Синтаксический разбор простого предложения (Упражнения и тест)
Упражение 1.
Перепишите, расставляя знаки препинания. Выполните синтаксический разбор выделенных предложений.
1) Басни Крылова сокровищница русского практического смысла русского остроумия и юмора русского разговорного языка. 2) На деньги ума не купишь (пословица). 3) Язык есть самая живая самая обильная и прочная связь соединяющая отжившие живущие и будущие поколения в одно великое историческое живое целое (А. К. Ушинский). 4) Мне кажется жизнь удивительной штукой. Как много оттенков у каждого дня! (Гайдар). 5) О чем они говорили? — О политике, искусстве, путешествиях. 6) Нет ничего важней на свете чем сердце отданное детям (Сухомлинский).
Упражение 2.
Перепишите, расставляя знаки препинания. Произведите синтаксический разбор выделенных предложений.
Александр Васильевич Суворов происходил из небогатого дворянского рода. Родился он и вырос в поместье Кончанском бывшая Новгородская губерния. По воспоминаниям родственников мальчик не отличался ни здоровьем ни хорошим сложением. Казалось бы какие тут могли быть мечты о военной службе! Но к досаде родителей ребенок рано пристрастился к военным наукам. Разумеется этому отчасти способствовали увлекательные рассказы о Петре I отца его гостей и просто случайных посетителей.
Родился он и вырос в поместье Кончанском бывшая Новгородская губерния. По воспоминаниям родственников мальчик не отличался ни здоровьем ни хорошим сложением. Казалось бы какие тут могли быть мечты о военной службе! Но к досаде родителей ребенок рано пристрастился к военным наукам. Разумеется этому отчасти способствовали увлекательные рассказы о Петре I отца его гостей и просто случайных посетителей.
Мальчик с жадностью накинулся на жизнеописания великих полководцев прошлого Александра Македонского Ганнибала Юлия Цезаря и в мечтах неоднократно видел себя на бранном поле. В его детской появляются военные предметы и все относящееся к военному делу планы сражений географические карты глобусы. В целях тренировки он приучает себя вставать на рассвете купается до заморозков часами кто из знавших его мог бы этому поверить остается на морозе в легкой одежде.
Ни уговоры ни убеждения ни угрозы родителей ничто не могло отклонить Александра от намеченной цели.4 Настойчиво и прямолинейно он продолжал готовить себя к суровой походной жизни но вначале ни от кого не получал поддержки для осуществления своей мечты. Наоборот все казалось готовы были отговорить его от бессмысленных мечтаний так некоторые из родных называли его планы.
Наоборот все казалось готовы были отговорить его от бессмысленных мечтаний так некоторые из родных называли его планы.
Но мальчик был непоколебим и по-видимому с исключительным упорством добивался своего. Родители наконец уступили. Александр был приписан в рядовые Семеновского полка. С этого момента начинается новая полная трудов и величия жизнь гениального русского полководца.
Упражение 3.
Внимательно прочитайте текст, разделите его на абзацы, определите стиль речи. Затем спишите текст, вставляя пропущенные буквы, знаки препинания, раскрывая скобки и обозначая грамматические основы предложений. Объясните постановку каждого знака препинания. Произведите синтаксический разбор выделенных предложений.
Было тихое летнее утро. С_лнце уже д_вольно высоко ст_яло на чистом небе но поля ещё бл_стели росой. Из (не)давно проснувш_хся д_лин ве_ло душист_й свежестью и в лесу весело расп_вали ранние птич_ки. На в_ршине п_логого холма (с)верху (до)низу покрытого только что зацветш_ю рожью в_днелась (не)болыная дер_венька. К этой дер_веньке шла молодая жен_щина в белом кисейном платье круглой соломе(н, нн)ой шляпе и с зонт_ком в руке. Казачок (из)д_ли след_вал за ней. Она шла (не)т_ропясь и как бы н_сл_ждаясь прогулкой. По высокой зыбкой ржи перел_ваясь то серебристо-зелёной то красн_ватой рябью с мягким шел_стом б_жали дли(н, нн)ые волны в выш_не зв_нели жав_ронки. Молодая жен_щина шла из собстве(н, нн)ого своего села отстоявшего (не)более врсты от дервеньки куда она направляла путь. Звали её Александрой Павловной Ляпиной. Она была вд_ва, бе_детна и довольно б_гата жила (в)месте с своим братом. Он (не)был женат и расп_ряжался её имени_м. (По И. Тургеневу)
К этой дер_веньке шла молодая жен_щина в белом кисейном платье круглой соломе(н, нн)ой шляпе и с зонт_ком в руке. Казачок (из)д_ли след_вал за ней. Она шла (не)т_ропясь и как бы н_сл_ждаясь прогулкой. По высокой зыбкой ржи перел_ваясь то серебристо-зелёной то красн_ватой рябью с мягким шел_стом б_жали дли(н, нн)ые волны в выш_не зв_нели жав_ронки. Молодая жен_щина шла из собстве(н, нн)ого своего села отстоявшего (не)более врсты от дервеньки куда она направляла путь. Звали её Александрой Павловной Ляпиной. Она была вд_ва, бе_детна и довольно б_гата жила (в)месте с своим братом. Он (не)был женат и расп_ряжался её имени_м. (По И. Тургеневу)
Упражение 4.
Спишите, расставляя знаки препинания и объясняя пунктуацию предложений. Выполните синтаксический разбор четвёртого предложения.
1) Все а особенно чиновники некоторое время оставались ошелом-лёнными. (И. Гоголь) 2) В то время а именно год назад я ещё сотрудничал по журналам. (Ф. Достоевский) 3) Для Константина Левина деревня была местом жизни то есть радостей страданий труда. (Л. Толстой) 4) Весь день Анна провела дома то есть у Облонских и не принимала никого. (Л. Толстой) 5) Новый управляющий главное внимание обращал на формальную сторону дела в частности на канцелярские тонкости. (Д. Мамин-Сибиряк)
Достоевский) 3) Для Константина Левина деревня была местом жизни то есть радостей страданий труда. (Л. Толстой) 4) Весь день Анна провела дома то есть у Облонских и не принимала никого. (Л. Толстой) 5) Новый управляющий главное внимание обращал на формальную сторону дела в частности на канцелярские тонкости. (Д. Мамин-Сибиряк)
Упражение 5.
Спишите, вставляя пропущенные буквы и раскрывая скобки. Обозначьте все синтаксические конструкции, осложняющие простое предложение. Объясните постановку знаков препинания в этих предложениях. Проведите синтаксический разбор последнего предложения первого абзаца текста.
Ра(с, сс)к_жу я вам, друзья, о своей (не)забыва_мой встреч_ с уд_вительн_м по кр_соте существом. Прозошло это на (Д, д)_льнем (В, в)остоке во время науч_ной эксп_диц_и. Мы долго шли по извил_стому берегу т_ёжной реч_нки, з_росш_й ивн_ком. Огромные з_валы, каме(н, нн)ые глыбы, как ба(р, рр)икады, прегр_ждали бег реки, заст_вляя её изв рачиватся в тесном русле. Но всё(таки) мы увидели её — н_стоящее чудо пр_роды!
Но всё(таки) мы увидели её — н_стоящее чудо пр_роды!
Разн_цвет_е, радужное соч_тание цв_тов буквально ср_зило (на)(по)вал. Всё, в том числе и (не)обыкнове(н, нн)ой кр_соты хох_лок, вызывало во(с, сс)торг! Этот хохлок с_стоит из дли(н, нн)ых бл_стящих пер_ев, (медн_)красных, (сине)зелёных, (сине)ф_олетовых. С обеих ст_рон ше_ св_сают за_стрё(н, нн)ые (зол_тисто)рыж_е перья, торчащ_е в виде ве_ра. М_ховые крыл_я ра(с, сс)ш_ряют_ся в виде двух тр_угольных парусов, рыж_х (с)верху, (исс_не)фолетовых (с)низу…
Да, перед нами м_нд_ринка, или японка. Это самая кр_сивая р_зно-видность уток. В своём ра(с, сс)п_сном н_ряде она выгл_д_т ш_карно, как китайский м_нд_рин. Верятно, (по)этому её так и назвали. В (не)которых странах, главным обр_зом в Кита_, Коре_ и Япони_, м_нд_ринку разв_дили как домашнюю д_к_ративную птицу. Наше же таёжное название — дупловка — м_нд_ринк_ получила за сп_собность гн_здит_ся в дуплах. (Не)н_йдя подх_дящего дупла, м_нд_ринка может отл_жить яйца и на земле, спрят_вшись для этого под густым кустом (не)(в)д_леке от воды. (В)отличи_ от б_лыш_нства уток, м_ндаринку часто можно вид ть сидящ_й на ветвях дерев_ев или на пр_брежных скал_х. За ярк_сть оп_рения эту утку ещё называют ог ньком.
(В)отличи_ от б_лыш_нства уток, м_ндаринку часто можно вид ть сидящ_й на ветвях дерев_ев или на пр_брежных скал_х. За ярк_сть оп_рения эту утку ещё называют ог ньком.
(По В. Антонову)
Упражение 6.
Спишите тексты, вставляя пропущенные буквы, знаки препинания, раскрывая скобки.
Графически выделите синтаксические конструкции, которые осложняют простое предложение: однородные члены, вводные конструкции, обращения, обособленные и уточняющие члены предложения. Установите, какова роль этих конструкций в данных текстах.
1) Всё и подлунные холмы и тёмно(красные) клев_рные поля и влажные лесные тр_пинки и з_катное пышное небо весь окружающий меня мир к_зался мне прекрасным и (не)было (ни)какого из_яна в нём. Теперь, когда (в)дали от него я вдохнове(н, нн)о ра(с, сс)казывал и восторже(н, нн)о живописал, он к_зался мне ещё пр_краснее ещё сказочнее. Он казался мне пр_красным до сладкого зам_рания в груди. Ра(с, сс)ветные туманы мне вид_лись обязательно розовыми плав_ющие среди водор_слей рыбки представлялись обязательно золотыми с красными перьями роса на травах — то крупный жемчуг то бри(л, лл)ианты.
2) Но больше всего в моих ра(с, сс)казах учас_вовала река. Может быть (по)тому, что стояли летние жаркие дни может быть просто (по) тому, что я больше всего люблю реки. Тихое зеркало омута, которое разб_ваешь (в)дребезги прыгнув вниз головой с травянистого ласкового бережка, хрустальная влага, которая струится (в)доль тела омывая и охл_ждая каждую клеточку кожи рыбий всплеск на вечерней з_ре туманы расползающиеся от реки на пр брежные луга, пря(н, нн)ые зап_хи в зар_слях кр_пивы, таволги и мяты, когда устроишься в укромном уголке…
(В. Солоухин)
Тест по теме «Синтаксический разбор простого предложения»
1. Какое предложение соответствует следующей характеристике: повествовательное, невосклицательное, простое, двусоставное (подлежащее выражено сущ. в именительном падеже, сказуемое — составное именное), распространенное, полное, осложнено обособленным определением?
1) Надвигающиеся с севера-востока грозовые тучи за какие-нибудь полчаса закрыли все небо.
2) Самым вероятным объектом для возникновения жизни считаются вращающиеся вокруг звезды сравнительно небольшие планеты.
3) Несколько мгновений длилось истинное, не показное остолбенение поставленных в тупик хозяев и непритворная, искренняя потерянность сгорающих со стыда несчастных гостей.
4) Факт полного отсутствия денег у всех друзей из нашей компании, зашедших в ресторан пообедать, был удивителен даже для видавших виды официантов.
