритм
— Как проверить, есть ли в слове допустимые слоги или нет?
Всякий раз, когда мы собираем полную строку-образец, мы можем либо отбросить ее и начать сбор в новую строку-образец, либо оставить ее и попытаться получить более длинную строку-образец. Мы не знаем заранее (без изучения остальной части входной строки), следует ли нам сохранить или отбросить текущую строку, поэтому нам нужно иметь в виду обе возможности.
Мы не знаем заранее (без изучения остальной части входной строки), следует ли нам сохранить или отбросить текущую строку, поэтому нам нужно иметь в виду обе возможности.
Мы можем построить конечный автомат, который будет отслеживать это за нас.Базовые состояния идентифицируются последовательностью символов, которую мы уже исследовали:
Состояние C V
"" {"РЕЗЮМЕ",""}
"C" {"CC"} {"CV", ""}
"CC" {"CCC"} {""}
"CCC" {} {""}
"CV" {"CVC", ""} {}
"CVC" {""} {}
"V" {""} {}
Поскольку мы не всегда знаем, какое действие предпринять, мы можем находиться одновременно в нескольких возможных состояниях. Эти наборы возможных состояний образуют супер-состояния:
Индекс Суперсостояния C V
0 {} 0 0 сбой
1 {""} 2 9 Принять
2 {"C"} 3 8
3 {"CC"} 4 1
4 {"CCC"} 0 1
5 {"", "C"} 6 13 Принять
6 {"C", "CC"} 7 8
7 {"CC", "CCC"} 4 1
8 {"", "CV"} 12 9 Принять
9 {"", "V"} 5 9 Принять
10 {"", "C", "CC"} 11 13 Принять
11 {"C", "CC", "CCC"} 7 8
12 {"", "C", "CVC"} 10 13 Принять
13 {"", "CV", "V"} 12 9 Принять
Переходы между суперсостояниями. Каждый член супергосударства обозначается одним и тем же символом. Все участники без такого перехода отбрасываются. Если у члена есть два возможных пункта назначения, оба добавляются в новое суперсостояние.
Каждый член супергосударства обозначается одним и тем же символом. Все участники без такого перехода отбрасываются. Если у члена есть два возможных пункта назначения, оба добавляются в новое суперсостояние.
Вы могли заметить, что некоторые строки очень похожи. Суперсостояние 3 и 7 имеют одинаковые переходы. Как 6 и 11, 8 и 13. Вы можете свернуть их в одно состояние и обновить индексы. Я не собираюсь здесь демонстрировать это.
Это можно легко закодировать на языке программирования:
// индекс = 0 1 2 3 4 5 6 7 8 9 10 11 12 13
int [] consonant = new int [] {0, 2, 3, 4, 0, 6, 7, 4, 12, 5, 11, 7, 10, 12};
int [] vocal = new int [] {0, 9, 8, 1, 1, 13, 8, 1, 9, 9, 13, 8, 13, 9};
int [] accept = new int [] {0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1};
int startState = 1;
int failState = 0;
bool CheckWord (строковое слово)
{
int state = startState;
foreach (символ c в слове)
{
если (IsVocal (c))
{
состояние = вокал [состояние];
}
иначе, если (IsConsonant (c))
{
состояние = согласный [состояние];
}
if (state == failState) вернуть false;
}
return accept [состояние]! = 0;
}
Пример:
> CheckWord ("произношение")
правда
> CheckWord ("произношение")
ложный
Фонетика в Оксфордском университете
Амбисложность и перекрытие слогов
Фонетическая интерпретация в YorkTalk / IPOX является композиционной, то есть многосложные слова состоят из отдельных слогов. Как следствие, нет отдельных правил для интервокальных групп согласных.
Как следствие, нет отдельных правил для интервокальных групп согласных.
