|
1. |
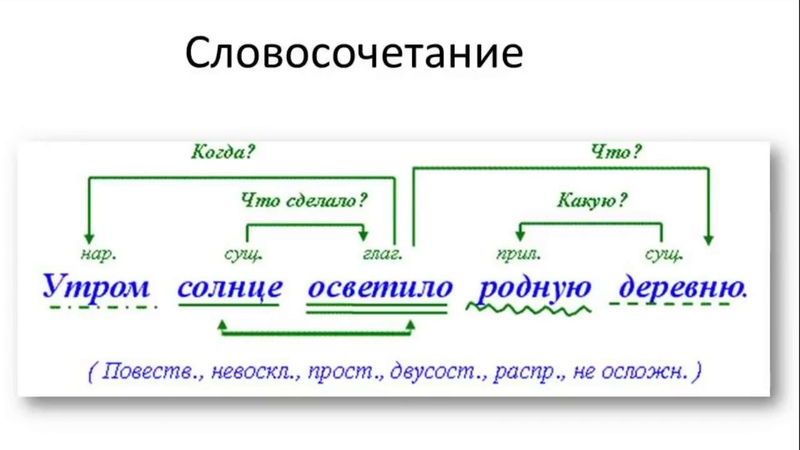
Как на ОГЭ (1). Синтаксический разбор
|
1 |
|
2. |
Как на ОГЭ (2).  Синтаксический разбор Синтаксический разбор
|
1 |
|
3. |
Как на ОГЭ (3). Синтаксический разбор
|
1 |
|
4. 
|
Как на ОГЭ (4). Синтаксический разбор
|
1 |
Порядок синтаксического разбора сложносочинённого предложения
План разбора:
Вид предложения
по цели высказывания (повествовательное,
вопросительное или побудительное).Вид предложения
по эмоциональной окраске (восклицательное
или невосклицательное).
Сложное.
Союзное.
Сложносочинённое.
Количество частей
в составе сложного, их границы (выделить
грамматические основы в простых
предложениях).Средства связи
между частями (указать союзы и определить
значение сложного предложения).Схема предложения.

Образец разбора:
Была
зима,
но все последние дни стояла
оттепель.
(И.Бунин).
(Повествовательное,
невосклицательное, сложное, союзное,
сложносочинённое, состоит из двух
частей, между первой и второй частями
выражено противопоставление, части
соединены противительным союзом но.)
Схема предложения:
[ ]1,
но [ ]2.
Порядок синтаксического разбора сложноподчинённого предложения
План разбора:
Вид предложения
по цели высказывания (повествовательное,
вопросительное или побудительное).Вид предложения
по эмоциональной окраске (восклицательное
или невосклицательное).Сложное.

Союзное.
Сложноподчинённое.
Количество частей
(выделить грамматические основы в
простых предложениях).Главная и придаточная
части.Что распространяет
придаточная часть.Чем присоединяется
придаточная часть.Расположение
придаточной части.Тип придаточной
части.Схема сложноподчинённого
предложения.
Образец разбора:
Когда она
играла
внизу на рояле1,
я
вставал
и слушал2.
(А.П. Чехов)
(Повествовательное,
невосклицательное, сложное, союзное,
сложноподчинённое, состоит из двух
частей. 2-я часть главная, 1-я – придаточная,
2-я часть главная, 1-я – придаточная,
придаточная часть распространяет
главную часть и присоединяется к ней
союзом когда,
придаточная часть располагается перед
главной, тип придаточной части –
придаточное времени).
Схема предложения:
Когда?
(союз когда…)1,
[ … ]2.
придаточное
времени
Сущ.. глаг. союз мест. Глаг.
пр. прил. сущ.
Путники
увидели,
что они
находятся
на
маленькой
поляне.
(Повеств., невоскл., сложное, СПП с прид.
изъяснительным, 1) нераспр., двусост.,
полное. 2) распр., двусост., полдное).
[
____
], (что…).
Порядок синтаксического разбора бессоюзного сложного предложения
План разбора:
Вид предложения
по цели высказывания (повествовательное,
вопросительное или побудительное).Вид предложения
по эмоциональной окраске (восклицательное
или невосклицательное).Сложное.
Бессоюзное.
Количество частей
(выделить грамматические основы в
простых предложениях).Схема предложения.

Образец разбора:
Песенка кончилась1
– раздались обычные рукоплескания2.
(И.С. Тургенев)
(Повествовательное,
невосклицательное, сложное, бессоюзное,
состоит из двух частей, первая часть
указывает на время действия того, о чём
говорится во второй части, между частями
ставится тире.)
Схема предложения:
[]1 — []2 .
17
Страница 2 из 2 • В проверке цели проверяется, какие листья дерева синтаксического анализа точно соответствуют входной строке, без неизвестных и неохваченных входных данных. Одна существенная проблема при нисходящем синтаксическом анализе возникает, когда приходится сталкиваться с так называемыми леворекурсивными правилами, т.е. правилами в формеПри поиске в глубину применение такого правила может привести к тому, что замена X на [X: х…] будет осуществляться в бесконечном цикле. А при поиске в ширину можно будет успешно найти варианты синтаксического анализа для допустимых предложений, но при наличии недопустимого предложения может возникнуть такая ситуация, что программа не сможет выйти из бесконечного пространства поиска. Ниже приведено описание восходящего синтаксического анализа как задачи поиска. • Начальным состоянием является список слов во входной строке, где каждое из слов рассматривается как дерево синтаксического анализа только с одним листовым узлом, например [the,wumpus, is,dead]. Вообще говоря, каждое состояние в пространстве поиска представляет собой список деревьев синтаксического анализа. • С помощью функции определения преемника выполняется поиск в каждой позиции i списка деревьев и в каждой правой части правила грамматики. Если подпоследовательность списка деревьев, начинающаяся с i, согласуется с правой частью, то эта подпоследовательность заменяется новым деревом, категорией которого является левая часть правила, а дочерними узлами — эта подпоследовательность. Под «согласованием» подразумевается, что категория узла является такой же, как и элемент в правой части. Например, правило согласуется с подпоследовательностью, состоящей из первого узла в списке [the,wumpus, is,dead], поэтому состоянием-преемником становится [ [Article: the] ,wumpus, is, dead]. • В проверке цели проверяется наличие состояния, представляющего собой единственное дерево с корнем S. Пример восходящего синтаксического анализа приведен в табл. 22.2. И нисходящий, и восходящий синтаксический анализ может оказаться неэффективным из-за того, что отдельные этапы синтаксического анализа различных сочетаний могут комбинироваться самыми разными способами. Таблица 22.2. Трассировка восходящего синтаксического анализа строки «The wumpus is dead». Работа начинается со списка узлов, состоящего из отдельных слов. После этого происходит замена подпоследовательностей, соответствующих правой части правила, новым узлом, корнем которого является левая часть правила. Например, в третьей строке показано, как узлы Article и Noun заменяются узлом WP, для которого эти два узла являются дочерними. Нисходящий синтаксический анализ приводит к выработке аналогичной трассировки, но в противоположном направлении Но даже если бы существовала идеальная эвристическая функция, позволяющая осуществлять поиск без ненужных отступлений, эти алгоритмы все равно были бы неэффективными, поскольку для некоторых предложений количество деревьев синтаксического анализа измеряется экспоненциальной зависимостью.
|

 И в той и в другой процедуре могут возникать непроизводительные затраты времени, связанные с поиском в тех частях пространства состояний, которые не позволяют получить требуемый результат. При нисходящем синтаксическом анализе иногда создаются промежуточные узлы, которые так и не удастся связать со словами, а при восходящем синтаксическом анализе создаются частичные фрагменты синтаксического анализа слов, которые невозможно преобразовать в корневой узел S.
И в той и в другой процедуре могут возникать непроизводительные затраты времени, связанные с поиском в тех частях пространства состояний, которые не позволяют получить требуемый результат. При нисходящем синтаксическом анализе иногда создаются промежуточные узлы, которые так и не удастся связать со словами, а при восходящем синтаксическом анализе создаются частичные фрагменты синтаксического анализа слов, которые невозможно преобразовать в корневой узел S. В следующем подразделе показано, как найти выход из этой ситуации.
В следующем подразделе показано, как найти выход из этой ситуации.Goldlit ru синтаксический разбор — Вэб-шпаргалка для интернет предпринимателей!
Введите слово или предложение и получите морфологический разбор с указанием части речи, падежа, рода, времени и т.д.
Начальная форма: СИНТАКСИЧЕСКИЙ
Часть речи: прилагательное
Грамматика: единственное число, именительный падеж, мужской род, неодушевленное, одушевленное
Формы: синтаксический, синтаксического, синтаксическому, синтаксическим, синтаксическом, синтаксическая, синтаксической, синтаксическую, синтаксическою, синтаксическое, синтаксические, синтаксических, синтаксическими, синтаксически
Начальная форма: РАЗБОР
Часть речи: существительное
Грамматика: единственное число, именительный падеж, мужской род, неодушевленное
Формы: разбор, разбора, разбору, разбором, разборе, разборы, разборов, разборам, разборами, разборах
Начальная форма: ПРЕДЛОЖЕНИЕ
Часть речи: существительное
Грамматика: единственное число, неодушевленное, родительный падеж, средний род
Формы: предложение, предложенье, предложения, предложенья, предложению, предложенью, предложением, предложеньем, предложении, предложеньи, предложений, предложениям, предложеньям, предложениями, предложеньями, предложениях, предложеньях
Часто пользователи ищут в Интернете способ разбора предложения по частям речи онлайн. Это необходимо не только школьникам при подготовке домашнего задания, но и людям, учащимся в университетах филологии и лингвистике. А также всем, кому каждый день приходится работать с текстом. Чтобы сделать синтаксический разбор предложения человек должен обладать необходимыми знаниями в этой области. Чтобы облегчить этот процесс можно обратиться к специальным онлайн сервисам. Ниже мы разберем несколько лучших сайтов по автоматическому разбору предложения на части речи.
Это необходимо не только школьникам при подготовке домашнего задания, но и людям, учащимся в университетах филологии и лингвистике. А также всем, кому каждый день приходится работать с текстом. Чтобы сделать синтаксический разбор предложения человек должен обладать необходимыми знаниями в этой области. Чтобы облегчить этот процесс можно обратиться к специальным онлайн сервисам. Ниже мы разберем несколько лучших сайтов по автоматическому разбору предложения на части речи.
Пример анализа предложения
Общие правила разбора предложения на части речи
Такой разбор в начальных и средних школах принято называть «разбор по членам предложения». Иногда говорят «разбор предложения по составу», но это выражение несколько некорректно, потому как по составу принято разбирать слова.
Чтобы сделать синтаксический разбор предложения:
- Нужно определить каким оно является по цели высказывания – побудительным, вопросительным или повествовательным.
- Определить на наличие грамматических основ – сложное (две и более основы), простое (одна основа).
- Определить эмоциональный характер предложения – восклицательное или невосклицательное.

Синтаксический разбор предложения
Наличие синтаксических конструкций предложения, его параметров, а также богатство вариантов конструирования создают для разработчиков приложения большие преграды при создании оналйн сервиса по разбору предложения. Поэтому таких сервисов в сети не так уж и много. Но они все же есть.
Goldlit – сервис морфологического и синтаксического разбора предложения
Очень удобный сервис Goldlit. Простой дизайн и понятный интерфейс делают сайт доступным людям, с разным уровнем знания компьютера. В верхней строчке меню находятся 3 пункта с выпадающим списком.