2. Какое предложение следует считать осложненным?
1) Самая большая равнинная река начинается с незаметных родников.
2) И тогда в невиданную схватку с врагом немедленно включилась вся команда бывшего второго дивизиона.
3) В комнатах с выходящими на улицу окнами по ночам находиться почему-то боялись.
4) Это произошло, кажется, в середине февраля сорок третьего года.
3. Какое предложение не является осложненным?
1) Нагруженная огромными связками фиалок повозка тихо катила вдоль реки.
2) На столе стоял стакан чая и слегка дымил.
3) А он, мятежный, просит бури…
4) Весна наступила в этом году ранняя, дружная и неожиданная.
4. Чем осложнено предложение?
Панорама, остановившая и восхитившая меня, запомнилась надолго.
1) однородными членами
2) обособленным оборотом
3) вводной конструкцией
4) обращением
5. Чем осложнено предложение?
О Русь, Русь, куда же ты мчишься?
1) однородными членами
2) обособленным оборотом
3) вводным словом
4) обращением
6. Чем осложнено предложение?
Вопреки предсказанию моего спутника, погода прояснилась.
1) однородными членами
2) обособленным оборотом
3) вводной конструкцией
4) обращением
7. Чем осложнено предложение?
Этот хищный шум не умолк в ту ночь, а последовал во сне за Францем, окружал его потом и на улице и дома, и во сне и наяву.
1) однородными членами
2) обособленным оборотом
3) вводной конструкцией
4) обращением
8. Чем осложнено предложение?
Письмо было, вероятно, уничтожено.
1) однородными членами
2) обособленным оборотом
3) вводным словом
4) обращением
9. В каком случае дано предложение с обособленным определением?
1) Затем внимание его привлек выставленный в сувенирной лавке несчастный уродливый предмет.
2) Ничего не заметивший Родриг Иванович бешено аплодировал.
3) Справа наспех очерченные дома повернулись к пустырю черными спинами.
4) Увлекаемый по лесной дороге, зажатый, скрюченный, он не мог даже обернуться.
10. В каком случае дано предложение с необособленным обстоятельством?
1) Несмотря на состоявшееся знакомство, человек оставался таким же неприступным.
2) Романтовский, споткнувшись, вышел.
3) Коля стоял не двигаясь.
4) Вчера я пригласил к себе в гости несколько человек, друг с другом незнакомых, но связанных между собой одним и тем же священным делом.
11. В каком случае дана правильная характеристика предложения?
Развернув наудачу несколько писем (в одном из них оказался засохший цветок, перевязанный полинявшей ленточкой), он только плечами пожал и отбросил их в сторону.
1) предложение осложнено обособленным обстоятельством времени и однородными сказуемыми
2) предложение осложнено обособленным обстоятельством образа действия и вставной конструкцией
3) предложение осложнено обособленным обстоятельством времени, вставной конструкцией и однородными сказуемыми
4) предложение осложнено обособленным обстоятельством образа действия, вставной конструкцией и однородными сказуемыми
12. В каком случае дана правильная характеристика предложения?
Что-то на редкость фальшивое чувствовалось буквально в каждой строчке этих статей, несмотря на их грозный и уверенный тон.
1) предложение осложнено обособленными определениями
2) предложение осложнено обособленными определениями и обособленным дополнением
3) предложение осложнено обособленным обстоятельством
4) предложение ничем не осложнено.
13. В каком предложении выделенные слова не обособляются?
1) Лишь я таинственный певец на берег выброшен грозою.
2) Ему внуку прославленного полярника было особенно дорого имя деда.
3) Несмотря на тяжелые погодные условия спасатели уже к вечеру были на месте.
4) Отец и вечером не пришел, поэтому ночь провели не смыкая глаз.
14. В каком варианте ответа правильно указаны и объяснены все запятые?
Он шел (1) постоянно оглядываясь по сторонам (2) и думал встретить кого-нибудь из знакомых (3) но так и дошел до дома в полном одиночестве.
1) 1, 2 — выделяется деепричастный оборот
2) 1, 2 — выделяется деепричастный оборот, 3 — разделяются однородные члены предложения
3) 1, 2 — выделяется причастный оборот
4) 1, 2 — выделяется причастный оборот, 3 — разделяются однородные члены предложения
15. В каком варианте ответа правильно указаны и объяснены все запятые?
В каком варианте ответа правильно указаны и объяснены все запятые?
Бумажный змей (1) взвившийся высоко в небо (2) начал совершать какие-то странные повороты (3) постоянно изменяя направление движения.
1) 1, 2 — выделяется причастный оборот
2) 3 — выделяется деепричастный оборот
3) 1, 2 — выделяется причастный оборот; 3 — выделяется деепричастный оборот
4) 1, 2, 3 — выделяются деепричастные обороты
16. В каком варианте ответа правильно указаны и объяснены все запятые?
Он (1) сломя голову (2) помчался к реке (3) стараясь успеть к отплытию парохода.
1) 1, 2, 3 — выделяются деепричастные обороты
2) 1, 2 — выделяется деепричастный оборот
3) 3 — выделяется деепричастный оборот
4) в предложении нет запятых
Ответы:
Синтаксический разбор простого предложения.
 Русский язык. Тест 2 (5 класс)
Русский язык. Тест 2 (5 класс)
повествовательное, восклицательное, простое, нераспространённое
вопросительное, невосклицательное, простое, распространённое
повествовательное, невосклицательное, простое, распространённое
побудительное, невосклицательное, сложное, распространённое
Урок русского языка в 4 классе по теме: Синтаксический разбор предложения
Технологическая карта урока по русскому языку в 4 классе УМК «Начальная школа 21 век»
Тема | Синтаксический разбор предложения 16. |
Педагогическая цель | Создать условия для систематизации знаний о синтаксическом разборе простого предложения, предложения, осложнённого однородными членами. |
Тип урока | Открытие новых знаний. |
Задачи: | Различать главные и второстепенные члены предложения, графически обозначать их, расставлять знаки препинания, развивать умения проводить синтаксический разбор предложений. |
Планируемые результаты (предметные) | Уметь проводить синтаксический разбор (устный и письменный) простого предложения, предложения, осложнённого однородными членами, конструировать простое предложение по заданной схеме. |
Личностные результаты | Уметь применять приобретённые навыки в практической деятельности; использовать усвоенные приёмы работы для решения учебных задач; осуществлять самоконтроль при выполнении письменных заданий; уметь оценивать собственные знания и результаты; формировать устойчивую мотивацию к обучению в группе. |
Универсальные учебные действия (метапредметные) | Познавательные: ориентируются в учебнике, находят ответы на вопросы в учебном тексте. Регулятивные: определяют цель деятельности на уроке с помощью учителя и самостоятельно; различают способ и результат действия; анализируют собственную работу. Коммуникативные: участвуют в учебном диалоге; слушают, точно реагируют на реплики, поддерживают деловое общение, участвуют в работе в группах, в парах. |
Основное содержание темы, понятия и термины | Простое предложение. Предложение, осложнённое однородными членами. Синтаксический разбор. |
 10.2018
10.2018
Ход урока
Этапы урока | Формы, методы, приёмы | Деятельность учителя | Деятельность осуществляемые действия | учащихся формируемые умения | Формы контроля |
Мотивирование к учебной деятельности (организационный момент) 2. | Фронтальная. Словесный. Слово учителя Фронтальная. Парная. Словесный. | Психологический настрой: Доброе утро, ребята. Сегодня мы работаем в группах, также у вас есть партнер по лицу, партнер по плечу, и у каждого есть свой номер. Улыбнитесь партнеру по лицу, дайте пять партнеру по плечу, возьмитесь за руки всей командой и настройтесь на работу и успех. Садитесь на места. -Отгадайте загадку. Утром мы во двор идём, -Запишите отгадку. — Какие орфограммы в этом слове? — Работа по группам. — Вспомним некоторые орфограммы. У вас на столах задания на листочке, прочитайте и выполните группой – подобрать слова на заданную орфограмму. — Первые номера читают ответы, остальные группы называют орфограмму. Осень славится не только своей красотой, но и богатым урожаем. На доске словарные слова: Номера 1 и 3 «варим» борщ, 2 и 4 – «варим» компот. М…лина, к..пуста, з…мл…ника, к…ртофель, см…родина, м…рковь, ч…снок, св…кла, ябл..ко. -Обменяйтесь тетрадями, проверьте работу друг друга. | Приветствуют учителя. Организуют своё рабочее место. Отвечают на вопросы учителя. Записывают. Выполняют работу в парах. Отвечают на вопросы учителя. | Проявляют эмоциональную отзывчивость на слова учителя. Принимают и сохраняют учебную задачу, соответствующую данному этапу урока. | Правильный выбор слов |
 Словарная работа
Словарная работа А какой урожай вы помогали собирать летом и осенью?
А какой урожай вы помогали собирать летом и осенью?Повеств. |
| На улице идёт дождь. |
| На улице идёт дождь! |
Слушают учителя, выполняют задания, отвечают на проблемный вопрос.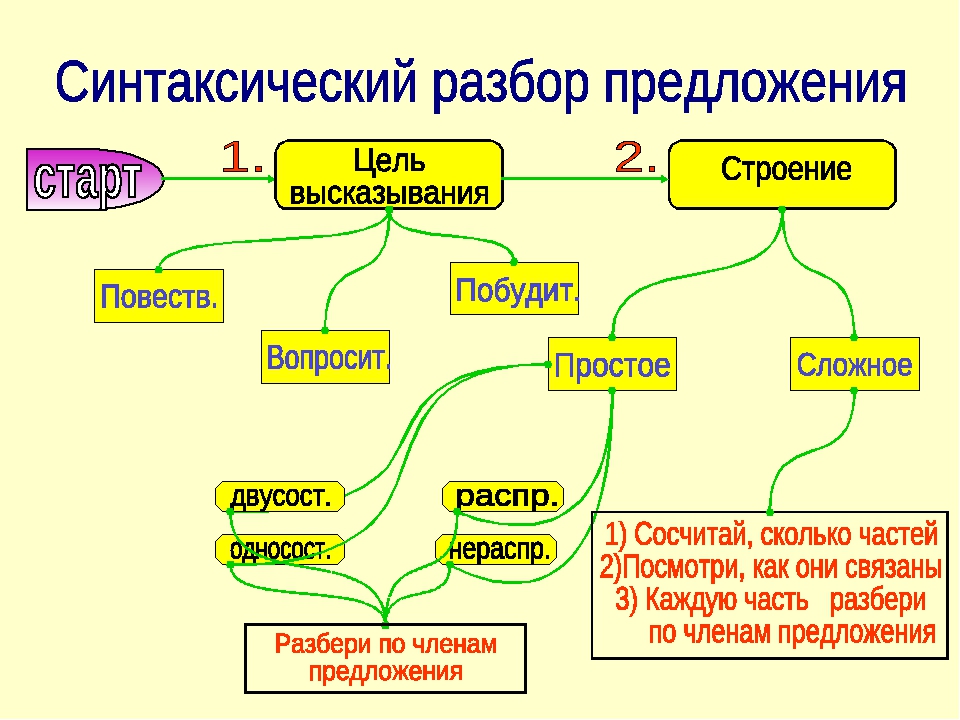
Осуществляют сравнение; полно и точно выражают свои мысли
Упражнение
Физминутка для профилактики нарушений осанки
Фронтальная.
Практический.