Амбисложность используется для обеспечения того, чтобы интервокальные согласные правильно коартикулировались с соседними гласными. То есть таким словом, как / bot @ l / , следует интерпретировать / t / :
- в виде кода с восстановлением предшествующей гласной
- как начало по отношению к следующей гласной
Таким образом, интервокальный / t / нужно разбирать как код первого слога и как начало второго слога:
В фонетической интерпретации начало накладывается на код предыдущего слога.В разных контекстах используются разные степени перекрытия (Coleman 1995):
- застежка очень короткая («хлопающая»)
--Гласная- | -Closing- | --- Закрытие --- | -Release- | ---
-Closure- | -Release- | -Vowel-- - нормальное межвокальное закрытие
--Гласная- | -Closing- | --- Закрытие --- | -Release- | ---
-Closure- | -Release- | -Vowel-- - длинная застежка («геминация»)
--Гласная- | -Closing- | --- Закрытие --- | -Release- | ---
-Closure- | -Release- | -Vowel--
Пример
Следующее правило используется для создания правильной степени перекрытия для амбисложных букв / t / в / bot @ l / :
минусов: [+ coda, VOICELESS, -cnt, -nas, str = A, cns = B, squish = C]
+
cons: [- coda, VOICELESS, -cnt, -nas, str = A, cns = B]
=>
C * (250 - A * 50) + 140.

В этом правиле признак squish кодирует степень сжатия, назначенную первому слогу.
Амбисложность не ограничивается отдельными интервокальными согласными (как в большинстве фонологических теорий). Внутри слов (латинских частей) интервокальные кластеры разбираются с максимальной амбисложностью :
Анализируя кластеры в квадратных скобках как амбисложные, мы получаем, что:
- в каждом из этих случаев первый слог тяжелый
- / t / в / wint @ r / без наддува, но в / sist @ m / без наддува, как это происходит в начальном кластере / st /
Реализация
- В YorkTalk согласные становятся амбисложными посредством синтаксического анализа (синтаксический анализ без использования ввода)
- В IPOX избыточный синтаксический анализ не допускается, поэтому на данный момент двусложные согласные должны быть записаны дважды во вводе
В качестве более принципиального решения в настоящее время мы экспериментируем с алгоритмом синтаксического анализа «голова впереди», адаптированным из Van Noord (1993):
parse (Input, L, R, Target): -
head (Target, Head),
input (Head, Input, L0, R0),
head_first (L0, L, R0, R, Head, Target).head_first (L0, L, R0, R, Head, Target): -
фраза -> (NonHead / Head),
parse (L0, L1, [], NonHead),
head_first (L1, L, R0, R, фраза, цель).
head_first (L0, L, R0, R, Head, Target): -
Phrase -> (Head \ NonHead),
parse (R0, [], R1, NonHead),
head_first (L0, L, R1, R, фраза, цель).
head_first (L0, L, R0, R, Head, Target): -
Phrase -> Head,
head_first (L0, L, R0, R, фраза, цель).
head_first (L, L, R, R, Цель, Цель).ввод (Головка, [Терминал | L], [], L): -
lex (Терминал, Голова). Вход
(Головка, [Терминал | L1], [Терминал | L2], L3): - Вход
(Головка, L1, L2, L3).

Этот алгоритм синтаксического анализа имеет следующие свойства:
- это «жадный» алгоритм, то есть он пытается проанализировать столько входных данных, сколько позволяет грамматика.
- дерево синтаксического анализа строится снизу вверх, начиная с заголовка компонента
Мы планируем использовать этот алгоритм следующим образом:
- слоги построены с использованием алгоритма head first
- между слогами допускаем перекрытие
Примеры
- / wint @ r / анализируется как / wint / + / t @ r /
- / asprin / анализируется как / asp / + / sprin /
- / sist @ m / анализируется как / sist / + / st @ m /
Также:
- / aspsprin / анализируется так же, как / asprin /
- / asprsprin / отклоняется, поскольку / r / остается без анализа
Формальная грамматика для слогов малаялам
Я писал о формальной грамматике для конъюнктов малаялам в последнем сообщении в блоге. Продолжая оттуда, давайте обсудим слоговую модель.
Продолжая оттуда, давайте обсудим слоговую модель.
Слог — это единица организации последовательности звуков речи. Каждый слог можно рассматривать как единицы произношения, составляющие произношение слова. Например, «മലയാളം» состоит из 4 слогов മ, ല, യാ, ളം. Если вы спросите носителя малаяламского языка: «Сколько букв в слове മലയാളം?» Ответ будет 4, что соответствует количеству слогов. Понятие «буква», известное как «അക്ഷരം» на малаялам, часто относится к слогам.