В верхней строчке меню находятся 3 пункта с выпадающим списком.
Чтобы воспользоваться разбором предложения по частям речи на сервисе goldlit.ru:
- Перейдите на сайт — http://goldlit.ru/.
- Под меню находится строчка, в которую нужно ввести текст для разбора.
- Рядом с окном ввода текста находится кнопка «Разбор».
Сразу под строкой ввода текста, в желтом поле идут подряд вниз блоки с разбором. Каждый блок – это одно слово из предложения. Чередуются они в таком же порядке, как и чередуются слова в предложении. Части блока:
- Слово, которое стоит в начальной форме.
- Второй строкой выступает часть речи, которым является слово.
- Грамматика. Пишутся через запятую число, качество, одушевленная форма, род и т.д.
- Формы. Все существующие формы слова (с приставками, суффиксами, оконачаниями).
Seosin – сайт, который имеет сервис разбора предложения по частям речи
Один из известных ресурсов в Интернете, который предоставляет инструмент для синтаксического и морфологического разбора предложения в режиме онлайн. Помимо этого сайт предлагает и другие сервисы по работе с текстом, например – синонимайзер. А также по работе с другими файлами, такими как изображения и фотография. Сайт периодически имеет проблемы с доступом, хотя администратор пишет в объявлениях на сайте, что ситуация с сервером была исправлена.
Помимо этого сайт предлагает и другие сервисы по работе с текстом, например – синонимайзер. А также по работе с другими файлами, такими как изображения и фотография. Сайт периодически имеет проблемы с доступом, хотя администратор пишет в объявлениях на сайте, что ситуация с сервером была исправлена.
Чтобы проверить текст в сервисе:
- Перейдите по этой ссылке – http://www.seosin.ru/.
- Введите текст для анализа в поле сервиса.
- Нажмите кнопку «Анализировать».
Через несколько секунд вам будет предоставлен разбор вашего текста с пояснениями.
Другие сайты и по разбору предложений по частям речи
Помимо автоматических сервисов онлайн существую также специальные сайты, на которых предоставляется вся необходимая информация, которая потребуется для синтаксического и морфологического разбора предложения. Одним из таких сайтов есть – сентябрята.рф. Для школьников он будет незаменим. Что касается русского языка, здесь вы найдете разделы:
- Слово – основные правописания слов с предлогами, частицами, перенос слов и т. д (онлайн проверка правописания).
- Вместе или раздельно – прилагательных, существительных, союзы, междометия.
- Безударные частицы «Не» и «Ни»
- Правила написания согласных – двойных «нн», «жж».
- Согласные, которые пишутся за шипящими – «ж, ч, ш, щ».
- Правописание гласных.
- Безударные главсные.
- Буквы «ь» и «ъ».
- Предложение.
- Аббревиатуры.
- Прописные буквы.
 д (онлайн проверка правописания).
д (онлайн проверка правописания).Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.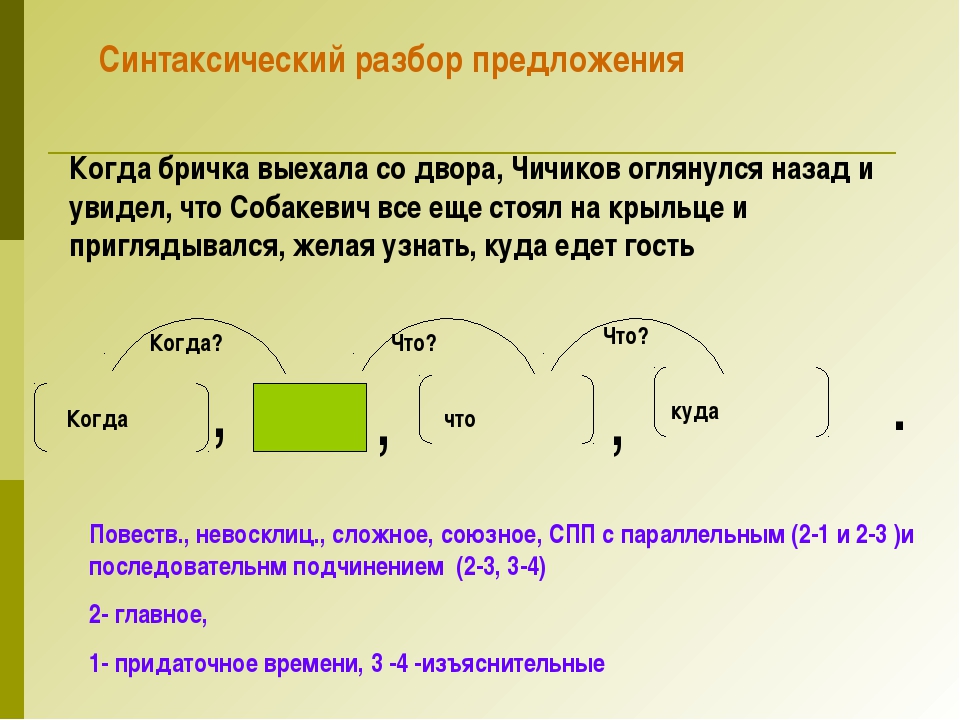
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Справочная информация
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое – это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое – это глагол, т.е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение – второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта – было бы скучно, уж поверьте. Итак, обстоятельство – это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?». А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной – важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» — как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Слово «дремучий» — как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая – придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой – как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т.е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется – оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола – действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость. Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны. Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Рекомендуем к прочтению
Все о синтаксическом анализе: что это такое и как оно связано с программным обеспечением для преобразования текста в речь | Алекс Кителингер | Voice Tech Podcast
Суть этого, помимо прекрасного предлога, заставляющего всех вас услышать немного классической игры слов, заключается в том, чтобы показать, что наличия всех слов во фразе недостаточно, чтобы получить ее полное значение во многих словах. случаи. Мы, люди, чертовски хорошо умеем интерпретировать значение предложения из контекста (идите, люди!), Но для машин это сложный процесс. Когда мы говорим о синтаксическом анализе в компьютерной лингвистике, эти предложения должны интерпретироваться с помощью установленной грамматики: установленного набора правил того, как работает данный язык, чтобы определить, что является «грамматическим», а что нет.Это используется в качестве основы для разбивки предложения на возможные интерпретации. Я говорю «возможно» здесь очень сознательно, поскольку человеческие языки в целом (конечно, английский) имеют большую тенденцию к двусмысленности. Обычно это достигается с помощью одного из нескольких методов машинного обучения; большая часть этого основана на частоте определенных типов высказываний. В одном из первоначально предложенных методов синтаксического анализа (с использованием вероятностных контекстно-свободных грамматик ) неоднозначное предложение будет сравниваться с другими экземплярами того же или аналогичного предложения и просто давать вероятность каждой данной интерпретации.С тех пор мы прошли долгий путь, но есть, что рассказать… так что я не буду! По крайней мере, не сегодня.
Более интересным, пожалуй, является текущая реализация того, как работают наши голосовые помощники. Alexa, например, не выполняет всю эту тяжелую работу локально (как и другие, хотя это может быть не всегда …) Ваше устройство Echo примет звуковой файл, который он получил (прочтите мой последний пост, если вы любопытно, как работает эта магия), и передать его в службу Alexa, размещенную в облаке Amazon, и основная часть обработки выполняется там.Даже в этом случае работа очень урезана по сравнению с этой весомой сравнительной моделью. Alexa действует на основе нескольких ключевых элементов, которые она ищет в запросе, и использует их для определения основного значения того, что вы ищете. Ниже приведен пример запроса из отличного руководства для тех, кто хочет получить краткий обзор начала разработки для устройств с поддержкой Alexa:
Способ анализа запроса Alexa (вверху) и данные, которые он отправляет навыку (внизу) (Источник)
Эти и большинство примеров такого же типа запросов от голосовых помощников заметно упрощены, так как все, что действительно нужно сделать, это определить названия вызова и навыков, а затем проанализировать, где «высказывание» ”Есть и будет основываться только на этом небольшом фрагменте.Даже в этом случае гораздо проще разобрать, когда структура запроса уже известна; вы просите устройство выполнить за вас задачу, и это сильно ограничивает возможности того, что вы могли бы сказать.
В этом много всего, и я только начинаю царапать поверхность, но суть в том, что «разбор» того, что вы говорите за пределами виртуальных помощников, — это огромное испытание, связанное с ошибками и несоответствиями, особенно если учесть, что то, как мы, люди, говорим, откровенно говоря, содержит ошибки и несоответствия.Даже в этом ограниченном контексте, который мы оцениваем с помощью Alexa, предстоит проделать большую работу. Я определенно планирую продолжить копаться в мельчайших деталях того, что происходит от A до B, но я надеюсь, что этот небольшой взгляд был, по крайней мере, немного проницательным!
Что означает анализ HTML?
В отличие от того, что сказал Спадли, синтаксический анализ сводится к разложению (предложения) на его составные части и описанию их синтаксических ролей.
Согласно Википедии, синтаксический анализ — это процесс анализа строки символов на естественном языке или на компьютерных языках в соответствии с правилами формальной грамматики.Термин синтаксический анализ происходит от латинского pars (orationis), что означает часть (речи).
В вашем случае синтаксический анализ HTML заключается в следующем: ввод HTML-кода и извлечение соответствующей информации, такой как заголовок страницы, абзацы на странице, заголовки на странице, ссылки, полужирный текст и т. Д.
Парсеры:
Компьютерная программа, анализирующая содержимое, называется синтаксическим анализатором. Всего существует 2 вида парсеров:
Нисходящий синтаксический анализ — Нисходящий синтаксический анализ можно рассматривать как попытку найти самые левые производные входного потока путем поиска деревьев синтаксического анализа с использованием нисходящего расширения заданных формальных правил грамматики.Жетоны расходуются слева направо. Включающий выбор используется для устранения двусмысленности путем расширения всех альтернативных правых частей правил грамматики.
Анализ снизу вверх — синтаксический анализатор может начать с ввода и попытаться перезаписать его на начальный символ. Интуитивно синтаксический анализатор пытается найти самые основные элементы, затем элементы, содержащие их, и так далее. Парсеры LR являются примерами восходящих парсеров. Другой термин, используемый для этого типа синтаксического анализатора, — это синтаксический анализ Shift-Reduce.
Несколько примеров парсеров:
Нисходящие синтаксические анализаторы:
Анализаторы снизу вверх:
Пример парсера:
Вот пример парсера HTML на python:
из HTMLParser импорт HTMLParser
# создать подкласс и переопределить методы обработчика
класс MyHTMLParser (HTMLParser):
def handle_starttag (self, tag, attrs):
print "Обнаружен начальный тег:", тег
def handle_endtag (сам, тег):
print "Обнаружен конечный тег:", тег
def handle_data (self, data):
print "Обнаружены некоторые данные:", data
# создать экземпляр парсера и передать ему HTML
parser = MyHTMLParser ()
парсер.feed (' Тест '
' Разбери меня!