Дети идут под музыку по кругу. Музыка останавливается, дети встают парами. Отвечают на вопросы:
— Части слова – это…
— Предлоги с существительным пишутся…
— В русском языке … падежей , перечислите.
Принимают задачу, выполняют задание
Выполнение заданий
2. Работа по учебнику
Индивидуальная.
Практический.
У. 4 с. 58
Выберите одно предложение, проведите его полный синтаксический разбор.
Используют знаково – символические средства для решения учебной задачи.
Упражнение
3. Творческое задание на карточках.
Индивидуальная.
Практический.
Игра “Аукцион”
Задание:
— Добавьте к нераспространённому предложению как можно больше второстепенных членов.
Опадают листья
Осень. жёлтые. медленно, багряные
Осенью опадают листья.
Осенью опадают жёлтые листья.
Осенью опадают жёлтые и багряные листья.
Осенью опадают жёлтые, лиловые и багряные листья.
г) Разбор предложения по алгоритму.
Коллективная работа.
— Запишем последнее предложение на доске, и выполним синтаксический разбор предложения.
Выполняют задания по выбору на кленовых листочках
Принимают учебное задание в соответствии с уровнем своего развития.
Упражнение
6. Рефлексия учебной деятельности на уроке (итог).
Фронтальная.
Практический, групповая.
Шифровка.
Разгадав ключ от этого шифра, мы подведём итог урока.
2-6, 2-3, 2-2, 2-3,2-9,1-5,1-8
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
1 | А | П | И | В | Ц | У | Н | Ы | Ю |
2 | Е | Л | О | К | Р | М | С | З | Д |
— А вам понравился урок?
— Оцените свою работу на уроке. Бросают кубик каждая команда и выпадают вопросы:
Бросают кубик каждая команда и выпадают вопросы:
— Что получилось хорошо?
— Что вызвало затруднения? И др.
— Я хочу поблагодарить вас за работу и закончить урок такими словами:
«Не то, что мните вы, природа:
Не слепок, не бездушный лик –
В ней есть душа, в ней есть свобода,
В ней есть любовь, в ней есть язык.»
Разгадывают ключ к шифровке, читают высказывание.
Принимают участие в работе группами.
Открыто осмысливают и оценивают свою деятельность на уроке.
Работа с таблицей, выполнение упражнения.
Беседа по вопросам.
Саморегуляция.
7. Домашнее задание Упражнение №2 стр.57 (учебник), выучить карточку-помощницу.
Фронтальная.
Словесный.
Объяснение учителя.
Объясняет содержание и способы выполнения домашнего задания. Проверяет соответствующие записи.
Слушают объяснение учителя. Делают соответствующие записи.
Принимают учебное задание в соответствии с уровнем своего развития.
Упражнение
Самоанализ урока русского языка в 4 классе
Тема урока: «Синтаксический разбор предложения»
Тип урока: открытие новых знаний
Методы обучения: проблемно-поисковый, наглядный, словесный, практический
Формы обучения: фронтальная, индивидуальная, парная, групповая
Планируемые результаты (предметные) | Уметь проводить синтаксический разбор (устный и письменный) простого предложения, предложения, осложнённого однородными членами, конструировать простое предложение по заданной схеме. |
Личностные результаты | Уметь применять приобретённые навыки в практической деятельности; использовать усвоенные приёмы работы для решения учебных задач; осуществлять самоконтроль при выполнении письменных заданий; уметь оценивать собственные знания и результаты; формировать устойчивую мотивацию к обучению в группе. |
Универсальные учебные действия (метапредметные) | Познавательные: ориентируются в учебнике, находят ответы на вопросы в учебном тексте. Регулятивные: определяют цель деятельности на уроке с помощью учителя и самостоятельно; различают способ и результат действия; анализируют собственную работу. Коммуникативные: участвуют в учебном диалоге; слушают, точно реагируют на реплики, поддерживают деловое общение, участвуют в работе в группах, в парах. |

Оборудование:
ПК; мультимедийный проектор; мультимедийная презентация к уроку; раздаточный материал.
Структура урока:
Организационный момент, мотивация к учебной деятельности.
Чистописание.
Словарная работа.
Целеполагание и постановка учебной задачи.
Повторение и закрепление знаний и способов действий.
Самостоятельная работа – творческое задание.
Рефлексия учебной деятельности.
Урок соответствует календарно-тематическому планированию.На уроке были учтены возрастные и психологические особенности учащихся. На данном уроке использовались элементы сингапурской методики (работа в группах и физминутка) и элемент перевернутого урока.Планируя урок, старалась, чтобы каждое задание было направлено на развитие предметных и метапредметных умений. Считаю, что на уроке полностью были использованы воспитательные возможности содержания учебного материала. Парная и групповая формы работы способствовали развитию коммуникативных универсальных учебных действий. На данном уроке применялся деятельностный метод обучения, который был реализован в учебной деятельности. На всех этапах урока ученики были вовлечены в активную мыслительную и практическую деятельность, детям надо было не только использовать уже имеющиеся знания, но и найти новый способ выполнения уже известного им действия. Этапы урока были тесно взаимосвязаны между собой, чередовались различные виды деятельности. Умственные действия опирались и подкреплялись практическими.
Умственные действия опирались и подкреплялись практическими.
При постановке вопросов и определении заданий на уроке я учитывала индивидуальные особенности учеников, давала только положительную характеристику результатам их деятельности, что стимулировало детей и повышало их активность на уроке. Учебное время на уроке использовалось эффективно, запланированный объём урока выполнен. Интенсивность урока была оптимальной с учётом физических и психологических особенностей детей.
Владение современными образовательными технологиями помогает мне избежать монотонности процесса обучения, профессионального общения с учениками, что способствует развитию у учащихся любознательности, самостоятельности, активности, творчества. Успешно применяю в практической профессиональной деятельности следующие технологии:
информационно – коммуникативные технологии;
технологию критического мышления;
игровые технологии;
здоровьесберегающие.
Современные педагогические технологии и разнообразные методы обучения позволяют конструировать сотрудничество учащихся на занятиях. Осуществляю выбор методов исходя из индивидуальных психолого- педагогических особенностей учащихся. Это работа в парах, фронтальная работа. Работа в малых группах учит школьников общаться друг с другом, принимать ответственные решения, представлять совместно полученные результаты. У ребят формируется стремление к взаимопомощи, чувство личной ответственности не только за свое личное дело, но и за дело других.
Осуществляю выбор методов исходя из индивидуальных психолого- педагогических особенностей учащихся. Это работа в парах, фронтальная работа. Работа в малых группах учит школьников общаться друг с другом, принимать ответственные решения, представлять совместно полученные результаты. У ребят формируется стремление к взаимопомощи, чувство личной ответственности не только за свое личное дело, но и за дело других.
Тип, форма, цель, задачи урока были адекватны теме урока, цель и задачи формулировались совместно с учащимися, являлись для них личностно значимыми.
Содержание учебного материала соответствует требованиям образовательного стандарта и учебной программы. Теоретическое изложение учебного материала было доступно учащимся, выстроено научно, логично, последовательно.
Уровень самостоятельности учащихся на этапах урока достаточен. УУД формировались на каждом этапе урока. Гигиенические требования соблюдались.
При повторении и усвоении учебного материала использовался субъективный опыт учащихся. Познавательная деятельность носила характер репродуктивный, поисковый. Уровень контроля: фронтальный, индивидуальный, взаимопроверка.
Познавательная деятельность носила характер репродуктивный, поисковый. Уровень контроля: фронтальный, индивидуальный, взаимопроверка.
На уроке выполнили большой объём работы. Были соблюдены все структурные элементы урока. Подведён итог урока и проведена рефлексия собственной деятельности учащихся.
Считаю, что урок прошёл эффективно как для меня, так и для детей, проведенный урок реализовал поставленные задачи.
По какому признаку определяется вид предложения | Вид предложения |
По цели высказывания | Повествовательное Вопросительное Побудительное |
По интонации (по эмоциональной окраске) | Невосклицательное Восклицательное |
По числу грамматических основ | Простое Сложное |
По наличию второстепенных членов | Нераспространённое Распространённое |
Чем осложнено предложение | однородные члены, вводные слова |
Синтаксический разбор предложения
Предложение разбирается по следующей схеме:
1. Подчеркнуть члены предложения.
Подчеркнуть члены предложения.
2.Надписать части речи.
3.Сделать описательный разбор по следующей схеме:
По цели высказывания:
повествовательное, вопросительное, побудительное.
По интонации:
невосклицательное, восклицательное.
По количеству грамматических основ
простое, сложное
По наличию второстепенных членов:
распространённое, нераспространённое.
По наличию осложняющих членов:
осложнённое: однородными членами предложения;
прямой речью; обращением.
Образец синтаксического разбора простого предложения:
пр. прил. сущ. гл. прил. сущ.
В синем небе светит яркое солнышко.4
( Повеств.,невоскл, простое, распростр., не осложнено.)
Главные члены (грамматическая основа) | |
ПОДЛЕЖАЩЕЕ | СКАЗУЕМОЕ |
( — то, о чём или о ком говорится в предложении) | ( — то, что говорится о подлежащем) |
Обозначает предмет. | Обозначает действие. |
Кто? Что? | Что делает? Что сделает? Что будет делать? |
Выражено: сущ., мест., прил. ————————- | Выражено: гл., кр. прил., сущ. ================== |

Второстепенные члены предложения | ||
ДОПОЛНЕНИЕ | ОПРЕДЕЛЕНИЕ | ОБСТОЯТЕЛЬСТВО |
Обозначает предмет. | Обозначает признаки предмета. | Обозначает место, время, способ действия. |
Отвечает на вопросы косвенных падежей: Кого? Чего? Кому? Чему? Что? Кем/ Чем? О ком? О чём? | Отвечает на вопросы Какой? Какая? Какое? Какие? Чей? | Отвечает на вопросы Где? Когда? Куда? Откуда? Почему? Зачем? Как? |
Выражается сущ. чис. — — — — — — — — — | Выражается прил., мест., чис. | Выражается нар., сущ. с пр., мест. с пр. — — — — — — — |
 , прил., мест.,
, прил., мест.,По какому признаку определяется вид предложения | Вид предложения |
По цели высказывания | Повествовательное Вопросительное Побудительное |
По интонации (по эмоциональной окраске) | Невосклицательное Восклицательное |
По числу грамматических основ | Простое Сложное |
По наличию второстепенных членов | Нераспространённое Распространённое |
Чем осложнено предложение | однородные члены, вводные слова |
Адрес публикации: https://www. prodlenka.org/metodicheskie-razrabotki/345541-urok-russkogo-jazyka-v-4-klasse-po-teme-sinta
prodlenka.org/metodicheskie-razrabotki/345541-urok-russkogo-jazyka-v-4-klasse-po-teme-sinta
Открытый урок по русскому языку в 8-м классе по теме «Синтаксический и пунктуационный разбор предложения с однородными членами»
Цели урока:
1) систематизировать и обобщить знания учащихся
об однородных членах, знаках препинания при
однородных членах с обобщающим словом и без него;
2) познакомить с порядком устного и письменного
синтаксического разбора предложения с
однородными членами;
3) научить производить устный и письменный
разбор предложений;
4) развивать пунктуационную зоркость;
5) развивать познавательную активность
учащихся;
6) строить схемы предложений;
7) повысить мотивацию учебной деятельности
через использование ИКТ;
8) воспитывать любовь и уважение к русскому
языку и родному краю;
9) воспитывать аккуратность в работе.
Ход урока
1. Организационный момент.