Наряду со словесным описанием слогов в малаялам мы пытаемся формализовать грамматику, используя грамматику PEG — Parser Expression. Затем эта грамматика используется для написания синтаксического анализатора, чтобы найти слоги в данном слове. Также предоставляется веб-интерфейс для опробования системы.
Прежде чем приступить к определению слоговой модели, нам необходимо определить некоторую терминологию.
Определения
-
Гласные— Гласные малаялама — Любой из набора: [അആഇഈഉഊഋഎഏഐഒഓഔഔഅം] -
VowelSign— Знаки гласных. — Любой из набора [ാിീുൃെേൊോൗൂൈ] -
Согласный— Согласный — Любой из набора [കഖഗഘങചഛജഝഞടഠഡഢണതഥദധനപഫബഭമയരലവശഷസഹളഴറ] -
Вирама— Знак ്. -
VisargaЗнак ഃ -
Анусвара— Гласный знак അം. Т.е. ം. Это разделяет некоторые свойства Chillu. -
Chillu— Чистые согласные, без гласных. Chillus — это любые из ൻ, ർ, ൽ, ൾ, ൺ, ൿ, ൔ, ൕ, ൖ. Последние 4 чиллуса используются редко или архаичны.Но мы можем учитывать их при моделировании. Из-за исторических причин кодирования Chillus также может отображаться как основная формаConsonant+Virama+ZWJ. Это означает, что ൻ = ന + ് +ZWJ. Chillus никогда не появляется в начале слова, но не имеет отношения к анализатору слогов. -
ZWNJБез стыковки с нулевой шириной. -
ZWJНоль со столяркой -
ЗнакиТермин, используемый для обозначения различных знаков, изменяющихСогласный. Любой из VowelSign,Virama,Anuswara,Visarga. -
Conjunct: см. Формальное определение этого, которое мы обсуждали в предыдущем сообщении в блоге. Мы определили его какConsonantв сочетании с другимConjunctилиConsonant, используяVirama. Пример: സ + ് + ത => സ്ത, സ്ത + ് + ര = സ്ത്ര. ദ്ധ + ് ര = ദ്ധ്ര, ദ്ധ്ര + ് + യ = ദ്ധ്ര്യ. Но нам нужна продвинутая версия. Это определение не поддерживало DotReph (ൎ), которое в сочетании с согласным или союзом образует Conjunct.Чтобы поддерживатьDotReph, мы переопределим Conjunct какHalfConsonant Conjunct / Consonant -
DotRephЗнак (ൎ). Он сочетается с другими согласными, как в этом примере: ൎ + യ -> ൎയ в ഭാൎയ -
HalfConsonant:Consonant, за которым следуетViramaПример: പ്, ര്, മ് и т. Д. ИлиDotReph
 — Любой из набора [ാിീുൃെേൊോൗൂൈ]
— Любой из набора [ാിീുൃെേൊോൗൂൈ] Любой из
Любой из Слоговая модель
Слог в малаялам может быть любым из следующих.
- Независимый
Гласный. Гласные часто встречаются в начале слова. Пример: അമ്മ. Но для конкретного случая слогов мы можем ослабить это правило нахождения в начале слова и в целом заявить, что гласная является слогом. Обратите внимание, что гласный звук в виде знака гласного — это не то, что мы рассматриваем здесь.Знаков гласных.имеет свои свойства. - Буква
чиллу— это слог. - A
Согласныйбез знаков - A
СогласныйилиСоединениесЗнаками— это слог. Здесь Знаки могут повторяться более одного раза, но не свободно. Этот слог имеет следующие характеристики:-
Знакимогут бытьВирама, только если это последние элементы данного слова. Например. അത് имеет അ, ത് как слоги, но അത്ഭുതം имеет അ, ത്ഭു, തം как слоги. -
Знакимогут встречаться 2 раза в следующих случаях: (а) Первый знак — ു, второй —ВирамаЭта комбинация также называется Самврутокарам. Пример: തു് в അതു്. (б) Первый знак — это знак гласной, а второй —анусвара. Примеры: താം, തീം, തോം, തും и т. Д.