')
Вот результат:
Обнаружен начальный тег: html. Обнаружен начальный тег: голова Обнаружен начальный тег: title Обнаружены некоторые данные: Тест Обнаружен конечный тег: заголовок Обнаружен конечный тег: голова Обнаружен начальный тег: body Обнаружен начальный тег: h2 Обнаружил некоторые данные: Разбери меня! Обнаружен конечный тег: h2 Обнаружен конечный тег: body Обнаружен конечный тег: html
Список литературы
Data Parser — Что такое анализ данных
В этой части мы будем объяснять концепции и алгоритмы, которые задействованы в синтаксическом анализе данных, чтобы вы могли лучше понять, что происходит.Здесь мы будем иметь дело с тремя частями:
- Компоненты и термины парсера данных
- Грамматики
- Алгоритмы
1. КОМПОНЕНТЫ И УСЛОВИЯ ПАРАМЕТРА ДАННЫХ
A. ОБЫЧНЫЕ ВЫРАЖЕНИЯ
Регулярные выражения — это последовательность символов, имеющих шаблон. Несмотря на то, что они обычно считаются непригодными для синтаксического анализа, их можно использовать для синтаксического анализа простых входных данных. Заблуждение связано с ошибками, которые возникают, когда регулярные выражения используются для анализа всего, включая то, для чего они не предназначены.Когда это будет сделано, все закончится серией хрупких регулярных выражений, которые мы взломали вместе.
Регулярные выражения также можно использовать для анализа некоторых простых языков программирования. Не все языки можно анализировать с помощью регулярных выражений, а языки, которые можно использовать, называются регулярными языками. Регулярные языки также можно анализировать с помощью конечного автомата, и, поскольку он также является мощным, его можно использовать для реализации лексеров.
Хотя вы можете определить регулярный язык, используя ряд регулярных выражений, для более сложных языков требуется нечто большее.Как правило, если грамматика языка содержит элементы, которые рекурсивны или вложены, это не обычный язык. Экземпляр — HTML. Он может содержать произвольное количество тегов внутри другого тега, поэтому его нельзя назвать обычным языком. В более широком смысле, его нельзя проанализировать, используя только регулярные выражения, независимо от того, насколько квалифицирован синтаксический анализатор.
Регулярные выражения в грамматике
Поскольку большинство программистов знакомы с регулярными выражениями, они часто используются для определения грамматики языка.Их синтаксис более точно используется для определения правил парсера или лексера. Например, звезда Клини применяется в правиле как индикатор того, что конкретный элемент может присутствовать любое количество раз, начиная от нуля до бесконечности.
Правило отличается от реализации лексического анализатора или анализатора. Вы можете использовать механизм регулярных выражений вашего языка для реализации лексера. Для еще большей производительности регулярные выражения в грамматике преобразованы в конечный автомат.
Б. СТРУКТУРА A-PARSER
Полный синтаксический анализатор обычно состоит из двух частей; лексер, также известный как сканер или токенизатор, и соответствующий синтаксический анализатор. Синтаксический анализатор работает не непосредственно с текстом, а только с выводом лексического анализатора, поэтому ему нужен лексер. Однако некоторые парсеры не имеют отдельного лексера, а скорее объединяют лексер и парсер. Они называются парсерами сканеров.
Лексический анализатор сначала сканирует ввод, а затем создает соответствующие токены, после чего анализатор просматривает токены и выдает результат синтаксического анализа.
Бесканерные анализаторы
Бессканерные синтаксические анализаторы отличаются по способу работы, поскольку они действуют непосредственно на исходный текст, а не на токены, созданные лексером. Таким образом, синтаксический анализатор без сканирования действует и как лексер, и как синтаксический анализатор.
Неважно определять грамматику, но для целей отладки вам нужно знать, является ли анализатор без сканирования или нет.
C. ГРАММАТИКА
Грамматические правила, описывающие язык синтаксически.Грамматика описывает язык, и это применимо только к синтаксису, но не к семантике. Это означает, что грамматика определяет структуру языка, а не его значение. Чтобы убедиться в правильности ввода, необходимо проверить его каким-либо другим способом.
Например, представьте, что нужно определить грамматику для языка, показанного в определении абзаца;
ПРИВЕТ: «Привет»
НАЗВАНИЕ: [a-zA-z] +
Приветствие: ПРИВЕТ ИМЯ
Допустимый ввод грамматики: «Привет, Майкл» и «Привет, программирование».В любом случае они правы. Однако, поскольку «Программирование» — это не название, оно неверно семантически.
АНАТОМИЯ ГРАММАТИКИ
Существует несколько часто используемых форматов для описания грамматики, например, форма Бэкуса-Наура (BNF). У этого формата есть варианты, одним из которых является Расширенная форма Бэкуса-Наура, и его преимуществом является простота обозначения повторения. Другой вариант BNF — это расширенная форма Бэкуса-Наура. Это полезно при описании протоколов двунаправленной связи.При использовании грамматики Бэкуса-Наура типичное правило имеет следующее представление;
<символ>:: = _expression_
Может быть заменен группой элементов с правой стороны; _expression_ и поэтому называется нетерминальным. Другой элемент _expression_ может также содержать другие нетерминальные символы, а также терминальные.
Терминальные символы — это символы, которые не отображаются во всей грамматике, и пример представляет собой строку символов, как в «Три».
Правило в техническом смысле определяет преобразование между нетерминальным набором элементов и нетерминальным и конечным наборами элементов с правой стороны. Это также известно как производственное правило.
ВИДЫ ГРАММАТИК
При синтаксическом анализе в основном существуют два типа грамматики. Это обычные грамматики и контекстно-свободные грамматики. Обычно для определения обычного языка и т. Д. Используется обычная грамматика, но недавний вид грамматики, известный как Parsing Expression Grammar (PEG), может также использоваться для определения контекстно-свободного языка, поскольку он столь же эффективен, как и контекстно-свободные грамматики .Разница между этими двумя типами заключается в обозначениях и способах интерпретации правил.
С точки зрения сложности, обычные языки проще, чем контекстно-свободные, и их можно отличить по _выражению_ обычной грамматики. Это означает, что правая сторона может быть только одной из следующих;
- Одиночное обозначение клеммы
- Пустая строка
- Символ терминала, за которым следует нетерминальный символ
Теоретически это проще, чем на практике, так как это сложно проверить, потому что инструмент может разрешить использование большего количества терминальных символов в одном определении, а затем преобразовать выражение в соответствующую серию выражений, которые все принадлежат одному из вышеперечисленных — упомянутые случаи.
Таким образом, даже если вы напишете выражение, несовместимое с обычным языком, выражение будет преобразовано в правильную форму.
Д. ЛЕКСЕР
Функция лексического анализатора для преобразования последовательности символов, присутствующих в последовательности токенов, поэтому их также называют сканерами или токенизаторами. Лексеры важны при синтаксическом анализе, поскольку они преобразуют ввод в форму, которой синтаксический анализатор лучше управляет на более поздней стадии процесса. Обычно лексеры легче писать, чем парсеры, хотя в некоторых случаях оба одинаково сложны.
Важная функция лексеров — работа с пробелами. Вам нужно будет отбросить пробелы с помощью лексера, потому что его присутствие заставит синтаксический анализатор проверять его между каждым токеном, и это раздражающий процесс. Однако вы не всегда можете отбросить пробелы из-за их релевантности в некоторых случаях, например, в Python, где пробелы используются для идентификации блока кода. Даже в таких случаях лексер используется, чтобы отличить релевантные пробелы от нерелевантных перед синтаксическим анализом.
ГДЕ ЗАКАНЧИВАЕТСЯ ФУНКЦИЯ LEXER И НАЧИНАЕТСЯ ПАРСЕР
В большинстве случаев лексеры используются вместе с синтаксическими анализаторами, поэтому разделение между ними может быть затруднено в большинстве случаев. Это потому, что после синтаксического анализа результат должен быть релевантным для программы. Так что, в конце концов, вы заботитесь только о подходящем вам методе синтаксического анализа, даже если есть много способов синтаксического анализа данных.
ПАРСЕР
В широком смысле синтаксический анализатор данных — это программное обеспечение, которое выполняет весь процесс синтаксического анализа, но, в частности, синтаксический анализатор анализирует токены, создаваемые лексером.Это означает, что синтаксический анализатор выполняет самую важную и сложную часть синтаксического анализа, а лексер помогает в этом процессе.
Вывод синтаксического анализатора обычно представляет собой организованную структуру его кода в виде дерева. Дерево может быть деревом синтаксического анализа или абстрактным синтаксическим деревом, и различия между ними заключаются в том, как они представляют код и промежуточные элементы, определенные анализатором. Дерево выбрано потому, что с ним удобнее работать с кодом на разных уровнях.
Синтаксическая правильность против семантической правильности
Синтаксические анализаторы важны в компиляторах или интерпретаторах, но не ограничиваются ими, поскольку они также могут быть частью другого программного обеспечения. Для проверки синтаксической правильности кода можно использовать синтаксический анализатор, но при проверке семантической достоверности компилятор должен будет использовать выходные данные.
В следующем примере код синтаксически правильный, но неправильный семантически.
интервал x = 10
int сумма = x + y
, поскольку переменная (y) не определена, программа завершится ошибкой, если код будет выполнен.Синтаксический анализатор этого не узнает, поскольку он смотрит только на структуру кода, а не на переменные. С другой стороны, компилятор просматривает дерево синтаксического анализа и отслеживает все переменные, которые определены в первый раз. Он проходит по дереву второй раз, чтобы перепроверить правильность определения используемых переменных.
БЕЗСКАНЕРНЫЙ ПАРАМЕТР
Синтаксический анализатор без сканирования также называется синтаксическим анализатором без лексического анализа, и он выполняет токенизацию и синтаксический анализ за один шаг.Если различие между лексером и синтаксическим анализатором не является необходимым или затруднительным, лучше использовать синтаксический анализатор без сканирования.
ПРОБЛЕМЫ С РАЗБОРОМ РЕАЛЬНЫХ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ
Теоретически синтаксический анализ предназначен для работы с реальными языками программирования, но это проблема из-за некоторых проблем.
Контекстно-зависимые части
Несмотря на то, что инструменты синтаксического анализа предназначены для обработки контекстно-свободных языков, в некоторых случаях языки контекстно-зависимы, и это становится проблемой.Примером контекстно-зависимого элемента являются мягкие ключевые слова (строки элементов, которые могут действовать как ключевые слова в одних местах, а также как идентификаторы в других).
Пробел
Пробелы очень важны в некоторых языках программирования, таких как python, где отступ в операторе указывает, что он принадлежит определенному блоку кода.
Несмотря на то, что пробелы уместны в python, они также не важны в некоторых местах, например, в пробелах между словами или ключевыми словами.Проблема заключается в отступе, и самый простой способ справиться с этим — проверить отступ в начале строки и преобразовать его в соответствующий токен.
Несколько синтаксисов
Другая проблема, связанная с использованием реальных языков программирования при синтаксическом анализе, состоит в том, что язык может содержать участки кода с различным синтаксисом. Наиболее распространенным примером этого является препроцессор C или C ++, который сам по себе является сложным языком и может случайным образом появляться внутри любого кода C.
Что касается аннотаций, с ними легче работать, и они присутствуют во многих языках программирования. Они могут использоваться для обработки кода до того, как он попадет в компилятор, и могут дать команду процессору аннотации преобразовать код определенным образом перед аннотированным. Поскольку они появляются только в определенных местах, с ними легче справиться.
Висячие остальные
Эта проблема часто встречается при синтаксическом анализе данных, особенно тех, которые связаны с оператором if-then-else.Предложение Else является необязательным, поэтому оператор if может означать что угодно. Например;
Если один
Тогда если два
Потом два
Остальное ???
В этом примере не ясно, относится ли else к первому или второму if.