— Здравствуйте, ребята! Сегодня на уроке мы
обобщим изученный материал по теме «Однородные
члены» и научимся производить синтаксический и
пунктуационный разбор предложений с однородными
членами.
— Откройте тетради, запишите дату и тему урока.
2. Фронтальный опрос.
1) Давайте вспомним, чем может быть осложнено
простое предложение?
(Однородными членами, обособленными членами,
вводными и вставными конструкциями и
обращениями).
2) Какие члены предложения называются
однородными?
3) Все ли члены предложения могут быть
однородными?
4) Как связываются однородные члены в
предложении?
(Перечислительной интонацией и сочинительными
союзам или только интонацией.)
5) Какова пунктуация в предложениях с
однородными членами?
6) Какие слова называются обобщающими? Какие
знаки препинания могут встретиться в
предложениях с обобщающими словами при
однородных членах?
Проверка домашнего задания – упр. 273
(зачитывание предложений из учебников с
обобщающими словами при однородных членах).
Словарная работа:
- иссеченный,
- бессмертный,
- сожженный.
3. Словарная работа.
а) Сделать морфемный разбор.
б) Составить и записать словосочетания.
в) Определить вид связи.
г) На какие орфограммы эти слова. (Удвоенные
согласные)
д) Что общего?
е) А в чем разница?
ж) С одним из словарных слов составить
предложение и сделать синтаксический разбор
(Иссеченный камень, сожженный пункт,
бессмертный полк.)
Учащиеся сами пытаются выстроить цели урока.
1-й ученик работает у доски:
1. Записывает предложение под диктовку.
2. Делает полный синтаксический и
пунктуационный разбор.
3. Объясняет правила постановки знаков
препинания.
2-й ученик составляет схему предложения.
Юные деревца всех пород: ель и сосна, осина
и береза – растут дружно и тесно.
(Повествовательное невосклицательное, простое,
двусоставное, распространенное, полное,
осложнено однородным подлежащим. )
)
Деревца – обобщающее слово. Всех пород –
сочетание местоимения с именем существительным.
Обобщающее слово стоит перед однородными
членами, а после однородных членов предложение
продолжается. В этом случае перед однородными
членами ставится двоеточие, а после них перед
остальной частью ставится тире.
Простор Марсова поля и изящный ажур решетки
Летнего сада гладь Невы в зыбком свете белых
ночей и строгий покой Стрелки Васильевского
острова жесткая, четкая графика Петропавловской
крепости и парадные дворцовые фасады все в этом
городе воспринимается сердцем и навеки остается
в памяти.
Простор Марсова поля и изящный ажур
решетки Летнего сада, гладь Невы в зыбком
свете белых ночей и строгий покой Стрелки
Васильевского острова, жесткая, четкая графика
Петропавловской крепости и парадные дворцовые фасады
– все в этом городе воспринимается
сердцем и навеки остается в памяти.
Выборочный диктант.
1 вариант – однородные определения.
2 вариант – неоднородные определения.
1. На поляне росли большие красные маки.
2. Мы переходили речку через большой каменный
мост.
3. С горы были видны соломенные, черепичные,
деревянные крыши селения.
4. На ней было надето белое длинное платье.
5. На дворе стояло совершенно черная,
непроницаемая ночь.
6. Что-то необыкновенно широкое, размашистое
тянулось по степи.
7. Река уходила в золотые, синие от осени леса.
8. Я люблю клюквенный, малиновый, томатный сок.
9. Летние московские вечера бесконечны.
10. Свежий морской ветер принес прохладу.
Ответы:
1 вариант: 3, 5, 6, 7. 8
2 вариант: 1, 2, 4, 9, 10
Вопросы для закрепления:
1. Какие члены предложения называются
однородными?
2. Какие союзы служат для выражения
однородности?
3. Перечислите соединительные, противительные и
разделительные союзы.
4. Какие союзы называются обобщающими?
3. Рефлексия.
1. Я хорошо запомнил …
2. Мне нужно повторить …
3. У меня хорошо получается …
4. Мне нужно научиться …
Конспект урока на тему «Синтаксический разбор сложного предложения»
Тема: Синтаксический разбор сложного предложения
Цели и задачи:
Познакомить с порядком синтаксического разбора сложного предложения.
Повторить и систематизировать знания по теме «Простое и сложное предложение».
Развитие творческого мышления, речи учащихся.
Методы:
Объяснение
практические: конструирование предложений, разбор.
Формы обучения на уроке как индивидуальные, так и групповые.
Тип урока: объяснение новой темы
Форма урока: Путешествие в зимний лес
Технологии: элементы игры, проекта,
Наглядность: интерактивная доска, сигнальные карточки, эмблема урока- Снеговик, учебник,
План урока
- Оргмомент ( психологический настрой уч-ся)
- Словарно- орфографическая работа
- Актуализация знаний
- Практикум.

- Физминутка
- Игра-практикум
- Работа над проектом по теме +защита проекта ( раздача памятки по теме)
- Практикум

— упр315 стр 90
-творческая работа( собрать словесные пазлы)
-самостоятельная работа+ тестирование( индивид)
- Итог урока+рефлексия
- Выставление оценок, дом. задание
Ход урока
Здравствуйте, ребята. Я рада встрече с вами. О вас знаю, что вы ребята дружные, добрые, активные
Посмотрите друг на друга, поприветствуем улыбкой, пожелали добра и успехов.
А еще, ребята, к вам в гости пришли уважаемые в районе учителя. Подарите им, ребята тепло своей души и сердца. А вы, уважаемые коллеги, хлопками покажите, что вы с ребятами.
Итак, открыли тетради, записали сегодняшнее число : восемнадцатое ноября, классная работа и тему « Синтаксический разбор сложного предложения».
Но прежде, чем приступить к теме урока, проведем небольшой словарный диктант на правописание безударных гласных в корне, проверяемые ударением
Зима, снежок, лесной, тропинка, сосна, деревья, ледяной. Холодный
( проверка- один ученик читает, другие проверяют свою работу, ставя + и оценивают сами.
0- ошибок- «5»
- 2ошибки- «4»
3- «3»
Какие ассоциации возникают при чтении этих слов? ( зима)
Верно. Лексической темой урока будет « Зима». Мы все отправимся в зимний лес, а проводником будет Снеговик
Слайд1(лес зимой)
Первый привал « Вспоминайка»
-что такое предложение?
-какие предложения бывают по цели высказывания? (повеств, побуд, вопрос,)
-Какие предложения знаете по интонации?( воскл, невоскл)
Как различить простое предложение от сложного?(по числу грамматических основ)
-какие предложения бывают по числу главных членов? (односост, двусост)
Разбор простого предложения: На землю выпал первый снег. (повеств, невоскл, прост, двусост, распр, неосложн.)
(повеств, невоскл, прост, двусост, распр, неосложн.)
Следующий привал « Распредели»
Распределить простые и сложные предложения:
По лугам дул ветер. Зима пришла, звери попрятались по норам.
Солнце светит неярко. Лиса вышла на охоту, а белочка наблюдает за ней.
-физминутка
Зайка серенький сидит
И ушами шевелит. (поднять ладони над головой и махать, изображая ушки)
Вот так, вот так
Он ушами шевелит!
Зайке холодно сидеть,
Надо лапочки погреть. (потереть себя за предплечья)
Вот так, вот так
Надо лапочки погреть!
Зайке холодно стоять,
Надо зайке поскакать. (прыжки на месте)
Вот так, вот так
Надо зайке поскакать.
Зайку волк испугал!
Зайка тут же убежал. (сесть на место за парту)
Игра- практикум
Ребята, приготовьте сигнальные карточки. Зеленый цвет означает «да», красный – «нет»
-верите ли вы, что сложное предложение имеет одну грамматическую основу?( нет. Красный цвет)
Красный цвет)
— верите ли вы, что части сложного предложения могут быть связаны союзами?(да)
-верите ли вы, что между частями сложного предложения не бывает союзов? (нет)
-верите ли вы, что части сложного предложения разделяются запятой? (да)
Привал « Проект»
Создать проект « Сложное предложение».как вы понимаете сложное предложение. Проект может быть в виде кластера, опорной схемы.( работа в группе)
— Защита проекта
Вывод: Сложное предложение состоит из двух и более простых предложений, связанных между собой по смыслу и интонацией
Практическая работа. Откройте, пожалуйста, учебник на стр.90 выполним упражнение 315( комментированное письмо)
Дед увидел пожар и бросился к дому. ( прост)
Дед догадался, что огонь приближается к лесу.( Сложн)
Ветер гудел и с шумом гнал волны.( прост.)
Ветер гудел, а волны с шумом бились о берег. ( сложн)
-Разбор последнего предложения.
Ветер гудел, а волны с шумом бились о берег(повеств, невоскл, сложн, союзн,,
— Собрать словесные пазлы по группам
Самостоятельная работа:
А)Вставить пропущенные буквы
Пришла з.ма, и вып.л сн.жок.Ударил м.роз, ст.кло в комнате покрылось л.дяными узорами. Подул сильный ветер, и сн.жинки закружились в танце.
Произвести синтаксический разбор одного сложного предложения
Б) Тест
Итак, пришла пора подвести итоги. На уроке вы много работали. Подытожим нашу работу. Какая была тема урока?
Какая цель была поставлена перед нами?
Как оцениваете свою работу? Расскажите по схеме
Сегодня на узнал, открыл для себя….
Я научился, смог……
Уроке могу похвалить себя и своих
одноклассников за……
Д/задание Разбор 3 сложных предложений
Выставление оценок
Поблагодарить ребят.
Просмотр содержимого документа
«Конспект урока на тему «Синтаксический разбор сложного предложения»»
Тема: Синтаксический разбор сложного предложения
Цели и задачи:
Познакомить с порядком синтаксического разбора сложного предложения.
Повторить и систематизировать знания по теме «Простое и сложное предложение».
Развитие творческого мышления, речи учащихся.
Методы:
Объяснение
практические: конструирование предложений, разбор.
Формы обучения на уроке как индивидуальные, так и групповые.
Тип урока: объяснение новой темы
Форма урока: Путешествие в зимний лес
Технологии: элементы игры, проекта,
Наглядность: интерактивная доска, сигнальные карточки, эмблема урока- Снеговик, учебник,
План урока
Оргмомент ( психологический настрой уч-ся)
Словарно- орфографическая работа
Актуализация знаний
Практикум.
Физминутка
Игра-практикум
Работа над проектом по теме +защита проекта ( раздача памятки по теме)
Практикум

— упр315 стр 90
-творческая работа( собрать словесные пазлы)
-самостоятельная работа+ тестирование( индивид)
Итог урока+рефлексия
Выставление оценок, дом. задание
Ход урока
Здравствуйте, ребята. Я рада встрече с вами. О вас знаю, что вы ребята дружные, добрые, активные
Посмотрите друг на друга, поприветствуем улыбкой, пожелали добра и успехов.
А еще , ребята, к вам в гости пришли уважаемые в районе учителя. Подарите им , ребята тепло своей души и сердца. А вы, уважаемые коллеги, хлопками покажите, что вы с ребятами.
Итак, открыли тетради, записали сегодняшнее число : восемнадцатое ноября, классная работа и тему « Синтаксический разбор сложного предложения».
Но прежде, чем приступить к теме урока, проведем небольшой словарный диктант на правописание безударных гласных в корне, проверяемые ударением
Зима, снежок, лесной, тропинка, сосна, деревья, ледяной. Холодный
( проверка- один ученик читает, другие проверяют свою работу, ставя + и оценивают сами.