-
- A
ZWNJотмечает границу слога. ZWNJ, вставленный между двумя блоками текста, вставляет лигатуру, а также границу слога. Например: തമിഴ്നാട്, ZWNJ, вставленный после ഴ് и перед നാ, предотвращает возможный ഴ്ന конъюнкт и, следовательно, также указывает на то, что произношение должно прерваться в этой точке. Сказать, что ZWNJ образует слог, немного странно, поскольку это просто разделитель.Но при анализе серии букв от начала до конца технически нормально рассматривать ZWNJ как блок слогов.
 Пример: തു് в അതു്. (б) Первый знак — это
Пример: തു് в അതു്. (б) Первый знак — это Грамматика выражений синтаксического анализатора
Вы можете попробовать это в оценщике PEG и попробовать различные конъюки, чтобы увидеть, все ли они анализируются. Используйте https://pegjs.org/online, скопируйте и вставьте приведенную выше грамматику, попробуйте ввести такие параметры, как «ശാസ്ത്രവിഷയങ്ങൾ».
Характеристики грамматики
Есть несколько важных характеристик этой грамматики.
Он выполняет определенные проверки по знакам .Например, он не допускает VowelSign , virama или anuswara после visarga . Если это произойдет, синтаксический анализатор не сможет разобрать слово. Это разрешает вираму после VowelSign , но это только для Samvruthokaram (знак гласной = ു).
Среди знаков можно увидеть Вираму, но это разрешено только в конце слова. Например: അത്. Если между словом встречается virama , это означает, что он совмещает согласные.
Также действует приказ Знаков . Например, у вас не может быть virama , а затем VowelSign ു, даже если разрешен обратный порядок.
Приведенные выше правила создают некоторую строгость для парсера. В то же время есть и смягченные правила. Максимального предела возможного соединения нет. Синтаксический анализатор принимает бессмысленные конъюнкты типа ‘’. Насколько мне известно, малаялам имеет действительные союзы до 5 (Пример: ഗ്ദ്ധ്ര്യ).Обычно у более длинных союзов заканчиваются согласные как യ, ര, ല, വ.
Синтаксический анализатор принимает бессмысленные конъюнкты типа ‘’. Насколько мне известно, малаялам имеет действительные союзы до 5 (Пример: ഗ്ദ്ധ്ര്യ).Обычно у более длинных союзов заканчиваются согласные как യ, ര, ല, വ.
В неформальном малаялам удвоение гласных иногда используется для обозначения удлинения. Например, വാടാാാ. Наш парсер этого не примет.
Границы слогов
Если вы хотите знать границы слогов и не заботитесь ни о чем другом, есть простой способ найти границы.
Граница слога после:
- Гласная. Обратите внимание, что это не гласный знак. Пример: അ | റ, ഇ | ര, ഉ | പ്പ്
- Гласный знак, если за ним не следует вирама, анусвара или висарга.Пример: ത്തി | ൽ, പു | ക,
- Согласная, если за ней следует другая согласная или чиллу. Пример: ത | റ, ഷ്ട | മി, ക | ൽ
- Чиллу. Пример: സ | ർ | പ്പം
- Анусвара. Пример: കു | ടും | ബം,
- A Visarga _._ Пример: ദുഃ | ഖം
- ZWNJ — граница слога.
Веб-интерфейс
Я подготовил веб-интерфейс, если вы просто хотите опробовать анализатор слогов и не хотите играть с PEG.
https://phon.smc.org.in
Теперь, когда в комплекте идет JS API, просто включите в свое веб-приложение следующий файл:
https: // phon.smc.org.in/syllables/lib/malayalam-syllables.js
Затем используйте следующий метод, чтобы разбить слово на слоги.
malayalamSyllableParser.parse (inputWord)
Я подготовил проект кода, чтобы продемонстрировать это.
См. Анализатор слогов Pen Malayalam от Santhosh Thottingal (@santhoshtr) на CodePen.
Исходный код
https://github.com/santhoshtr/malayalam-syllable-analyser
Пожалуйста, сообщайте здесь о любых проблемах или идеях по улучшению этой модели. Спасибо!