При решении проблемы обычно используется метод, связанный с связыванием else с ближайшим оператором if, и это делает синтаксический анализ контекстно-зависимым.
ДЕРЕВО ПАРАМЕТРОВ И АБСТРАКТНОЕ СИНТАКСИЧЕСКОЕ ДЕРЕВО
Эти два термина тесно связаны и иногда используются как синонимы. Оба они похожи, поскольку оба являются деревьями и имеют корень с узлами, представляющими весь исходный код. У корня есть последующие узлы, которые сами содержат поддеревья, представляющие меньшие части кода до появления отдельных токенов.
Разница между ними заключается в их уровнях абстракции. В дереве синтаксического анализа вы можете найти все токены, которые есть в программе, а также набор промежуточных правил.Но в абстрактном синтаксическом дереве остается только релевантная информация, которая помогает понять код.
Дерево синтаксического анализа представляет код, который ближе к конкретному синтаксису. Он показывает разные уровни детализации процесса синтаксического анализа.
// лексический анализатор
PLUS: «+»
WORD PLUS: «плюс»
НОМЕР: [0-9] +
// парсер
// труба | символ указывает на альтернативу между двумя
Сумма: NUMBER (PLUS | WORD_PLUS) NUMBER
В грамматике сумма может быть определена с помощью символа плюс (+) или использования строки плюс.
При разборе следующего кода;
10 плюс 21
Результирующее дерево синтаксического анализа и абстрактного синтаксиса будет;
Указание на конкретный оператор отсутствует в AST, и это единственная оставшаяся операция, которую еще предстоит выполнить. Конкретный оператор — это промежуточное правило.
ГРАММАТИКИ
Грамматики — это правила, которые используются для описания языка. Грамматика имеет несколько элементов, на которые следует обратить внимание, поскольку грамматика также может использоваться для определения обязанностей или выполнения кодов.
ВОПРОСЫ ГРАММАТИКИ
Отсутствующий жетон
В некоторых типах грамматики определены только несколько лексем. Пример;
НАЗВАНИЕ: [a-zA-Z] +
Приветствие: «ПРИВЕТ» ИМЯ
Токен «HELLO» не определен, и обычно это происходит из-за того, что некоторые инструменты генерируют соответствующие токены для строки, чтобы сэкономить время.
Леворекурсивные правила
Важной особенностью синтаксических анализаторов является поддержка леворекурсивных правил.Это означает, что правило должно начинаться с ссылки на себя. Эта ссылка может быть косвенной и появляться в другом правиле, на которое ссылается первое правило.
Например, в арифметических операциях сложение может быть описано как два выражения, разделенных знаком плюс, но количество добавлений также может быть другим добавлением.
Дополнение: выражение «+»
выражение
Умножение: выражение «+»
выражение
// выражение может быть сложением, умножением или даже числовым выражением: умножение | дополнение | [0-9] +
В приведенном выше примере выражение имеет косвенную ссылку на себя через правила сложения и умножения.
Описание также похоже на множественное сложение, такое как 5 + 4 + 3. Это так, потому что его также можно интерпретировать как выражение (5) (‘+’) выражение (4 + 3. Правило сложения здесь состоит в том, что первое выражение соответствует варианту [0-9] +, а второй также является сложением. 4 + 3 также можно разделить на две его составные части;
Выражение (4) («+»)
Выражение (3)
Правило сложения здесь состоит в том, что оба выражения соответствуют опции [0-9] +
Поскольку леворекурсивные правила нельзя использовать с некоторыми генераторами синтаксического анализатора, другим вариантом будет длинная цепочка выражений, которые заботятся о наиболее важных операциях.
Предикаты
Предикаты — это правила, которые соответствуют только при определенных условиях. Их также называют синтаксическими или семантическими предикатами. Требуемое условие определяется с помощью кода, который поддерживается инструментом, для которого была написана грамматика.
Преимущество предикатов в том, что они допускают некоторую форму контекстно-зависимого синтаксического анализа, который иногда неизбежен при сопоставлении определенных элементов. Например, их можно использовать для проверки того, находится ли последовательность символов, определяющих мягкое ключевое слово, в правильной позиции, где она в конечном итоге будет ключевым словом.Его недостатком является то, что он может замедлить процесс синтаксического анализа, а также сделать грамматику зависимой от языка программирования, на котором выражено условие.
Встроенные действия
Действия по внедрению выделяют коды, которые выполняются после совпадения с правилом. Их недостаток в том, что грамматику труднее читать, потому что правила окружены кодами. Как и предикаты, они также нарушают разделение между языком, описывающим грамматику, и кодом, который управляет результатами синтаксического анализа.
Встроенные действия чаще используются менее сложными генераторами синтаксического анализа, поскольку это единственный способ, с помощью которого коды могут легко выполняться после сопоставления узла. С генераторами парсеров единственный способ — получить доступ к дереву и самостоятельно выполнить правильный код. С более продвинутыми инструментами вы можете выполнять произвольный код, используя шаблон посетителя, когда это необходимо.
Действия
также могут помочь добавить определенные токены или изменить сгенерированное дерево, и это может быть единственным вариантом при работе со сложными языками программирования, такими как C.
ФОРМАТЫ
Что касается грамматики, существует два основных типа форматов; BNF и все его варианты, а также PEG. Многие инструменты также реализуют свои конкретные варианты форматов, в то время как некоторые инструменты полностью используют настраиваемые форматы. Пользовательский формат состоит из трех частей; параметры с настраиваемым кодом, а затем раздел лексера, который заканчивается разделом синтаксического анализатора.
Поскольку форматы BNF являются основой контекстно-свободной грамматики, их также можно определить как формат CFG.
ФОРМА БАКУС-НАУР И ЕЕ ВАРИАНТЫ
BNF — очень успешный формат и основа для создания PEG. Поскольку он очень прост, он в основном используется не в исходной форме, а в виде более мощного варианта. В приведенном ниже примере можно увидеть важность вариантов BNF;
<буква> :: = "a" | "б" | "с" | "д" | "е" | "е" | "г" | "h" | «я» | "j" | "к" | "л" | "м" | "п" | "о" | "р" | "q" | "г" | "с" | "т" | "u" | "v" | "ш" | «х» | "у" | "z"
<цифра> :: = "0" | «1» | «2» | «3» | «4» | «5» | «6» | «7» | «8» | «9»
<символ> :: = <буква> | <цифра>
Символ может быть преобразован в любую из английских букв, и в этом примере допустимы только строчные буквы.Также применимо, в котором может быть любая из альтернативных цифр. Первая проблема заключается в том, что вам придется перечислять альтернативы индивидуально, и вы не можете использовать классы символов, как с регулярными выражениями.
Более сложная проблема заключается в том, что не существует простого способа обозначить необязательные элементы или существующие повторения, поэтому вам придется полагаться на логическую логику и символ (|).
<текст> :: = <символ> | <текст>
<персонаж>
Согласно правилу, может состоять из персонажа или более короткого, предшествующего
Пример ниже — это древовидный синтаксический анализ для слова «собака»
.
Другие ограничения BNF состоят в том, что он затрудняет использование пустых строк или символов, которые используются форматом в грамматике.
Расширенная форма Бэкуса-Наура
EBNF был создан для устранения некоторых из вышеупомянутых ограничений. Это наиболее популярная форма, используемая в инструментах синтаксического анализа, и даже несмотря на то, что инструменты могут отличаться от стандартных обозначений. Нотация EBNF чище и включает больше операторов для работы с необязательными элементами или конкатенацией.
ABNF
ABNF является сокращением от Augmented BNF и является одним из вариантов BNF. Он разработан с целью описания протоколов двунаправленной связи.Использование ABNF может быть столь же продуктивным, как и EBNF, но из-за некоторых его функций его использование ограничено интернет-протоколами.
ABNF также имеет синтаксис, отличный от синтаксиса EBNF. Например, альтернативный оператор представлен косой чертой (/). Он также имеет больше функций, чем EBNF, например, вы можете определить числовые диапазоны, такие как% x30-39, как [0-9]. Он также используется дизайнерами для включения стандартных правил, подобных классам символов, которые может использовать конечный пользователь.
ПЭГ
PEG — это сокращение от Parsing Expression Grammar.Это формат, основанный на старом грамматическом формате, который называется языком синтаксического анализа сверху вниз. Он похож на EBNF и также используется для поддержки широко используемых переменных, таких как диапазоны символов. Это не совсем похоже на EBNF, в отличие от использования формального символа стрелки вместо обычного символа равенства в присвоениях.
PEG против CFG
Теоретически различия между обоими форматами ограничены. PEG очень похож на алгоритм packrat, вот и все. Например, PEG не допускает левой рекурсии, но хотя алгоритм может быть изменен для поддержки левой рекурсии, он устраняет свойство синтаксического анализа линейного времени.Парсеры PEG также обычно являются парсерами без сканирования.
Различие между PEG и CFG и, вероятно, наиболее важное, состоит в том, что при упорядочивании вариантов выбора в PEG он имеет смысл, в отличие от CFG. Если существуют различные допустимые способы синтаксического анализа ввода, это будет неоднозначно в CFG, и будет возвращена ошибка. Например, предоставив разработчику все действительные результаты для сортировки. Однако в PEG двусмысленность устранена, поскольку будет выбран первый применимый вариант, и поэтому PEG не может быть неоднозначным.
Недостатком является то, что вы должны быть особенно осторожны при перечислении возможных альтернатив, поскольку в долгосрочной перспективе вы можете иметь неожиданные последствия.
АЛГОРИТМЫ
Parsing имеет разные алгоритмы, каждый из которых имеет свои сильные и слабые стороны и требует частого обновления.
Parsing имеет две стратегии: синтаксический анализ сверху вниз и снизу вверх. Оба определены с использованием дерева синтаксического анализа, созданного синтаксическим анализатором.
Нисходящий синтаксический анализатор сначала определяет корень дерева синтаксического анализа, а затем переходит к поддеревьям, а затем к листьям дерева. В то время как восходящий синтаксический анализатор начинается с нижней части дерева и продвигается вверх до корня дерева.
Изначально было проще создавать нисходящие парсеры, хотя парсеры снизу вверх оказались более мощными. Но благодаря развитию технологий ситуация стала более сбалансированной.
Вывод связан со стратегиями и указывает порядок появления, в котором нетерминальные элементы в правиле справа применяются для получения нетерминального символа слева.С помощью терминов BNF можно сказать, что это указывает, как элементы в –expression_ используются для получения. Существуют две возможности: крайнее левое происхождение и крайнее правое происхождение. Первый указывает правила, которые применяются слева направо, а второй указывает правила, которые применяются справа налево.
Например, при попытке проанализировать результат символа, как определено в следующей грамматике;
expr_one =. . // вещи
expr_two =.. // вещи
результат = expr_one «оператор» expr_two
, вы можете применить правило для символа expr_one перед expr_two или наоборот. Для крайней левой деривации вы выбираете первый вариант, но вы выбираете второй вариант для крайней правой деривации.
При применении деривации используется сначала в глубину, либо рекурсивно. Это означает, что сначала он применяется к первому выражению, а затем к полученному промежуточному результату.
ОБЩИЕ ЭЛЕМЕНТЫ
Эти общие элементы используются синтаксическими анализаторами, построенными с использованием стратегий «сверху вниз» и «снизу вверх».
Просмотр вперед и возврат
Lookahead используется для обозначения количества элементов, следующих за текущим и учитываемых при принятии решения. Например, синтаксический анализатор может проверить следующий токен, чтобы решить, какое правило применить сейчас. После совпадения с правильным правилом токен расходуется, но следующий остается в очереди.