0- ошибок- «5»
2ошибки- «4»
3- «3»
Какие ассоциации возникают при чтении этих слов? ( зима)
Верно. Лексической темой урока будет « Зима». Мы все отправимся в зимний лес, а проводником будет Снеговик
Слайд1(лес зимой)
Первый привал « Вспоминайка»
-что такое предложение?
-какие предложения бывают по цели высказывания? (повеств, побуд, вопрос,)
-Какие предложения знаете по интонации?( воскл, невоскл)
Как различить простое предложение от сложного?(по числу грамматических основ)
-какие предложения бывают по числу главных членов? (односост, двусост)
Разбор простого предложения: На землю выпал первый снег. (повеств, невоскл, прост, двусост, распр, неосложн.)
(повеств, невоскл, прост, двусост, распр, неосложн.)
Следующий привал « Распредели»
Распределить простые и сложные предложения:
По лугам дул ветер. Зима пришла, звери попрятались по норам.
Солнце светит неярко. Лиса вышла на охоту, а белочка наблюдает за ней.
-физминутка
Зайка серенький сидит
И ушами шевелит. (поднять ладони над головой и махать, изображая ушки)
Вот так, вот так
Он ушами шевелит!
Зайке холодно сидеть,
Надо лапочки погреть. (потереть себя за предплечья)
Вот так, вот так
Надо лапочки погреть!
Зайке холодно стоять,
Надо зайке поскакать. (прыжки на месте)
Вот так, вот так
Надо зайке поскакать.
Зайку волк испугал!
Зайка тут же убежал. (сесть на место за парту)
Игра- практикум
Ребята, приготовьте сигнальные карточки. Зеленый цвет означает «да», красный – «нет»
-верите ли вы, что сложное предложение имеет одну грамматическую основу?( нет. Красный цвет)
Красный цвет)
— верите ли вы, что части сложного предложения могут быть связаны союзами?(да)
-верите ли вы, что между частями сложного предложения не бывает союзов? (нет)
-верите ли вы, что части сложного предложения разделяются запятой? (да)
Привал « Проект»
Создать проект « Сложное предложение».как вы понимаете сложное предложение. Проект может быть в виде кластера, опорной схемы.( работа в группе)
— Защита проекта
Вывод: Сложное предложение состоит из двух и более простых предложений, связанных между собой по смыслу и интонацией
Практическая работа. Откройте, пожалуйста, учебник на стр.90 выполним упражнение 315( комментированное письмо)
Дед увидел пожар и бросился к дому. ( прост)
Дед догадался, что огонь приближается к лесу.( Сложн)
Ветер гудел и с шумом гнал волны.( прост.)
Ветер гудел, а волны с шумом бились о берег. ( сложн)
-Разбор последнего предложения.
Ветер гудел, а волны с шумом бились о берег(повеств, невоскл, сложн, союзн,,
— Собрать словесные пазлы по группам
Самостоятельная работа:
А)Вставить пропущенные буквы
Пришла з. ма, и вып.л сн.жок.Ударил м.роз, ст.кло в комнате покрылось л.дяными узорами. Подул сильный ветер, и сн.жинки закружились в танце.
ма, и вып.л сн.жок.Ударил м.роз, ст.кло в комнате покрылось л.дяными узорами. Подул сильный ветер, и сн.жинки закружились в танце.
Произвести синтаксический разбор одного сложного предложения
Б) Тест
Итак, пришла пора подвести итоги. На уроке вы много работали. Подытожим нашу работу. Какая была тема урока?
Какая цель была поставлена перед нами?
Как оцениваете свою работу? Расскажите по схеме
Сегодня на узнал, открыл для себя…..
Я научился, смог……
Уроке могу похвалить себя и своих
одноклассников за……
Д/задание Разбор 3 сложных предложений
Выставление оценок
Поблагодарить ребят.
100 ballov.kz образовательный портал для подготовки к ЕНТ и КТА
В 2021 году казахстанские школьники будут сдавать по-новому Единое национальное тестирование. Помимо того, что главный школьный экзамен будет проходить электронно, выпускникам предоставят возможность испытать свою удачу дважды. Корреспондент zakon.kz побеседовал с вице-министром образования и науки Мирасом Дауленовым и узнал, к чему готовиться будущим абитуриентам.
Корреспондент zakon.kz побеседовал с вице-министром образования и науки Мирасом Дауленовым и узнал, к чему готовиться будущим абитуриентам.
— О переводе ЕНТ на электронный формат говорилось не раз. И вот, с 2021 года тестирование начнут проводить по-новому. Мирас Мухтарович, расскажите, как это будет?
— По содержанию все остается по-прежнему, но меняется формат. Если раньше школьник садился за парту и ему выдавали бумажный вариант книжки и лист ответа, то теперь тест будут сдавать за компьютером в электронном формате. У каждого выпускника будет свое место, огороженное оргстеклом.
Зарегистрироваться можно будет электронно на сайте Национального центра тестирования. Но, удобство в том, что школьник сам сможет выбрать дату, время и место сдачи тестирования.
Кроме того, в этом году ЕНТ для претендующих на грант будет длиться три месяца, и в течение 100 дней сдать его можно будет два раза.
— Расскажите поподробнее?
— В марте пройдет тестирование для желающих поступить на платной основе, а для претендующих на грант мы ввели новые правила. Школьник, чтобы поступить на грант, по желанию может сдать ЕНТ два раза в апреле, мае или в июне, а наилучший результат отправить на конкурс. Но есть ограничение — два раза в один день сдавать тест нельзя. К примеру, если ты сдал ЕНТ в апреле, то потом повторно можно пересдать его через несколько дней или в мае, июне. Мы рекомендуем все-таки брать небольшой перерыв, чтобы еще лучше подготовиться. Но в любом случае это выбор школьника.
Школьник, чтобы поступить на грант, по желанию может сдать ЕНТ два раза в апреле, мае или в июне, а наилучший результат отправить на конкурс. Но есть ограничение — два раза в один день сдавать тест нельзя. К примеру, если ты сдал ЕНТ в апреле, то потом повторно можно пересдать его через несколько дней или в мае, июне. Мы рекомендуем все-таки брать небольшой перерыв, чтобы еще лучше подготовиться. Но в любом случае это выбор школьника.
— Система оценивания останется прежней?
— Количество предметов остается прежним — три обязательных предмета и два на выбор. Если в бумажном формате закрашенный вариант ответа уже нельзя было исправить, то в электронном формате школьник сможет вернуться к вопросу и поменять ответ, но до того, как завершил тест.
Самое главное — результаты теста можно будет получить сразу же после нажатия кнопки «завершить тестирование». Раньше уходило очень много времени на проверку ответов, дети и родители переживали, ждали вечера, чтобы узнать результат.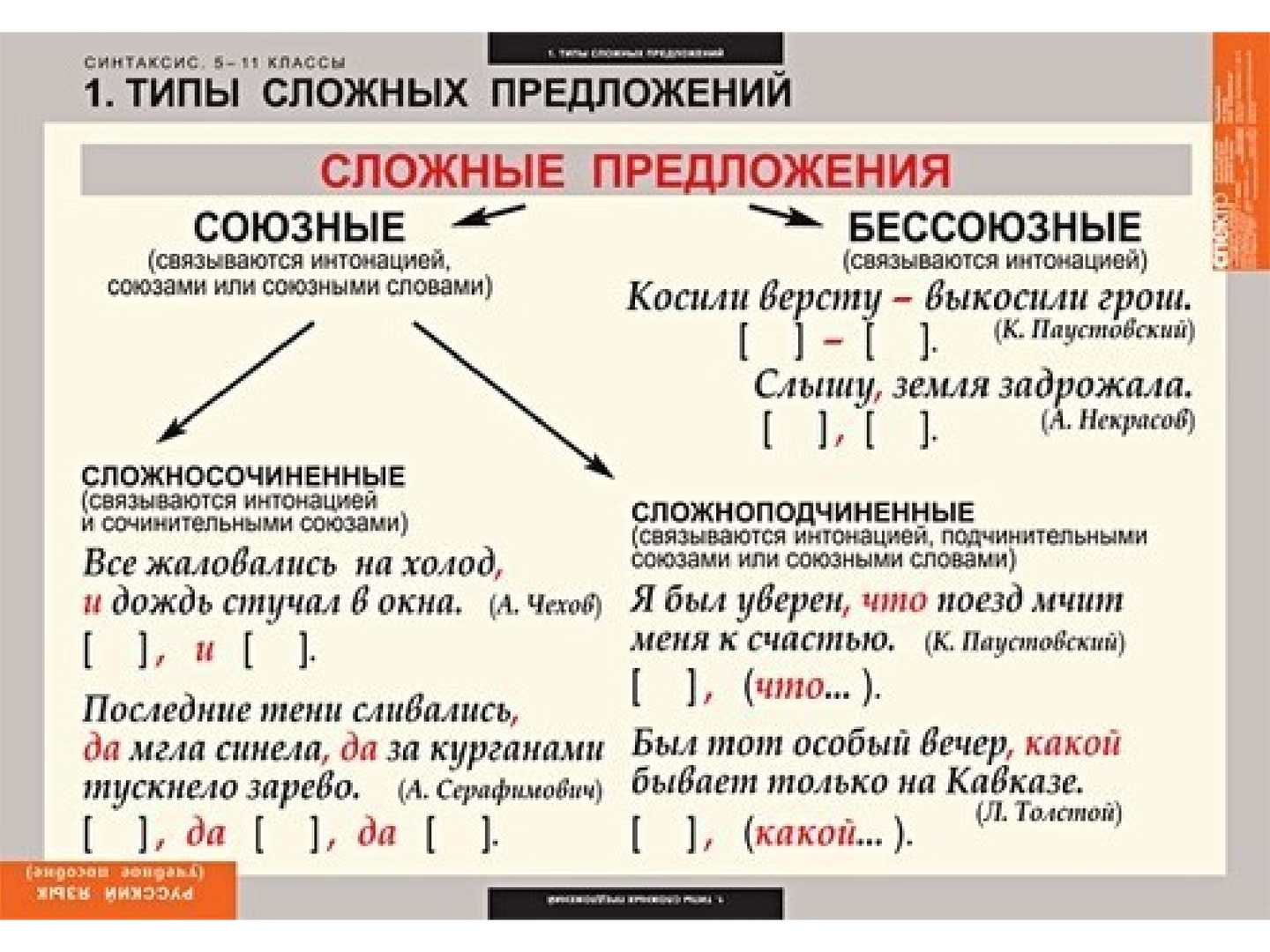 Сейчас мы все автоматизировали и набранное количество баллов будет выведено на экран сразу же после завершения тестирования.
Сейчас мы все автоматизировали и набранное количество баллов будет выведено на экран сразу же после завершения тестирования.
Максимальное количество баллов остается прежним — 140.
— А апелляция?
— Если сдающий не будет согласен с какими-то вопросами, посчитает их некорректными, то он сразу же на месте сможет подать заявку на апелляцию. Не нужно будет ждать следующего дня, идти в центр тестирования, вуз или школу, все это будет электронно.
— С учетом того, что школьникам не придется вручную закрашивать листы ответов, будет ли изменено время сдачи тестирования?
— Мы решили оставить прежнее время — 240 минут. Но теперь, как вы отметили, школьникам не нужно будет тратить час на то, чтобы правильно закрасить лист ответов, они спокойно смогут использовать это время на решение задач.
— Не секрет, что в некоторых селах и отдаленных населенных пунктах не хватает компьютеров. Как сельские школьники будут сдавать ЕНТ по новому формату?