Спасибо!
| ДОМ Урок 1 Переуступка Урок 2 Переуступка Урок 3 Переуступка Урок 4 Переуступка Урок 5 Переуступка Урок 6 Переуступка Урок 7 Переуступка Урок 8 Переуступка Урок 9 Переуступка |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Урок 3 — Число , Случай , Пол , Существительные 2-го склонения , Определенная статья 168 , Enulative Проклитика | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Номер | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Корпус | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Пол | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2-я Склонение | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Правила ударения существительных | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Разбор | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| The Определенная статья | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Глагол «быть» | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Энклитики & Proclitics | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Краткое содержание урока 3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Назначение 3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


 Если слово функционирует как
Если слово функционирует как (А. Т. Робертсон взял
(А. Т. Робертсон взял Мы начнем с
Мы начнем сСлоги | Психология вики | Фэндом
Оценка |
Биопсихология |
Сравнительный |
Познавательная |
Развивающий |
Язык |
Индивидуальные различия |
Личность |
Философия |
Социальные |
Методы |
Статистика |
Клиническая |
Образовательная |
Промышленное |
Профессиональные товары |
Мировая психология |
Язык:
Лингвистика ·
Семиотика ·
Речь
слог (древнегреческий: συλλαβή) — единица организации последовательности звуков речи.Обычно он состоит из ядра слога (чаще всего гласного) с необязательными начальными и конечными полями (обычно согласными).
Слоги часто считаются фонологическими «строительными блоками» слов. Они могут влиять на ритм языка, его просодию, поэтический размер, характер ударения и т. Д.
Слово, состоящее из одного слога (например, английский cat ), называется односложным (такое слово — односложное ), а слово, состоящее из двух слогов (например, обезьяна ), называется двусложное (такое слово двусложное ).
Общая структура слога состоит из следующих сегментов:
- Начало (обязательно для некоторых языков, необязательно для других)
- Иней
- Ядро (обязательно на всех языках)
- Coda (необязательно в некоторых языках, строго ограничено или запрещено в других)
Древовидное представление слога CVC
В некоторых теориях фонологии эти структуры слогов отображаются в виде древовидных диаграмм (похожих на деревья, встречающиеся в некоторых типы синтаксиса).
Слоговое ядро обычно является сонорным, обычно гласным звуком в форме монофтонга, дифтонга или трифтонга, но иногда и сонорными согласными, такими как [l] или [r]. Начало слога — это звук или звуки, встречающиеся перед ядром, а слог coda (буквально «хвост») — это звук или звуки, следующие за ядром. Термин rime охватывает ядро плюс код. В односложном английском слове cat, ядро - a, начало c, код t, и иней at. Этот слог можно абстрагировать как согласный-гласный-согласный слог, сокращенно CVC.
Как правило, каждый слог требует ядра. Начало чрезвычайно распространено, и в некоторых языках требуется, чтобы все слоги имели начало. (То есть, слог CVC, например cat , возможен, но слог VC, такой как на — нет.) Слог без кода формы V, CV, CCV и т. Д. Называется открытым слогом , а слог с кодом (VC, CVC, CVCC и т. д.)) называется закрытым слогом (или проверяемым слогом). Все языки допускают открытые слоги, но некоторые, например гавайский, не имеют закрытых слогов.
Тяжелый слог — это слог с ветвлением или ветвящееся ядро — это метафора, основанная на ядре или коде, имеющем линии, которые ветвятся на древовидной диаграмме. В некоторых языках тяжелые слоги включают в себя как CVV (ветвящееся ядро), так и CVC (ветвящееся время), в отличие от CV, который представляет собой легкий слог .В других языках только слоги CVV (с длинной гласной или дифтонгом) тяжелые, а слоги CVC и CV — легкие. Разница между тяжелым и легким часто определяет, какие слоги получают ударение — например, в латинском и арабском языках. В теории морали у тяжелых слогов есть две мора, а у легких слогов — одна. Японский обычно описывают именно так.
В других языках, включая английский, согласный звук может быть проанализирован как действующий одновременно как код одного слога и начало следующего слога, явление, известное как амбисложность.