Обратное отслеживание, с другой стороны, — это метод, специфичный для алгоритма, который находит решения сложных проблем, пробуя частичные решения и останавливаясь на наиболее многообещающем.Если тестируемое решение терпит неудачу, синтаксический анализатор откатывает назад и пробует другое.
Анализаторы диаграмм
Анализаторы диаграмм могут быть как восходящими, так и нисходящими. Они пытаются избежать возврата с помощью динамического программирования. Динамическое программирование — это метод, который используется для разбиения больших проблем на более мелкие для облегчения решения.
Алгоритм Витерби является примером общего алгоритма динамического программирования, который использует анализатор диаграмм.Он направлен на обнаружение наиболее вероятных скрытых состояний через известную последовательность событий.
АВТОМАТЫ
Автоматы — абстрактные машины. Среди синтаксических анализаторов распространен Pushdown Automaton (PDA), а среди лексеров — детерминированная конечная автоматизация (DFA). КПК — более мощная и сложная машина, чем DFA.
Поскольку они используются для определения абстрактных машин, они не связаны напрямую с реальным алгоритмом, а скорее используются для формального описания уровня сложности, с которым алгоритм должен иметь дело.
Поскольку DFA — это конечный автомат, различие, когда дело доходит до лексера, часто остается неопределенным. Это так, потому что у конечных автоматов есть готовые к использованию библиотеки, и поэтому DFA в большинстве случаев реализуется с конечным автоматом.
Лексирование с помощью детерминированного конечного автомата
Конечный автомат имеет много возможных состояний, каждое из которых имеет функцию перехода, и примером конечного автомата является DFA. Функции перехода отвечают за то, как машина переходит из одного состояния в другое в ответ на событие.Если машина используется для лексирования, входные символы подаются по одному, пока он не сможет построить токен.
Они используются, потому что они могут распознавать точный набор обычных языков, и поэтому они так же эффективны, как и обычные языки. Другая причина в том, что это несколько математических методов, которые можно использовать для проверки их свойств и манипулирования ими, и они могут работать с онлайн-алгоритмом.
Онлайн-алгоритм не требует, чтобы все входные данные работали полностью. С помощью лексера токен можно распознать, как только его символы достигнут алгоритма.Вы также можете преобразовать набор регулярных выражений в DFA, и это упрощает ввод правил достаточно простым способом, чтобы у разработчиков не возникло никаких проблем с ними. Оттуда вы можете автоматически преобразовать их в конечный автомат, который сможет эффективно с ними работать.
ВЕРХНИЕ АЛГОРИТМЫ
Это самая популярная стратегия из двух, и она применяется в нескольких алгоритмах.
LL ПАРСЕР
LL обозначает чтение входа слева направо, крайнее левое значение.Эти парсеры основаны на таблицах и не имеют возможности возврата, только просмотр вперед. Из этого видно, что они не зависят от какой-либо таблицы при принятии решений о применяемых правилах синтаксического анализа. Они находят правильные правила для применения;
Анализатор сначала просматривает текущий токен, а также необходимое количество предварительных токенов
И затем он применял разные правила, пока не было найдено правильное совпадение
Парсеры
LL не относятся к конкретному алгоритму, а относятся к классу парсеров.Таким образом, парсер LL может анализировать грамматику LL. Грамматики LL определяются количеством предварительных лексем, необходимых для их анализа, и это число указывается в круглых скобках рядом с LL; LL (k).
Таким образом, можно с уверенностью сказать, что синтаксический анализатор LL (k) использует k токенов просмотра вперед и поэтому он может анализировать грамматику, которая требует для анализа k токенов просмотра вперед. Грамматики LL (k) используются при сравнении различных алгоритмов и служат в качестве измерителя.
Значение грамматик LL
Использование LL-грамматик сверху связано с тем, что парсеры LL немного ограничительны, и оба они широко используются.Грамматики LL не поддерживают леворекурсивные правила, поэтому вы можете преобразовать любую леворекурсивную грамматику, и это ограничение влияет на производительность и мощность.
Потеря продуктивности основана на требовании написания грамматики определенным образом, а это требует много времени. Возможности ограничены также потому, что грамматике, которой может потребоваться 1 токен просмотра вперед, обычно при написании с использованием леворекурсивного инструмента, может потребоваться от 2 до 3 токенов просмотра вперед, когда она записывается нерекурсивным способом.
Потеря производительности может быть уменьшена с помощью алгоритма, преобразующего леворекурсивную грамматику в нерекурсивную. Примером инструмента, который может это сделать, является ANTLR, но если вы создаете свой собственный анализатор данных, вам придется делать это самостоятельно.
LL (1) и LL (*) — это два специальных типа грамматик LL (k), которые в прошлом были единственными практичными типами из-за простоты создания для них синтаксических анализаторов.
РАННИЙ ПАРСЕР
Парсер Эрли — это синтаксический анализатор диаграмм.Этот алгоритм похож на CYK, еще один похожий синтаксический анализатор, но он проще, но хуже по памяти и производительности. Преимущество алгоритма Эрли перед CYK заключается в том, что после сохранения частичных результатов он также имеет функцию прогнозирования правила, которое будет выполнено следующим.
Парсер
Earley в основном разбивает правило на части. Пример показан ниже;
// пример грамматики
ПРИВЕТ: «привет»
НАЗВАНИЕ: [a-zA-Z] +
Приветствие ПРИВЕТ ИМЯ
// Парсер Эрли разбивает приветствие следующим образом
//.ПРИВЕТ ИМЯ
// ПРИВЕТ. НАЗВАНИЕ
// ПРИВЕТ ИМЯ.
Положительным моментом парсера Earley является гарантия того, что он может анализировать все контекстно-свободные языки, тогда как другие алгоритмы, такие как LL или LR, могут анализировать только подмножество языков. Например, у него нет проблем с леворекурсивными грамматиками. В общем смысле синтаксический анализатор Эрли также может обрабатывать недетерминированные и неоднозначные грамматики.
Он может делать все это, но с риском снижения производительности.Однако для обычных грамматик он имеет линейную временную характеристику. Однако хорошо то, что языки, которые анализируются более традиционными алгоритмами, обычно представляют интерес.
Побочным эффектом этого является отсутствие ограничений, поскольку он заставляет разработчика писать грамматику в соответствии с определенным форматом, чтобы синтаксический анализ мог быть более эффективным. Другими словами, построение грамматики LL (1) может оказаться трудным для разработчика, но синтаксический анализатор, с другой стороны, может применить ее лучше.Так что Эрли заставляет вас работать меньше, поскольку синтаксический анализатор делает все остальное.
Проще говоря, вы можете сказать, что Эрли позволяет вам использовать грамматику, которую легче писать, даже если производительность может быть не оптимальной.
Варианты использования парсера Earley
Анализаторы
Earley, как мы видели, просты в использовании, но с точки зрения производительности им не хватает. Эти плюсы и минусы делают алгоритм более подходящим для использования в образовательных учреждениях, где продуктивность важнее скорости.
В первом варианте использования грамматики, которые пишет пользователь, работают правильно, но синтаксический анализатор периодически отправляет случайные ошибки. Ошибки на самом деле связаны с ограничениями, которые существуют в алгоритме, которые не понимают ваши пользователи. Таким образом, получая ошибки, ваши пользователи вынуждены понимать работу вашего парсера и ее ненужность.
Хороший случай ситуации, когда производительность синтаксического анализатора более важна, чем его скорость, — это использование генератора синтаксического анализатора для реализации подсветки синтаксиса в помощь редактору.Редактору требуется поддержка многих языков, и возможность быстрой поддержки может быть важнее, чем быстрое выполнение задачи.
ПАКРАТ (ПЭГ)
Packrat и PEG были изобретены одним и тем же человеком, поэтому их часто связывают друг с другом. Синтаксический анализ Packrat имеет линейное время выполнения, потому что нет обратного отслеживания. Еще одна причина его хорошей эффективности — запоминание. Это процесс сохранения частичных результатов во время синтаксического анализа.Однако недостатком является объем памяти, необходимый для хранения результатов в процессе анализа. Если доступная память не соответствует требуемой, время линейного выполнения алгоритма теряется.
Packrat, как и другие, не поддерживает леворекурсивные правила, потому что PEG всегда должен выбирать первый вариант. Некоторые варианты алгоритма могут поддерживать прямые леворекурсивные правила, но делают это ценой потери линейной сложности.
Если необходимо, packrat может также выполнять бесконечное количество опережающих просмотров, и это влияет на время выполнения.
ПАРСЕР РЕКУРСИВНОГО СПУСКА
Синтаксический анализатор этого типа работает с набором рекурсивных процедур, и в большинстве случаев каждая процедура соответствует правилу грамматики. Итак, вы можете сказать, что структура парсера является зеркалом структуры грамматики.
Прогнозирующий синтаксический анализатор иногда используется как синоним нисходящего синтаксического анализатора, в то время как некоторые другие используют его для обозначения синтаксического анализатора с рекурсивным спуском без возврата. Синтаксический анализатор с рекурсивным спуском с возвратом — прямая противоположность второму значению прогнозирующего синтаксического анализатора.Таким образом, с анализатором рекурсивного спуска с возвратом, всякий раз, когда правило в последовательности не соответствует входным, оно возвращается, чтобы попробовать другое.
Синтаксические анализаторы рекурсивного спуска нелегко анализировать леворекурсивные правила. Это так, потому что алгоритм будет многократно вызывать одну и ту же функцию снова и снова. Чтобы решить эту проблему, вы можете использовать хвостовую рекурсию, а синтаксические анализаторы, которые используют этот метод для решения повторяющихся вызовов функции, называются хвостовыми рекурсивными синтаксическими анализаторами.
Хвостовые рекурсивные парсеры — это рекурсии в конце функции.Однако они используются не сами по себе, а вместе с преобразованиями правил грамматики, и эта комбинация позволяет синтаксическим анализаторам с рекурсивным спуском работать с леворекурсивными правилами.
ПРАТТ ПАРСЕР
Несмотря на то, что синтаксические анализаторы Pratt широко не используются, те, кто знает их ценность, оценят их. Этот алгоритм полагается не на грамматику, а на токены.
Обычно нисходящие синтаксические анализаторы работают лучше, если есть префикс, который различает разные правила. Поскольку это применимо ко всем языкам программирования, это одна из причин, по которой Pratt Parser оказывает незначительное влияние на мир синтаксического анализа данных.
Однако алгоритм Пратта
широко используется в выражениях. Из-за приоритета невозможно понять структуру ввода, просто посмотрев на порядок токенов. Таким образом, алгоритм запрашивает присвоение значения приоритета каждому токену, а также другим функциям, которые определяют действия на основе того, что находится слева и справа от токена.
КОМБИНАТОР PARSER
Это функция высшего порядка, она работает, принимая функцию синтаксического анализатора в качестве входных данных и отправляя новую функцию синтаксического анализатора в качестве выходных данных.Функция синтаксического анализатора — это функция, которая принимает строку и вывод в виде дерева синтаксического анализа.
Несмотря на то, что комбинаторный синтаксический анализатор легко построить, поскольку он является модульным, он менее сложен и медленнее. Таким образом, они в основном используются для простых задач синтаксического анализа или создания прототипов. Пользователь комбинатора синтаксического анализатора полагается на создателя комбинатора, но частично создает синтаксический анализатор вручную.