— Задача в том, чтобы правильно выбрать время и дату тестирования. Центры тестирования есть во всех регионах, в Нур-Султане, Алматы и Шымкенте их несколько. Школьники, проживающие в отдаленных населенных пунктах, как и раньше смогут приехать в город, где есть эти центры, и сдать тестирование.
Центры тестирования есть во всех регионах, в Нур-Султане, Алматы и Шымкенте их несколько. Школьники, проживающие в отдаленных населенных пунктах, как и раньше смогут приехать в город, где есть эти центры, и сдать тестирование.
— На сколько процентов будет обновлена база вопросов?
— База вопросов ежегодно обновляется как минимум на 30%. В этом году мы добавили контекстные задания, то что школьники всегда просили. Мы уделили большое внимание истории Казахстана и всемирной истории — исключили практически все даты. Для нас главное не зазубривание дат, а понимание значения исторических событий. Но по каждому предмету будут контекстные вопросы.
— По вашему мнению система справится с возможными хакерскими атаками, взломами?
— Информационная безопасность — это первостепенный и приоритетный вопрос. Центральный аппарат всей системы находится в Нур-Султане. Связь с региональными центрами сдачи ЕНТ проводится по закрытому VPN-каналу. Коды правильных ответов только в Национальном центре тестирования.
Кроме того, дополнительно через ГТС КНБ (Государственная техническая служба) все тесты проходят проверку на предмет возможного вмешательства. Здесь все не просто, это специальные защищенные каналы связи.
— А что с санитарными требованиями? Нужно ли будет школьникам сдавать ПЦР-тест перед ЕНТ?
— ПЦР-тест сдавать не нужно будет. Требование по маскам будет. При необходимости Центр национального тестирования будет выдавать маски школьникам во время сдачи ЕНТ. И, конечно же, будем измерять температуру. Социальная дистанция будет соблюдаться в каждой аудитории.
— Сколько человек будет сидеть в одной аудитории?
— Участники ЕНТ не за семь дней будут сдавать тестирование, как это было раньше, а в течение трех месяцев. Поэтому по заполняемости аудитории вопросов не будет.
— Будут ли ужесточены требования по дисциплине, запрещенным предметам?
— Мы уделяем большое внимание академической честности. На входе в центры тестирования, как и в предыдущие годы, будут стоять металлоискатели. Перечень запрещенных предметов остается прежним — телефоны, шпаргалки и прочее. Но, помимо фронтальной камеры, которая будет транслировать происходящее в аудитории, над каждым столом будет установлена еще одна камера. Она же будет использоваться в качестве идентификации школьника — как Face ID. Сел, зарегистрировался и приступил к заданиям. Мы применеям систему прокторинга.
Перечень запрещенных предметов остается прежним — телефоны, шпаргалки и прочее. Но, помимо фронтальной камеры, которая будет транслировать происходящее в аудитории, над каждым столом будет установлена еще одна камера. Она же будет использоваться в качестве идентификации школьника — как Face ID. Сел, зарегистрировался и приступил к заданиям. Мы применеям систему прокторинга.
Понятно, что каждое движение абитуриента нам будет видно. Если во время сдачи ЕНТ обнаружим, что сдающий использовал телефон или шпаргалку, то тестирование автоматически будет прекращено, система отключится.
— А наблюдатели будут присутствовать во время сдачи тестирования?
— Когда в бумажном формате проводили ЕНТ, мы привлекали очень много дежурных. В одной аудитории было по 3-4 человека. При электронной сдаче такого не будет, максимум один наблюдатель, потому что все будет видно по камерам.
— По вашим наблюдениям школьники стали меньше использовать запрещенные предметы, к примеру, пользоваться телефонами?
— Практика показывает, что школьники стали ответственнее относиться к ЕНТ. Если в 2019 году на 120 тыс. школьников мы изъяли 120 тыс. запрещенных предметов, по сути у каждого сдающего был телефон. То в прошлом году мы на 120 тыс. школьников обнаружили всего 2,5 тыс. телефонов, и у всех были аннулированы результаты.
Если в 2019 году на 120 тыс. школьников мы изъяли 120 тыс. запрещенных предметов, по сути у каждого сдающего был телефон. То в прошлом году мы на 120 тыс. школьников обнаружили всего 2,5 тыс. телефонов, и у всех были аннулированы результаты.
Напомню, что в 2020 году мы также начали использовать систему искусственного интеллекта. Это анализ видеозаписей, который проводится после тестирования. Так, в прошлом году 100 абитуриентов лишились грантов за то, что во время сдачи ЕНТ использовали запрещенные предметы.
— Сколько средств выделено на проведение ЕНТ в этом году?
Если раньше на ЕНТ требовалось 1,5 млрд тенге из-за распечатки книжек и листов ответов, то сейчас расходы значительно сокращены за счет перехода на электронный формат. Они будут, но несущественные.
— Все-таки почему именно в 2021 году было принято решение проводить ЕНТ в электронном формате. Это как-то связано с пандемией?
— Это не связано с пандемией. Просто нужно переходить на качественно новый уровень. Мы апробировали данный формат на педагогах школ, вы знаете, что они сдают квалификационный тест, на магистрантах, так почему бы не использовать этот же формат при сдаче ЕНТ. Тем более, что это удобно, и для школьников теперь будет много плюсов.
Мы апробировали данный формат на педагогах школ, вы знаете, что они сдают квалификационный тест, на магистрантах, так почему бы не использовать этот же формат при сдаче ЕНТ. Тем более, что это удобно, и для школьников теперь будет много плюсов.
Правило синтаксический разбор слова
Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Справочная информация
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое – это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое – это глагол, т.е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение – второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта – было бы скучно, уж поверьте. Итак, обстоятельство – это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?». А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной – важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» — как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Слово «дремучий» — как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая – придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой – как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т.е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется – оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола – действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость. Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны. Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:

| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |
Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложения
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
Сказуемое
- Отмечаем, чем является сказуемое — простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое — какой формой глагола;
- составное глагольное — из чего оно состоит;
- составное именное — какая употреблена связка, чем выражается именная часть.
В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Единицы синтаксиса
Синтаксис изучает связь слов внутри словосочетаний или предложений. Таким образом, единицами синтаксиса являются словосочетания и предложения – простые или сложные. В этой статье мы будем говорить о том, как сделать синтаксический разбор предложения, а не словосочетания, хотя нередко в школе просят сделать и его.
Зачем нужен синтаксический разбор предложения
Синтаксический разбор предложения предполагает подробное рассмотрение его структуры. Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Члены предложения
Среди членов предложения всегда сначала выделяют главные: подлежащее и сказуемое. Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Грамматическая основа может состоять как из двух главных членов, так и включать в себя только один из них: или только подлежащее, или только сказуемое. Во втором случае мы говорим, что предложение односоставное. Если же присутствуют оба главных члена – двусоставное.
Если, кроме грамматической основы, слов в предложении нет, оно называется нераспространённым. В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.
если в предложении есть слова, которые членами предложения не являются (например, обращение), оно все равно считается нераспространенным.
Выполняя разбор, необходимо называть и часть речи, которой выражен тот или иной член предложения. Этот навык ребята отрабатывают, изучая в 5 классе русский язык.
Характеристика предложения
Чтобы дать характеристику предложению, надо указать надо его описать
- по цели высказывания;
- по интонации;
- по количеству грамматических основ и так далее.
Ниже мы предлагаем план характеристики предложения.
По цели высказывания: повествовательное, вопросительное, побудительное.
По интонации: восклицательное или невосклицательное.
Восклицательными могут быть любые по цели высказывания предложения, а не только побудительные.
По количеству грамматических основ: простое или сложное.
Если предложение простое, движемся дальше по плану; если сложное, путь отсюда придется пройти несколько раз: столько, сколько частей в сложном.
По количеству главных членов в грамматической основе: односоставное или двусоставное.
Если предложение односоставное, надо определить его вид: назывное, определённо-личное, неопределённо-личное, безличное.
По наличию второстепенных членов: распространённое или нераспространённое.
Если предложение чем-то осложнено, то это также надо указать. Это план синтаксического разбора предложения; лучше его придерживаться.
Осложнённое предложение
Предложение может быть осложнено обращением, вводными и вставными конструкциями, однородными членами, обособленными членами, прямой речью. Если какой-то из этих видов осложнений присутствует, то надо указать, что предложение осложненное, и написать чем.
Если предложение сложное
Если необходимо сделать разбор сложного предложения, надо сначала указать, что оно сложное, и определить его тип: союзное или бессоюзное, а если союзное, то еще и сложносочиненное или сложноподчиненное. Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
В таблице приведены второстепенные члены и их вопросы.
Второстепенные члены предложения
Вопросы
Кого? чего? кому? чему? кем? чем? о ком? о чем?
Какой? чей? который по счету?
Где? когда? куда? откуда? почему? зачем? как? в какой степени?
Второстепенные члены могут быть выражены разными частями речи, например определение:
шерстяная юбка – прилагательное;
юбка из шерсти – существительное;
юбка отглаженная – причастие;
привычка побеждать – инфинитив…
Пример синтаксического разбора предложения
Подчеркнем грамматические основы. Их две: знал и ты переехала . Определим части речи: знал – сказуемое, выражено глаголом в личной форме и т.д.
Теперь подчеркиваем второстепенные члены:
Переехала откуда? из деревни – обстоятельство, выражено существительным; куда? в город – тоже обстоятельство, тоже выражено существительным. Маша – это обращение, оно не является членом предложения.
Теперь дадим характеристику. Предложение повествовательное, невосклицательное, сложное, союзное, сложноподчиненное.
Первая часть «не знал» неполная, нераспространенная.
Вторая часть двусоставная, распространенная. Осложнено обращением.
По окончании разбора надо составить схему сложного предложения.
Что мы узнали?
Синтаксический разбор призван помочь понять структуру предложения, поэтому необходимо указать все, что может быть с ней связано. Выполнять разбор лучше по плану, тогда больше шансов, что вы ничего не забудете. Необходимо не только подчеркнуть члены предложения, но и определить части речи, и дать характеристику предложению.
(PDF) Анализ зависимостей естественного русского языка с использованием подхода семантического картирования
Анита Баландина и др. / Процедуры Компьютерные науки 145 (2018) 77–83 79
2 Баландина и др. / Rulesia Computer Science 00 (2019) 000–000
Работая над семантическим поисковым движком, мы не можем игнорировать этот факт, поскольку использование простых ключевых слов
противоречит основной парадигме семантического поиска.
Таким образом, мы предлагаем использование онтологий предметной области для хранения поискового индекса и методы обработки естественного языка
для построения иерархического образа поискового запроса с сохранением семантических зависимостей для сопоставления
и поиска по графу онтологий [1 ].
Наша задача — разработать действующую модель поискового запроса, то есть изображение поискового запроса, для дальнейшего использования в системе семантического поиска
. Для этого необходимо решить ряд задач, связанных с зависимостями между словами на уровне фраз
, задачи определения контекстных синонимов исходных слов и словосочетаний и мер
их близости, определения контекст поиска и намерения пользователя при поиске в контексте области поиска.В этой статье
мы рассмотрим одну из проблем, перечисленных выше, связанную с зависимостями между словами, мы представим несколько современных методов ее решения
, а также наш собственный алгоритм, разработанный на основе классического анализа зависимостей.