Слоги и надсегменты [править | править источник]
Область супрасегментных характеристик — это слог, а не конкретный звук, то есть они влияют на все сегменты слога:
Иногда длина слога также считается надсегментарной характеристикой; например, в большинстве германских языков длинные гласные могут существовать только с короткими согласными и наоборот. Однако слоги можно анализировать как составы длинных и коротких фонем, как в финском и японском языках, где родство согласных и длина гласных независимы.
Слоги и фонотаксические ограничения [править | править источник]
Фонотаксические правила определяют, какие звуки разрешены или запрещены в каждой части слога. Английский позволяет использовать очень сложные слоги; слоги могут начинаться максимум с трех согласных (как в , строка или , всплеск ) и иногда заканчиваться целыми четырьмя (как в подсказывает или шестых ). Многие другие языки гораздо более ограничены; Японский, например, допускает только / n / и хронему в коде и не имеет вообще никаких групп согласных, так как начало состоит не более чем из одного согласного.
Существуют языки, запрещающие пустые буквы, иврит, арабский и многие разновидности немецкого (имена, транслитерированные как «Израиль», «Авраам», «Омар», «Али» и «Абдулла», среди многих других, фактически начинаются с полусонусными звуками или с голосовыми или глоточными согласными).
Этот раздел является незавершенным. Вы можете помочь, дополнив это.
Структура слога часто взаимодействует с ударением. В латыни, например, ударение обычно определяется весом слога, слог считается тяжелым, если имеет хотя бы одно из следующего:
- долгая гласная в ядре
- дифтонг в ядре
- одна или несколько кодов (e)
В каждом случае считается, что у слога есть два мора.
Слоги и напряжение гласных [править | править источник]
В большинстве германских языков слабые гласные встречаются только в закрытых слогах. Следовательно, эти гласные также называются проверяемыми гласными , в отличие от напряженных гласных, которые называются свободными гласными , потому что они могут встречаться в открытых слогах.
Понятие слога оспаривается языками, которые допускают использование длинных последовательностей согласных без каких-либо промежуточных гласных или соноратов. Этим известны языки северо-западного побережья Северной Америки, в том числе салишанский и вакашанский языки.Например, эти слова Nuxálk (Bella Coola) содержат только препятствия:
- [ɬχʷtɬʦxʷ] ‘ты плюнул на меня’
- [ʦ’ktskʷʦ ’]» он прибыл «
- [xɬp’χʷɬtɬpɬɬs] «у него было растение гроздья» (Bagemihl 1991: 589, 593, 627)
- [sxs] ‘тюленький жир’
В обзоре предыдущих анализов Багемила он обнаружил, что слово [ʦ’ktskʷʦ ‘] было бы разбито на 0, 2, 3, 5 или 6 слогов в зависимости от того, какой анализ использовался. .Один анализ рассматривал бы все сегменты гласных и согласных как ядра слогов, другой рассматривал бы только небольшое подмножество в качестве кандидатов в ядра, а третий просто полностью отрицал бы существование слогов.
Об этом типе явления также сообщалось в берберских языках (таких как Imdlawn Tashlhiyt Berber) и мон-кхмерских языках (таких как Semai, Temiar, Kammu).
Imdlawn Tashlhiyt Berber:
- [tftktst tfktstt] «вы растянули его, а затем дали»
- [rkkm] ‘гниль’ (imperf.) (Dell & Elmedlaoui 1985, 1988)
Semai:
- [kckmrʔɛːc] ‘короткие, толстые руки’ (Sloan 1988)
Ссылки и рекомендуемая литература [править | править источник]
- Bagemihl, Брюс (1991). Слоговая структура в Bella Coola. Лингвистический справочник 22 : 589–646.
- Dell, F .; Эльмедлауи, М. (1985). Слоговые согласные и слоговая форма в Imdlawn Tashlhiyt Berber. Журнал африканских языков и лингвистики 7 : 105-130. (цитируется по Bagemihl 1991).
- Dell, F .; Эльмедлауи, М. (1988). Слоговые согласные в берберском: некоторые новые свидетельства. Журнал африканских языков и лингвистики 10 : 1-17. (цитируется по Bagemihl 1991).
- Ladefoged, Питер (2001).