Комбинаторы парсера
не поддерживают леворекурсивные правила, как некоторые другие алгоритмы, но другие продвинутые формы могут это делать.Некоторые реализации также называют комбинатором монадического синтаксического анализатора, потому что они полагаются на структуру монады (функциональной программы). Монада объединяет функции, а также данные, и это зависит от типа данных. Тип данных определяет различные комбинации значений.
АЛГОРИТМЫ ВНИЗ-ВВЕРХ
Успех восходящего алгоритма связан с семейством многих LR-анализаторов. Однако они относительно непопулярны, потому что, как известно, их сложно построить, хотя парсеры LR более мощные, чем грамматики LL (1).
Алгоритмы сдвига-уменьшения имеют двухступенчатую функцию;
Shift: на этом этапе один токен считывается со входа, и он становится новым узлом
Уменьшить: на этом этапе дерево, полученное в результате сопоставления правильного правила, объединяется с уже существующим прецедентным поддеревом.
Можно сказать, что этап сдвига касается чтения ввода до завершения, а сокращение объединяет поддеревья для построения окончательного дерева парсера.
CYK PARSER
CYK — это сокращение от Cocke-Younger-Kasami.Этот алгоритм имеет главный недостаток, заключающийся в том, что грамматики должны быть выражены в нормальной форме Хомского. Это требование обусловлено тем, что алгоритм зависит от свойств этой формы для разделения ввода при попытке сопоставить все возможности. Теоретически любую контекстно-свободную грамматику можно преобразовать в соответствующую CNF, но это невозможно сделать вручную.
Алгоритм особенно полезен для конкретных задач, например, проблема членства. Он используется для проверки совместимости строки с определенной грамматикой.Алгоритм также может использоваться при обработке естественного языка в поисках лучшего синтаксического анализа среди доступных вариантов.
LR PARSER
LR — это сокращение от чтения слева направо, самого правого вывода. Это примеры восходящих синтаксических анализаторов, которые могут обрабатывать детерминированные контекстно-свободные языки линейно относительно времени, без использования обратного отслеживания, но с опережением.
Традиционно их сравнивают с синтаксическими анализаторами LL, поэтому существует сходство в количестве предварительных лексем, необходимых для синтаксического анализа языка.Синтаксический анализатор LR (k) может анализировать грамматики, требующие анализа k токенов просмотра вперед. Грамматики LR не такие строгие и более мощные, чем соответствующие парсеры LL.
С технической точки зрения, грамматики LR являются надмножеством грамматик LL, и значение этого состоит в том, что требуется только одна грамматика LR (1), поэтому (k) обычно не включается.
Как и парсеры LL, они также основаны на таблицах и нуждаются в двух сложных таблицах. Проще говоря;
Одна из таблиц определяет действие парсера в зависимости от текущего токена, его состояния и предварительных наборов
Вторая таблица сообщает синтаксическому анализатору следующее состояние для перемещения
Парсеры
LR являются мощными и имеют отличную производительность, но требуемые им таблицы трудны для построения и могут вырасти слишком большими для обычных компьютерных языков.Поэтому их можно использовать только через генераторы парсеров.
Обобщенный синтаксический анализатор LR (GLR)
GLR — мощная разновидность парсеров LR. Они важны для анализа недетерминированных и неоднозначных грамматик. Его сила не в таблицах, которые такие же, как у традиционного парсера LR, но могут переходить в разные состояния. На практике, когда существует двусмысленность, он создает новый синтаксический анализатор, который может обрабатывать конкретный случай.
Наихудший случай сложности синтаксического анализатора GLR такой же, как и у анализатора Эрли, даже несмотря на то, что его производительность может быть лучше в лучшем случае детерминированных грамматик.С точки зрения простоты создания, синтаксический анализатор Эрли также проще, чем синтаксический анализатор GLR.
Что такое разбор резюме? Как АТС читает резюме
«Анонимный сотрудник неопределенной компании с неопределенной степенью в чем-то совершенно неидентифицируемом, ищет непризнанную работу в совершенно неизвестном».
Так выглядит ваше резюме даже в самой шикарной Системе отслеживания кандидатов (ATS). Если вы не претендуете на звание шпиона, эта таинственность вряд ли пойдет вам на пользу.В этом посте я объясню, как написать надежное резюме, которое пройдет проверку даже при самых строгих синтаксических анализаторах.
На последнем году учебы в университете я помню, как посетил семинар о том, как написать хорошее резюме. Это было в те времена, когда вы думали, что поступили разумно, купив толстую и дорогую бумагу для печати. Папирус, который я выбрал, пристыдил бы фараона и заклинил бы большинство принтеров. Я помню, как часами пробовал разные шрифты и форматы, что, будучи инженером, не было моей сильной стороной.Тем не менее, все советы, которые я когда-либо получал из книг и семинаров, можно свести к одной короткой фразе: сделайте свое резюме выдающимся.
В те дни это означало, что ваше резюме должно было появиться среди стопок сотен других распечатанных резюме, отягощающих какой-то несчастный несчастный стол и человека, который сидел за ним. К счастью, набор персонала изменился. Резюме теперь хранятся в цифровом виде и все чаще загружаются через программное обеспечение для автоматического анализа резюме, такое как Workable.
Что такое разбор резюме?
Определение «синтаксического анализа резюме», которое мы можем использовать, — это «процесс, с помощью которого технология извлекает данные из резюме.Это означает, что работа парсера заключается в извлечении ключевых компонентов вашего резюме, таких как ваше имя и адрес электронной почты, степень, которую вы имеете, навыки, которые у вас есть, и ваш опыт работы. Это в значительной степени то, что мы создаем с помощью Workable. Мы очень хороши в этом, но достаточно честны, чтобы признать, что это сложно. Возможности языка даже современного синтаксического анализатора резюме еще не достигли человеческого уровня. Другими словами, вы больше не пишете резюме для тех, кто ценит причудливость, фараоновскую бумагу или оригинальность; вы пишете его для парсера, который хочет, чтобы вы следовали стандартам.
Ищете ATS? Узнайте, как Workable может упростить процесс приема на работу. Подпишитесь на 15-дневную бесплатную пробную версию.
Это текст, который имеет значение
Чтобы разобрать резюме, нужно проанализировать текст. Ваше резюме с его мягкими пастельными цветами, причудливыми шрифтами и заголовками WordArt могло бы быть достаточно красивым, чтобы его осветил монах, но есть вероятность, что оно будет выглядеть просто как шум для синтаксического анализатора. Анализ резюме включает извлечение текста, что означает именно то, что написано на банке: извлеките текст и проигнорируйте остальное.Так что, вы могли подумать, может пойти не так? Посмотрите, как имя нашего подающего надежды соискателя, которого я буду называть Джоном Доу, может потерять в переводе:
J O H N D O E
JohnDoe
JJoohnn DDooee
J
o
h
n
D
o
e
Joh nDoe
Вы заметили, что я оставил лишнюю пустую строку вверху? Это не опечатка, ребята, именно так появляется имя Джона Доу после извлечения текста, когда Джон Доу создает в Photoshop собственный баннер со своим именем и контактными данными (также среди тех, кто умер в цифровом виде) и вставляет изображение в свое резюме.Большие заголовки, необычный интервал между символами и выбор шрифта могут привести к созданию или потере пробелов или повторению символов, как показано в следующих нескольких примерах. В таблицах и столбцах слова и, к сожалению, иногда буквы, помещаются в разные строки. Итак, вам нужно следовать некоторым основным правилам, чтобы убедиться, что ваш текст может быть извлечен правильно:
- Разместите свое резюме в текстовом формате, предпочтительно .doc или .docx. В наши дни существует множество текстовых процессоров с открытым исходным кодом, которые понимают этот формат
- Если вы используете формат PDF, убедитесь, что вы экспортируете его из текстового редактора — не сканируйте свое резюме в изображение.
- Старайтесь избегать использования верхних и нижних колонтитулов, поскольку они часто перемежаются с основной частью текста.
- Используйте один стандартный шрифт во всем CV
- Не используйте таблицы и столбцы, поскольку порядок предложений может отличаться от ожидаемого.
- Не используйте WordArt
- Не трогайте интервалы между символами
- Напишите свой документ на вашем собственном компьютере, чтобы ваши метаданные были правильно установлены. Текст там тоже можно найти.
- Укажите свое имя в имени файла вашего резюме
Этот список может показаться чересчур строгим, и, в конце концов, вы действительно хотите представить документ, который хорошо отформатирован, аккуратен и выглядит профессионально.Я бы сказал, что вам не нужно использовать какие-либо из этих функций для достижения своей цели. Я нарисовал здесь несколько мрачную картину, и правда заключается в том, что в некоторых случаях ошибки возникают в тех местах, которые вас не волнуют, а в других сами ошибки можно преодолеть с помощью интеллектуального синтаксического анализатора резюме. Ключевой момент в том, зачем рисковать чем-то настолько важным? И помните, главное — то, что вы на самом деле сделали, имеет наибольшее значение.
Ниндзя роста, JavaScript Rockstars, продуктовые джедаи и продажи Barracudas
Говоря о должностях, в наши дни стало модным доставлять себе удовольствие красивыми названиями.Разработчики JavaScript становятся ниндзя и рок-звездами, онлайн-маркетологи становятся хакерами роста, и, прежде чем вы это узнаете, инженеры-строители в конечном итоге станут преобразователями архитектуры. Я бы посоветовал придерживаться названий, которые проясняют вашу работу, не только для возобновления анализа программного обеспечения, но и в равной степени для вашего потенциального менеджера по найму. Если вы действительно рок-звезда, ваши достижения будут говорить сами за себя.
Не верьте мне на слово, посмотрите, что происходит за кулисами, и судите сами: после извлечения текста следующая задача парсера — искать слова и фразы, которые он ожидает найти в резюме.Искусственный интеллект еще не продвинулся до такой степени, чтобы компьютер мог интерпретировать текст на уровне, близком к человеческому, у него есть удивительный способ запоминания огромного количества вещей: имена, должности, компании, страны и города. только несколько примеров, которые хорошо известны синтаксическому анализатору. Если, конечно, ваша должность не является свежим неологизмом, который больше похож на название фильма о Чаке Норрисе, а не на должность.
Следование стандартам — это не только названия должностей и макет текста.Заголовки разделов также важны, как и следующие стандарты, которые я бы рекомендовал соблюдать:
- Придерживайтесь хронологического формата резюме, а не функционального
- Используйте типичные названия для заголовков разделов, таких как «Образование», «Опыт работы», «Личные данные» и т. Д.
- Используйте формат даты, соответствующий стране, в которой вы подаете заявление, и убедитесь, что вы указали даты полностью (день, месяц и год), чтобы их было легко идентифицировать.
- Используйте только общепринятые и хорошо известные сокращения, такие как CTO, MBA и т. Д.
- Используйте типичные имена для названий должностей и избегайте причудливых украшений
- Используйте проверку орфографии.Из-за опечаток и орфографических ошибок вы будете плохо выглядеть как для синтаксических анализаторов, так и для людей.
Но я креативный!
Я уже слышу крики графических дизайнеров, чье резюме часто служит холстом для их творчества, платформой для самовыражения и уникальности. Если у вас есть законная причина нуждаться в более красивом резюме, я вам советую поддерживать две версии, одна из которых удобна для ATS. Когда вы в следующий раз будете подавать заявление о приеме на работу, узнайте, какой вариант будет более подходящим.