2. Модели и методы
Предлагаемый нами подход является одним из способов изолировать зависимости внутри фразы путем построения дерева зависимостей
. Здесь у нас есть два варианта — выделение зависимостей на уровне слов и на уровне фраз.
Зависимости на уровне фраз хорошо подходят для понимания структуры всего предложения, в то время как
грамматики зависимостей в основном используются для понимания структуры конкретной фразы в предложении.
В синтаксическом дереве зависимостей корнем обычно является глагол или любое другое слово, обозначающее действие. На втором уровне
, как правило, есть объект действия, субъект, на нижних уровнях — характеристики объекта, субъект и
различных ограничений (время, количество, свойства и т. Д.).).
Все ссылки в дереве отмечены специальными POS-метками (частичками речи). Типы этих тегов могут помочь отбросить
несущественных терминов, например, тег CASE относится к предлогам, союзу и другим несущественным частям речи
, которые могут быть отброшены.
Таким образом, поисковый запрос можно легко сравнить с иерархической структурой с явно выделенными зависимостями
между значимыми терминами.
Мы предлагаем использовать синтаксический анализатор сдвиг-уменьшение для построения соответствующей модели поискового запроса.Для обучения модели
мы используем рекуррентную нейронную сеть LSTM с одним скрытым слоем. В качестве данных для обучения мы используем предварительно размеченный корпус русскоязычных текстов
. В качестве функции потерь мы используем кросс-энтропию:
с регуляризацией L2
.
Конечная цель — получить последовательность действий — сдвиг (левая дуга, правая дуга), сокращение, с помощью которой можно восстановить древовидную структуру
.
Классическая архитектура одиночного нейрона сети LSTM может быть описана набором следующих формул:
— забыть вектор активации ворот
— вектор активации входных ворот
— вектор активации выходного затвора
— вектор состояния ячейки
— выходной вектор блока LSTM
Мы можем представить выходную модель в виде следующего графика:
где
— набор слов входного поискового запроса
— это набор построенных связей между словами:
Полученная модель может быть использована для поиска по онтологии.Формально онтологию можно представить в виде следующего набора
:
где
— объекты , или сущности домена
— классы,
— характеристики классов
— операторы между классами
Имя автора / Процедуры информатики 00 (2019) 000–000 3
Первым шагом алгоритма поиска является сравнение корня дерева исходных текстов с типом подключения на онтологии
.Поскольку ссылки в онтологии имеют однозначные имена, тогда как в исходном запросе они могут быть самыми разными.
Чтобы сравнить корень с типом соединения, необходимо определить степень сходства между
двух слов — имени соединения на графе и корня дерева.
(1)
Для этого мы ищем в векторном пространстве ограничений, чтобы определить меру сходства.В качестве меры правдоподобия
мы используем косинусную меру. После того, как алгоритм нашел наиболее правдоподобную связь в онтологии, необходимо
найти два типа вершин, которые он связывает. Следовательно, алгоритм продолжает поиск похожих слов на графе
для вершин типов объектов субъект и действие. После того, как необходимое соединение найдено, в зависимости от типа соединения определяются условия
. Это могут быть временные условия, местонахождение или характеристика.
Второй этап процесса обработки запроса — это расширение синонимов или исправление запросов, основанное на использовании
семантического отображения. Исправление запросов (RoQ) — это процесс переформулирования начального запроса для повышения производительности поиска
в операциях поиска информации [6]. Исправление запросов включает в себя такие методы, как: i) поиск
синонимов слов, а также поиск синонимов; ii) поиск всех различных морфологических форм слов
путем выделения каждого слова в поисковом запросе; iii) Исправление орфографических ошибок и автоматический поиск исправленной формы
или предложение ее в результатах; iv) Повторное взвешивание терминов в исходном запросе [7].
Здесь мы должны ввести понятие семантической карты. В общем, семантическая карта может быть определена как топологическое
или метрическое пространство, топология и / или геометрия которого отражают семантические характеристики и отношения между набором
представлений (таких как слова или смыслы слов), встроенных в это пробел [4,8]. Наиболее известным подходом к семантической карте
является Antomap, разработанный А.Самсоновичем. Он не учитывает индивидуальные семантические характеристики
представлений, заданных априори.В качестве входных данных используются только отношения, но не семантические характеристики. В результате семантические
измерений карты, которые не предопределены для естественного возникновения, начиная с случайно сгенерированного начального распределения слов
в абстрактном пространстве без априори заданной семантики и следуя [8]. Основное отношение, которое используют
авторов в этом подходе, — это отношение «синонимия-антонимия» для репрезентаций.
Наш подход реализует расширение запроса на основе синонимов с помощью слабой семантической карты Antomap,
, которая использует Microsoft Russian Thesaurus Core как часть WordNet.
Antomap — это надстройка над MRTC, которая выделяет слова с их связями на карте. Формальное определение
Antomap состоит в учете того, что когнитивная семантическая карта представлена как динамическая система
, которая образована N точками в пространстве или векторами xi Î Â или, другими словами, представляет собой распределение слов в абстрактное
векторное пространство (без семантики, предварительно связанной с его элементами или измерениями), которое минимизирует следующую функцию энергии
[8,9]:
где x — 26-мерный вектор, представляющий -е слово (из N).Элементы симметричной матрицы отношений
равны +1 для пар синонимов, –1 для пар антонимов и нулю в противном случае. Энергетическая функция (1)
следует принципу экономии: это простейшее аналитическое выражение, которое создает уравновешенные силы желаемых знаков
между синонимами и антонимами, сохраняет симметрию семантических отношений и неограниченно возрастает на бесконечности
, сохраняя результирующее распределение локализовано вблизи начала координат.Более подробно этот подход
описан в [9] и [10].
Структура текущей карты позволяет вычислять семантическое сходство (SS) между словами. Вычисление
SS связано с «контекстным качеством» выбранных синонимов и помогает избавиться от синонимов, которые
не близки по контексту к исходному слову. Остальные синонимы расширяют запрос, формируя новые и похожие запросы
. Что касается необходимых компонентов для SS, то основные семантические размеры этой карты используются для вычисления
ее и определяются главными компонентами эмерджентного распределения слов на карте.Например, семантика
, связанная с первыми тремя ПК, может быть охарактеризована как «хорошая» против «плохой» (ПК1), «успокаивающая, легкая» против
| # кодировка: utf-8 | |
| # Обработчик грамматики ссылок для вывода на русский язык. | |
| # | |
| класс LinkParser :: Lexer | |
| # Это исключение возникает, когда грамматика ссылок недействительна и Lexer | |
| # не может понять вывод. | |
| # | |
| класс InvalidLinkGrammar | |
| attr_reader: ввод | |
| # @private | |
| def инициализировать вход | |
| super ‘Неверная грамматика ссылки’ | |
| @input = вход | |
| конец | |
| конец | |
| # Абстрактное синтаксическое дерево вывода парсера. | |
| # | |
| AST = Struct.new (: value) | |
| # Структура, представляющая ссылку в грамматике ссылок. | |
| # Включает определения типа и позиции, а также слово и его | |
| # морфосинтаксические дескрипторы. | |
| # | |
| Ссылка = Struct.новый (: тип,: подтип,: идентификатор,: слово,: msd) | |
| # Структура, представляющая слово в грамматике ссылок. Включает | |
| # морфосинтаксические дескрипторы. | |
| # | |
| Word = Struct.new (: word,: msd) | |
| attr_reader: input,: lexer | |
| частный: ввод,: lexer | |
| # Создайте новый экземпляр {Lexer} для обработки данного вывода синтаксического анализатора. | |
| # | |
| # @param input [String] вывод парсера. | |
| # | |
| def инициализировать вход | |
| @input = вход | |
| конец | |
| # Выполнить синтаксический анализ вывода синтаксического анализатора.Эта формулировка глупая, но | |
| # Я действительно не могу реализовать хороший Link Parser прямо сейчас. | |
| # | |
| # @return [AST] AST данного вывода парсера. | |
| # | |
| def parse | |
| @lexer = StringScanner.new (ввод) | |
| parse_value.значение | |
| гарантировать | |
| lexer.eos? или | |
| raise (‘Неожиданные данные: «% s»‘% lexer.string [lexer.pos ..- 1]) | |
| конец | |
| защищенный | |
| # Разобрать любую поддерживаемую синтаксическую конструкцию нашего парсера. | |
| # | |
| # @return [AST] AST данного вывода парсера. | |
| # | |
| def parse_value | |
| trim_space! | |
| parse_list или | |
| parse_string или | |
| parse_link или | |
| вызывает InvalidLinkGrammar, ввод | |
| гарантировать | |
| trim_space! | |
| конец | |
| # Парсер списка. | |
| # | |
| # @return [AST] AST данного вывода парсера. | |
| # | |
| def parse_list | |
| возвращает false, если lexer.scan / \ (\ s * / | |
| list = [] | |
| more_values = false | |
| , а содержимое = parse_value rescue nil | |
| список << содержание.значение | |
| more_values = lexer.scan / \ s + / | |
| конец | |
| поднимает ‘Missing value’, если more_values | |
| lexer.scan / \ s * \) \ s * / или поднять ‘Незакрытый список’ | |
| AST.новое (список) | |
| конец | |
| # Парсер строк. | |
| # | |
| # @return [AST] AST данного вывода парсера. | |
| # | |
| def parse_string | |
| возвращает false, если только lexer.\ «] + /) | |
| lexer.scan / «/ или поднять ‘Undetermined string’ | |
| AST.new (Word.new (* classify_word (строка))) | |
| конец | |
| # Парсер ссылок. | |
| # | |
| # @return [AST] AST данного вывода парсера. | |
| # | |
| def parse_link | |
| возвращает false, если token = lexer.scan (/ [\ wА-Яа-яЁё!: \ — \. \, \?] + /) | |
| комплексный_тип, идентификатор, строка = token.split (/: /) | |
| тип, подтип = сложный_тип.match (/ ([A-Z] +) (.*) /) [1..2] | |
| AST.new (Link.new (тип, подтип, id.to_i, * classify_word (строка))) | |
| конец | |
| # Пропускаем пробельные символы, потому что они нам не интересны. | |
| # | |
| def trim_space! | |
| lexer.сканирование / \ s + / | |
| сам | |
| конец | |
| # Метод классификации слов, идентифицирующий LEFT-WALL, RIGHT-WALL, | |
| # знаки препинания и обычные слова. | |
| # | |
| # @param word [String] слово для классификации. | |
| # | |
| # @return [Array <[String, Symbol], [String, NilClass]>] | |
| # данные классификации. | |
| # | |
| def classify_word (слово) | |
| регистр слова | |
| когда «ЛЕВАЯ СТЕНА», затем [: left_wall] | |
| когда «ПРАВАЯ СТЕНА», затем [: right_wall] | |
| когда ‘.\ [(. +) \] $ /) | |
| [unknown_word [1]] | |
| еще | |
| word.split (‘.’, 2) .map {| s | ! s.empty? ? s: nil} | |
| конец | |
| конец | |
| конец | |
| конец |
Грунтовка | Обработка русского естественного языка
Действительно ли существует одна языковая модель НЛП, которая управляет всеми ними?
Это стало стандартной практикой в сообществе обработки естественного языка (NLP).Выпустите хорошо оптимизированную модель корпуса английского языка, а затем процедурно примените ее к десяткам (или даже сотням) дополнительных иностранных языков. Эти модели вторичного языка обычно обучаются полностью без учителя. Они публикуются через несколько месяцев после первоначальной английской версии на ArXiv, и все это вызывает большой резонанс в технической прессе.