В следующий раз мы воспользуемся этим советом и применим его на практике, так как мы представим несколько шаблонов резюме для ваших кандидатов, которые с честью пройдут через синтаксический анализатор резюме (но я уверяю вас, что они будут монохромными).
Связанные : Как максимально увеличить принятие пользователями вашего ATS
Анализ
Flutter JSON: какой самый быстрый?
Flutter, переносимый фреймворк пользовательского интерфейса Google, использует Dart для
код приложения. Мой вопрос сегодня: каков самый быстрый способ разобрать JSON во Flutter?
Flutter является однопоточным, то есть весь код по умолчанию выполняется в потоке пользовательского интерфейса.Он использует цикл событий
но поддерживает изоляты
(потокоподобные рабочие, которые не разделяют память). В целом, это очень похоже на событие JavaScript.
цикл (и веб-воркеры в браузерах или рабочие потоки в узле).
Поскольку синтаксический анализ JSON выполняется по умолчанию в потоке пользовательского интерфейса, это может вызвать проблемы с производительностью, так как он может
блокировать поток при анализе больших сообщений. Похоже, это хороший вариант использования изолятов!
Однако изоляты оказывают статическое влияние на производительность (для запуска требуется время). Давайте сравним
плюсы и минусы.
Разбор в основном потоке:
- ✓ Нет времени запуска, запускается мгновенно
- ✓ Не нужно копировать сообщение
- ✗ Можно заблокировать UI
- ✗ Одновременно может работать только 1 (однопоточный)
Разбор в изоляте:
- ✓ Не блокирует основной поток
- ✓ Может работать параллельно с несколькими изоляторами
- ✗ Задержка запуска
- ✗ Необходимо скопировать сообщение, чтобы изолировать память
Сегодня мы протестируем несколько методов:
- Только анализ основного потока
- Изолирующий синтаксический анализ с новым изолятором для каждого синтаксического анализа (наивный)
- Анализ изолята с повторным использованием изолята
- Анализ изолята с несколькими повторно используемыми изолятами
Чтобы просмотреть TL; DR, прокрутите вниз до «Заключение», чтобы увидеть результаты и заключительные мысли.
Анализ основного потока
Начнем с самого простого для объяснения нашей методологии тестирования.
Мы будем использовать следующий код для измерения нашего кода:
класс JsonTest расширяет StatefulWidget {
@override
_JsonTestState createState () => _JsonTestState ();
}
class _JsonTestState расширяет State {
вар parsesPerSecond = 0;
@override
void initState () {
super.initState ();
Future.microtask (_run);
}
Будущее _run () async {
var lastFrame = DateTime.сейчас();
var parses = 0;
while (true) {
parseJson ();
последнее время = DateTime.now (). subtract (Продолжительность (секунды: 1));
if (lastFrame.isBefore (время)) {
setState (() {
parsesPerSecond = анализирует;
});
parses = 0;
await Future.microtask (() {});
}
}
}
@override
Сборка виджета (контекст BuildContext) {
return Scaffold (
тело: Центр (
дочерний: текст (parsesPerSecond.toString ()),
),
);
}
}
const jsonToParse = "";
void parseJson () {
} Это обновит пользовательский интерфейс, указав количество синтаксических анализов за последнюю секунду, каждую секунду.Мы будем реализовывать наш синтаксический анализ в функции parseJson .
Мы будем использовать 3 длины JSON (взяты / изменены из примеров JSON):
Мы также будем тестировать на нескольких устройствах в разных режимах:
- OnePlus 8 Pro с 865 (2020), в режиме выпуска
- Pixel 3XL с использованием 855 (2018), в режиме выпуска
- Локальный эмулятор, работающий на 9700K (3 выделенных процессора), в режиме отладки (оценен), потому что мне любопытно
К сожалению, не стоит тратить время на тестирование на iOS.Если есть спрос,
Я мог это настроить.
Используемые версии:
- Флаттер: 1.19.0-1.0.pre
- Дарт: 2.9.0-7.0.dev
Наша первоначальная реализация будет выглядеть так:
void parseJson () {
json.decode (jsonToParse);
} Все результаты в синтаксических анализах в секунду
| Устройство | Короткий | Средний | Длинный |
|---|---|---|---|
| OnePlus 8 Pro (865) | ~ 499 000 | ~ 25 200 | ~ 6 125 |
| Pixel 3XL (855) | ~ 330 000 | ~ 17 000 | ~ 3 285 |
| Настольный компьютер (9700K) | ~ 1 040 000 | ~ 59 900 | ~ 10 400 |
Одним из примечательных моментов было быстрое снижение количества запросов на реальных мобильных устройствах.Всего через 30 секунд работы
некоторые результаты были на 0-30% ниже. Этого не произошло на настольных компьютерах, которые имеют более длительное время разгона.
и лучшее охлаждение.
Я дал всем мобильным устройствам около 3-5 минут между запусками (переключение между ними),
и проводил измерения примерно через 10 секунд работы.
Изолированный синтаксический анализ
Далее мы будем использовать compute :
Future parseJson () async {
ждать вычисления (_parseJson, jsonToParse);
}
_parseJson (текст строки) {
вернуть json.декодировать (текст);
} Для вычислений требуется отдельная функция верхнего уровня. Я также добавил await в цикл.
| Устройство | Короткий | Средний | Длинный |
|---|---|---|---|
| OnePlus 8 Pro (865) | ~ 175 | ~ 160 | ~ 155 |
| Pixel 3XL (855) | ~ 90 | ~ 80 | ~ 70 |
| Настольный компьютер (9700K) | ~ 13 | ~ 13 | ~ 12 |
Где мы видим высокую стоимость использования изолятов, когда большая часть времени уходит на запуск, и
не парсинг.Это делает результат намного ниже и менее зависимым от размера JSON.
Мы также видим значительное снижение производительности внутри эмулятора,
вероятно, связано с созданием новых потоков внутри QEMU. Это сделало размер неважным.
Мы должны помнить, что все это не в основном потоке, поэтому, хотя оно и медленное, оно не повлияет на
производительность вашего пользовательского интерфейса или другого кода в основном потоке.
Повторный синтаксический анализ изолята
Здесь мы запустим изоляцию и повторно используем ее, чтобы избежать высоких затрат на запуск.Единственная плата — это копирование сообщения.
Вот наша реализация, которая немного сложнее, но также будет поддерживать наш следующий эксперимент:
SendPort sendPort;
void isolateCallback (SendPort sendPort) {
финальный receivePort = ReceivePort ();
sendPort.send (получитьПорт.sendPort);
receivePort.listen ((динамическое сообщение) {
final incomingMessage = сообщение как JsonIsolateMessage;
inputMessage.sender.send (json.decode (incomingMessage.text));
});
}
Будущее initParsing () async {
финальный receivePort = ReceivePort ();
жду Изолятор.порождать(
изолироватьCallback,
receivePort.sendPort,
);
sendPort = ждать receivePort.first;
}
Будущее parseJson () async {
if (sendPort == null) {
ждать initParsing ();
}
финальный receivePort = ReceivePort ();
sendPort.send (JsonIsolateMessage (receivePort.sendPort, jsonToParse));
await receivePort.first;
}
class JsonIsolateMessage {
конечный отправитель SendPort;
окончательный текст строки;
JsonIsolateMessage (this.sender, this.text);
} | Устройство | Короткий | Средний | Длинный |
|---|---|---|---|
| OnePlus 8 Pro (865) | ~ 14 500 | ~ 5 100 | ~ 1 220 |
| Pixel 3XL (855) | ~ 5 100 | ~ 2 700 | ~ 640 |
| Настольный компьютер (9700K) | ~ 18 800 | ~ 8 700 | ~ 8 300 |
Здесь мы видим гораздо лучшую производительность.Не так быстро, как без копирования, но лучше, чем без повторного использования.
Здесь реальные устройства показали очень резкое падение в некоторых тестах, причем OnePlus от
От ~ 14k до ~ 5k после 20 секунд в одном примере (но с выдержкой ~ 5.1k и ~ 1.2k в других).
Этого не должно происходить при использовании в реальном мире, поскольку синтаксический анализ не будет непрерывным, обычно исходящим из сети, что было бы нашим узким местом.
Из-за этой модели мы учитываем только короткие (~ 5 с) максимальные всплески для наших приблизительных средних значений.
Время серийной съемки на Pixel было намного меньше (оно снижалось примерно через 3 секунды).
Повторный синтаксический анализ нескольких изолятов
Далее мы инициализируем 8 изолятов и следующий доступный.
Мы будем использовать 8, потому что это количество ядер на 865 и 855 (в структуре 1-3-4).
Реализация (опять же более сложная):
Список availableSendPorts;
финальный sendPortStream = StreamController .broadcast ();
Будущее intialize () async {
финальный receivePort = ReceivePort ();
жду Изолятор.порождать(
изолироватьCallback,
receivePort.sendPort,
);
return await receivePort.first;
}
void isolateCallback (SendPort sendPort) {
финальный receivePort = ReceivePort ();
sendPort.send (получитьПорт.sendPort);
receivePort.listen ((динамическое сообщение) {
final incomingMessage = сообщение как JsonIsolateMessage;
inputMessage.sender.send (json.decode (incomingMessage.text));
});
}
Будущее initParsing () async {
availableSendPorts = await Future.wait ([
intialize (),
intialize (),
intialize (),
intialize (),
intialize (),
intialize (),
intialize (),
intialize (),
]);
}
Будущее parseJson () async {
if (availableSendPorts == null) {
ждать initParsing ();
}
если (availableSendPorts.пустой) {
ждать sendPortStream.stream.first;
}
окончательный sendPort = availableSendPorts.removeAt (0);
финальный receivePort = ReceivePort ();
sendPort.send (JsonIsolateMessage (receivePort.sendPort, jsonToParse));
await receivePort.first;
availableSendPorts.add (sendPort);
sendPortStream.add (ноль);
}
class JsonIsolateMessage {
конечный отправитель SendPort;
окончательный текст строки;
JsonIsolateMessage (this.sender, this.text);
} | Устройство | Короткий | Средний | Длинный |
|---|---|---|---|
| OnePlus 8 Pro (865) | ~ 13 500 | ~ 4 600 | ~ 1 180 |
| Pixel 3XL (855) | ~ 6 800 | ~ 2 700 | ~ 690 |
| Настольный компьютер (9700K) | ~ 13 500 | ~ 5 900 | ~ 1 500 |
Здесь мы видим падение для всех устройств, кроме Pixel.Это странный результат, возможно, из-за
реализация или различия в конструкции ЦП.
Заключение
И снова результат:
Разбор основного потока
| Устройство | Короткий | Средний | Длинный |
|---|---|---|---|
| OnePlus 8 Pro (865) | ~ 499 000 | ~ 25 200 | ~ 6 125 |
| Pixel 3XL (855) | ~ 330 000 | ~ 17 000 | ~ 3 285 |
| Настольный компьютер (9700K) | ~ 1 040 000 | ~ 59 900 | ~ 10 400 |
Анализ изолята
| Устройство | Короткий | Средний | Длинный |
|---|---|---|---|
| OnePlus 8 Pro (865) | ~ 175 | ~ 160 | ~ 155 |
| Pixel 3XL (855) | ~ 90 | ~ 80 | ~ 70 |
| Настольный компьютер (9700K) | ~ 13 | ~ 13 | ~ 12 |
Разбор повторно используемого изолята
| Устройство | Короткий | Средний | Длинный |
|---|---|---|---|
| OnePlus 8 Pro (865) | ~ 14 500 | ~ 5 100 | ~ 1 220 |
| Pixel 3XL (855) | ~ 5 100 | ~ 2 700 | ~ 640 |
| Настольный компьютер (9700K) | ~ 18 800 | ~ 8 700 | ~ 8 300 |
Повторно использованный мультиизолирующий синтаксический анализ
| Устройство | Короткий | Средний | Длинный |
|---|---|---|---|
| OnePlus 8 Pro (865) | ~ 13 500 | ~ 4 600 | ~ 1 180 |
| Pixel 3XL (855) | ~ 6 800 | ~ 2 700 | ~ 690 |
| Настольный компьютер (9700K) | ~ 13 500 | ~ 5 900 | ~ 1 500 |
Заключительные мысли
Вот моя рекомендация:
Если вы анализируете небольшие сообщения JSON, например, используя API, используйте синтаксический анализ основного потока.
- У него самые низкие накладные расходы и самая высокая производительность, и даже с сообщениями средней длины он не повлияет на производительность пользовательского интерфейса.
Если вы постоянно анализируете сообщения JSON средней длины, рассмотрите возможность повторного использования одного изолята.
- Не повлияет на поток пользовательского интерфейса, но будет выполнять синтаксический анализ медленнее.
Если вам нужно проанализировать несколько очень длинных сообщений JSON, используйте изолированный синтаксический анализ (с необязательным повторным использованием).
- Это не повлияет на поток пользовательского интерфейса, и затраты на запуск изоляции будут минимальными.
- Это также самая низкая сложность решений на основе изоляции.
Я бы не рекомендовал повторно использовать несколько изолятов для синтаксического анализа JSON, поскольку это самый медленный метод.
Надеюсь, это было познавательным и полезным для вашей деятельности по синтаксическому анализу JSON на Flutter!
Обновление 2020-05-18 :
Пользователь mraleph прокомментировал Reddit
о фрагментированном декодировании,
что является еще одной альтернативой решению не блокировать основной поток.Это отлично подходит для анализа больших сообщений JSON и создания перерывов для обновления пользовательского интерфейса.
Обо мне
Я Чарльз Крит, автор книги redux_persist ,
flutter_linkify ,
и flutter_super_state
(и многое другое!) библиотеки для Flutter / Dart.
Следуйте за мной в Twitter!
Понимание критерия успеха 4.1.1: Анализ
Понимание критерия успеха 4.1.1: Анализ
На этой странице:
Критерий успеха 4.1.1 Синтаксический анализ (уровень A): в контенте, реализованном с использованием языков разметки, элементы имеют полное начало и конец.
теги, элементы вложены в соответствии со своими спецификациями, элементы не содержат
повторяющиеся атрибуты, и любые идентификаторы уникальны, кроме случаев, когда спецификации позволяют
эти особенности.Начальные и конечные теги, в формировании которых отсутствует критический символ, например
в качестве закрывающей угловой скобки или кавычки с несоответствующим значением атрибута не
полный.
Намерение
Целью данного критерия успеха является обеспечение того, чтобы пользовательские агенты, включая вспомогательные
технологии, могут точно интерпретировать и анализировать контент. Если контент не может быть
проанализированы в структуру данных, тогда разные пользовательские агенты могут представлять ее по-разному
или быть совершенно не в состоянии его разобрать. Некоторые пользовательские агенты используют «методы восстановления» для отображения
плохо закодированный контент.
Поскольку методы восстановления различаются между пользовательскими агентами, авторы не могут предполагать, что контент
будут точно проанализированы в структуре данных или будут правильно отображаться
специализированными пользовательскими агентами, включая вспомогательные технологии, за исключением случаев, когда контент
создается в соответствии с правилами, определенными в формальной грамматике для этой технологии.
В языках разметки ошибки в синтаксисе элементов и атрибутов и
отсутствие должным образом вложенных начальных / конечных тегов приводит к ошибкам, которые
предотвратить надежный синтаксический анализ содержимого пользовательскими агентами.Следовательно, критерий успеха требует, чтобы контент можно было анализировать, используя только
правила формальной грамматики.
Примечание
Понятие «хорошо сформированный» близко к тому, что здесь требуется. Однако точный разбор
требования различаются для разных языков разметки, и большинство языков, не основанных на XML, не
четко определить требования к корректности.Следовательно, необходимо было
быть более явным в критерии успеха, чтобы его можно было применить к разметке.
языков. Поскольку термин «правильно сформированный» определяется только в XML, и (поскольку конец
теги иногда необязательны) действительный HTML не требует хорошо сформированного кода, термин
не используется в этом критерии успеха.
За исключением одного критерия успеха (
1.4.2: Изменить размер текста, в котором конкретно упоминается, что эффект, указанный в критерии успеха, должен
можно достичь, не полагаясь на вспомогательные технологии) авторы могут добиться успеха
критериев с контентом, который предполагает использование вспомогательных технологий (или доступ к функциям
используемых агентов) пользователем, если такие вспомогательные технологии (или функции доступа
в пользовательских агентах) существуют и доступны пользователю.
Преимущества
- Обеспечение того, чтобы веб-страницы имели полные начальные и конечные теги и были вложены в соответствии с
к спецификации
помогает гарантировать, что вспомогательные технологии могут анализировать контент точно и без
сбой.
Методы
Каждый пронумерованный элемент в этом разделе представляет технику или комбинацию техник.
что рабочая группа WCAG считает достаточным для выполнения этого критерия успеха. Тем не мение,
нет необходимости использовать эти конкретные методы. Для получения информации об использовании других
См. «Понимание методов для критериев успеха WCAG», особенно в разделе «Другие методы».
Достаточные методы
G134: проверка веб-страниц
G192: полностью соответствует спецификациям
H88: Использование HTML в соответствии со спецификацией
Обеспечение возможности анализа веб-страниц с помощью одного из следующих методов:
SL33: Использование хорошо сформированного XAML для определения пользовательского интерфейса Silverlight
Отказы
Ниже перечислены распространенные ошибки, которые считаются невыполнением данного критерия успеха.
Рабочей группой WCAG.
Ключевые термины
Парсинг: что это? | RSocks
Парсинг (или парсинг) — это автоматический сбор, обработка и анализ большого количества данных из разных источников. Основная цель синтаксического анализа — получить большие объемы данных за короткое время. Распространение Интернета и повсеместное использование веб-технологий во всех сферах бизнеса привели к появлению в открытом доступе больших объемов данных, анализ которых позволяет делать более точные прогнозы и принимать эффективные решения по развитию. определенных проектов.
Для реализации этого процесса используется специализированное программное обеспечение — парсеры. Другое их название — «поисковые роботы» или «веб-пауки». В зависимости от специфики задачи могут использоваться универсальные парсеры, которые можно найти в Интернете, или разрабатываться их специальные версии для нетривиальных задач.
Подробнее о парсерах и парсинге
Обычно процесс парсинга данных состоит из трех основных этапов: получение доступа и загрузка данных, их обработка для извлечения необходимой информации, сохранение полученной информации в удобном формате для дальнейшего использования.Все эти шаги программно реализованы внутри парсера.
Работа парсеров разбита на четыре этапа.
Первым шагом является сканирование целевых веб-страниц. Парсер отправляет множество HTTP-запросов на нужные страницы, сохраняя полученные ответы. В этом случае список URL-страниц либо задается заранее, либо формируется в процессе сканирования по заданному алгоритму.
Вторая ступень самая важная и технически сложная.Он заключается в реализации алгоритмов анализа и выбора желаемого контента из массива данных, полученных на первом этапе.
Существует несколько подходов к решению проблемы выбора необходимых данных с загружаемых веб-страниц. Они различаются по сложности и используются в зависимости от специфики задачи.
Наиболее распространенные подходы к разработке таких алгоритмов:
- с использованием регулярных выражений
- анализ древовидной структуры HTML-шаблонов
- загрузка страниц с помощью автоматизированного управления браузерами
- Применение технологий машинного обучения
Третий шаг — привести уже извлеченные полезные данные в удобную форму.На этом этапе данные очищаются от ненужных элементов, при необходимости кластеризуются, затем модифицируются и форматируются.
Четвертый шаг — сохранить данные в требуемом формате. В простейшем случае данные можно сохранить в текстовый документ или электронную таблицу. Но по большей части массив сериализуется по определенной модели и сохраняется в базе данных.
Необязательно произносить каждую из этих стадий. В составе парсера один модуль может выполнять сразу несколько функций, таких как форматирование и сохранение данных в желаемом формате.
Объем анализа данных
Говоря о синтаксическом анализе, обычно подразумевается сбор данных с веб-страниц в Интернете. Чаще всего речь идет о получении большого количества данных о товарах, предлагаемых на рынке, их ценах и ассортименте. В этом случае анализ данных в основном включает в себя сбор информации в виде циклических процессов с целью непрерывного мониторинга рынка во времени.
Компаниям нужны очень разные данные. Чаще всего парсеры собирают следующие типы контента:
- Виды товаров и их цены на торговых площадках
- Контент для наполнения сайтов: тексты, картинки, видео и др.
- Персональные данные пользователей: логин, электронная почта, телефон и др.
- Обзоров, комментариев и сообщений в социальных сетях
- Результаты выступлений спортсменов и ставок на спорт
- Доска объявлений услуг
Как видите, синтаксический анализ данных в конечном итоге универсален. Сбор данных о конкурентах, анализ состояния рынка интересующего вас продукта и получение контента для непосредственного использования или обработки — все это может быть полезно для проектов в любой сфере.
Чаще всего парсингом данных пользуются SEO-специалисты, но его масштабы с каждым днем расширяются. Возможно, в ближайшем будущем без парсинга будет невозможно представить развитие бизнеса в большинстве отраслей.
а зачем вам прокси на парсинг?
Видите ли, парсинг данных создает неприятные последствия для сайтов. Если объем собираемых данных огромен и парсеру приходится отправлять большое количество запросов, это создает ненужную нагрузку на веб-серверы, что, безусловно, не приветствуется.Еще один неприятный момент — копирование контента, созданного другим человеком, не всегда справедливо.
Все это приводит к тому, что крупные интернет-ресурсы стараются обезопасить себя от парсинга или хотя бы помешать им делать это в больших объемах. Есть разные способы защитить себя от синтаксического анализа.
Тип защиты | Описание типа защиты |
Установление границ доступа | Скрытие данных о структуре сайта от обычных посетителей.Доступ к полной функциональности предоставляется только авторизованным пользователям и администраторам. |
Черные списки | Создание черных списков, включающих IP-адреса пользователей, подозреваемых в автоматическом сборе данных. |
Запросы на ограничение | Устанавливает минимальный временной интервал между запросами значения.Поскольку парсеры отправляют большое количество запросов в единицу времени, это значительно замедляет их работу. |
Защита от роботов | Такие методы активно используются в Интернете для защиты от любых автоматических нагрузок на серверы, будь то парсинг, массовая публикация или массовое создание аккаунтов в социальных сетях. Самый известный способ защиты — ReCAPTCHA. |
Самый эффективный способ преодолеть этот барьер — использовать прокси-серверы.
Для реализации основных методов безопасности веб-сайту необходимо идентифицировать клиента, отправляющего запрос. Идентификация пользователя осуществляется с использованием различных данных, полученных при настройке HTTP-соединения: IP-адреса, адреса DNS-сервера, отпечатка пальца и других.