В августе 2016 года, например, Facebook выпустил fastText (1), быстрый инструмент для вычислений встраивания слов в вектор. В течение следующих девяти месяцев Facebook выпустил около 300 автоматически сгенерированных моделей fastText для всех языков, доступных в Википедии (2).Точно так же Google представила свой синтаксический синтаксический анализатор Parsy McParseface (3) в мае 2016 года, а позже в августе (4) выпустила обновленную версию синтаксического анализатора, обученного на 40 различных языках.
Вы можете задаться вопросом, является ли многоязычное НЛП решенной проблемой. Но можно ли наивно распространить модели, обученные на английском, на дополнительные неанглийские языки, или требуется некоторое понимание языка на уровне носителя языка до обновления модели? Ответ особенно актуален для нас здесь, в Primer, поскольку наши клиенты уделяют особое внимание пониманию и созданию текста в различных многоязычных корпусах.
Давайте начнем исследовать проблему с рассмотрения одного простого типа модели НЛП; Геометрическое вложение в стиле word2vec (5). Словесные векторы полезны для обучения различных типов текстовых классификаторов, особенно когда объем правильно размеченных обучающих данных отсутствует (6). Например, мы могли бы использовать каноническую векторную модель Google, обученную новостям (7), чтобы обучить классификатор для анализа настроений на английском языке. Затем мы расширим этот классификатор настроений, включив в него другие языки; например китайский, русский или арабский.Для этого потребуется дополнительный набор чужих векторов, скомпилированных либо автоматически, либо путем ручной настройки носителем этого языка. Например, если бы нас интересовали вложения русских слов, мы могли бы выбрать либо автоматизированные вычисления fastText от Facebook, либо результаты RusVectores для русского языка (8), которые были рассчитаны, протестированы и поддержаны двумя русскоязычными аспирантами. . Как бы сравнивать эти два набора векторов? Давай выясним.
RusVectores предлагает на выбор множество векторных моделей. Для нашего анализа давайте выберем их модель русских новостей (9), которая была обучена на корпусе из почти 5 миллиардов слов из российских новостных статей за более чем трехлетний период. Несмотря на огромный размер корпуса, размер самого векторного файла составляет всего 130 МБ, что составляет одну десятую размера канонической модели word2vec, обученной новостям Google (7). Частично несоответствие в размере связано с приведением всех русских слов к их лемматизированному эквиваленту с тегом части речи, добавленным подчеркиванием.Эта стратегия похожа на недавно опубликованную технику Sense2Vec (10), в которой разнообразное использование слова,
такие как, например, «утка», «утки», «утка» и «утка» заменяются одной комбинацией леммы / части речи, такой как «утка СУЩЕСТВИТЕЛЬНОЕ» или «утка ГЛАГОЛ».
Упрощение словаря с помощью лемматизации — это больше, чем просто способ уменьшить размер набора данных. Шаг лемматизации на самом деле критичен для работы встроенного вектора на русском языке (11).Чтобы понять, зачем нужна лемматизация, достаточно взглянуть на ту необычную роль, которую суффиксы играют в русской грамматике.
Русский, как и большинство языков, устраняет двусмысленность употребления определенных слов, изменяя их окончания в зависимости от грамматического контекста. Этот процесс известен как склонение, и в английском языке мы используем его для обозначения правильного времени глаголов.
Перегиб — это то, как мы узнаем, что покупка Наташей водки произошла в прошлом, а не в настоящем или будущем.Существительные в английском языке также могут изменяться, но только во множественном числе («одна водка» против «много водок»). Однако в русском языке склонение существительных значительно более распространено. Русские окончания слов помогают передать важную информацию, относящуюся к существительным, например, какие существительные являются подлежащими, а какие — объектами в предложениях. В английском языке такой грамматический контекст выражается только через порядок слов.
Значения этих двух предложений совершенно разные, хотя слова в английских предложениях идентичны.С другой стороны, русские предложения полагаются на словоизменение, а не на порядок слов, чтобы сообщить отношения существительных. Русское предложение A является прямым переводом английского предложения A, а простая замена суффиксов порождает бессмысленное предложение B. Отношение между Наташей (Наташа) и водкой (водка) сигнализируется ее суффиксом, а не ее положением в предложении.
Зависимость русского языка от суффиксов приводит к большему количеству возможных русских слов по сравнению с английским.Например, рассмотрим следующий набор фраз: «Я люблю водку», «Дай мне водку», «Утопи свои печали водкой», «Водки больше не осталось!», «Национальная водочная компания». В английском языке слово водка осталось неизменным. Но у их русских эквивалентов есть несколько вариантов слова водка:
.
Наше употребление водки меняется в зависимости от контекста, и вместо одной английской водки, которую нужно поглотить, у нас теперь есть четыре русские водки, с которыми мы должны иметь дело! Эта основанная на суффиксах избыточность добавляет шум в наши векторные вычисления.Если мы не лемматизируем, качество векторной графики пострадает.
Имея это в виду, давайте проведем следующий эксперимент. мы загрузим модель RusVectores с помощью библиотеки Python Gensim (12) (13) и выполним аналогичную функцию на для слова «водка СУЩЕСТВЕННОЕ» (водка СУЩЕСТВЕННОЕ), чтобы получить десять самых близких слов на русском языке векторное пространство, до водки.
Мы проводим эксперимент, используя следующий набор простых команд python:
от gensim.модели импортируют KeyedVectors
word_vectors = KeyedVectors.load_word2vec_format ('rus_vector_model.bin', двоичный = True)
например, сходство в word_vectors.most_similar (u'водка_NOUN ', topn = 10):
печатное слово Результаты (и их переводы) выглядят следующим образом:
Это разумный вывод. По крайней мере, большинство ближайших слов относятся к формам алкоголя. Тем не менее, в качестве проверки здравомыслия, давайте сравним вывод на русском языке с топ-10 ближайшими водочными словами в векторной модели Google, обученной новостям (7): Этот упорядоченный вывод выглядит следующим образом:
Пять выделенных алкогольных напитков также фигурируют в результатах по России.Таким образом, мы достигли согласованности между двумя векторными моделями. Тост за это!
А теперь давайте повторим эксперимент с векторами fastText для русского языка Facebook. Первое, что мы замечаем еще до загрузки модели, это то, что векторный файл Facebook (15) имеет размер 3,5 Гб, что более чем в два раза больше, чем у Google. Разница в размере файла становится известна, когда мы загружаем модель в Gensim. На загрузку векторных изображений Facebook на русском языке на современный ноутбук требуется более двух минут.Для сравнения, модель RusVectores занимает менее 20 секунд.
Почему модель Facebook такая невероятно большая? Ответ становится очевидным, когда мы задаем вопрос о десяти словах, ближайших к водке. В российской модели fastText они следующие:
Восемь из них представляют собой морфологическую вариацию водки, налитой в fastText. Кроме того, некоторые распространенные русскоязычные символы Unicode (например, стрелка », обозначающая конец русской цитаты) ошибочно добавлены к просканированным словам.Таким образом, избыточность русской лексики Facebook увеличивает размер набора векторов.
Чтобы провести честное сравнение с RusVectores, нам нужно будет использовать лемматизацию, чтобы отфильтровать повторяющиеся результаты. В первую десятку ближайших неповторяющихся слов в русской модели fastText входят:
Поразительно, но половина этих результатов соответствует безалкогольным напиткам. Какое разочарование!
Похоже, что универсальный подход Facebook к обучению моделей довольно посредственно работает с русским текстом.Но послушайте, это послужило хорошей отправной точкой. Некоторые автоматически обученные векторные модели слов генерируют результаты, граничащие с абсурдом. Возьмем, к примеру, Polyglot (16), который предлагает модели, обученные на Wiki-дампах на 40 разных языках, и дает следующие результаты для ближайших соседей водки:
Некоторые языковые модели не следует слепо обучать на входных данных, предварительно не приняв во внимание все нюансы языка. Так что используйте и тренируйте эти модели умеренно, вместо того, чтобы отказываться от 40 языков за один присест.Такое злоупотребление моделью вызовет головную боль у вас и всех ваших международных клиентов. Вместо этого, пожалуйста, не торопитесь, чтобы оценить прекрасные особенности каждого языка, как если бы вы ценили хорошее и пикантное вино.
Список литературы
- https://research.fb.com/fasttext/
- https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md
- https://research.googleblog.com/2016/05/announcing-syntaxnet-worlds-most.HTML
- https://research.googleblog.com/2016/08/meet-parseys-cousins-syntax-for-40.html
- https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
- http://nadbordrozd.github.io/blog/2016/05/20/text-classification-with-word2vec/
- http://mccormickml.com/2016/04/12/googles-pretrained-word2vec-model-in-python/
- http://rusvectores.org/en/models/
- http://rusvectores.org/static/models/news 0 300_2.bin.gz
- https: // взрыв.AI / блог / sense2vec-with-spacy
- http://www.dialog-21.ru/media/1119/arefyevnvetal.pdf
- https://radimrehurek.com/gensim/
- https://radimrehurek.com/gensim/models/keyedvectors.html
- https://radimrehurek.com/gensim/models/word2vec.html#gensim.models.word2vec.Word2Vec.similar на слово
- https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.ru.zip
- https://pypi.python.org/pypi/polyglot
Перевести «синтаксический анализ» с английского на русский с помощью Mate
Никогда больше не заходи на эту страницу
Загрузите приложение Mate для Mac, которое позволяет переводить прямо в Safari и других приложениях.Двойной щелчок — это все, что нужно. Присоединяйтесь к 800 000 человек, которые уже переводят быстрее.
попробовать бесплатно
Никогда больше не заходи на эту страницу
Получите приложение Mate для iPhone, которое позволяет переводить прямо в Safari, Mail, PDF-файлах и других приложениях. Никакого переключения приложений, никакого копирования и вставки. Присоединяйтесь к 800 000 человек, которые уже переводят быстрее.
Никогда больше не заходи на эту страницу
Установите расширение Mate для Chrome, чтобы переводить слова прямо на веб-страницах с помощью элегантного двойного щелчка.Или выделив предложение. Или даже субтитры Netflix. Присоединяйтесь к 800 000 человек, которые уже переводят быстрее.
Получить бесплатно
Интересно, что «синтаксический анализ» больше не означает. Воспользуйтесь веб-переводчиком Mate, чтобы взглянуть на наши непревзойденные переводы с английского на русский.
Мы прекрасно сделали Mate для macOS, iOS, Chrome, Firefox, Opera и Edge, так что вы можете переводить везде, где есть текст. Больше никаких приложений, переключения вкладок браузера или копирования.
Самые передовые возможности машинного перевода там, где это необходимо.Легко переводите с английского, русского и еще 101 языка на любой веб-сайт и в любое приложение.
Нужен английский ↔ русский перевод? Мате тебя прикрыл!
Вам нужно перевести электронное письмо, статью или веб-сайт с английского или русского языков для отпуска за границей или деловой поездки? Просто выделите этот текст — Mate переведет его в мгновение ока.
Перевести тексты самому
Прекратите тыкать в друзей и агентства всякий раз, когда вам нужен быстрый перевод с английского на русский.Оснастите себя приложениями и расширениями Mate, чтобы сделать это самостоятельно, быстрее и точнее. Наши приложения интегрируются в iPhone, iPad, Mac и Apple Watch на собственном уровне. Как будто это сделала Apple. Кроме того, вы можете дополнить свой любимый браузер нашими лучшими в своем классе расширениями для Safari, Chrome, Firefox, Opera и Edge.
Мы сделали все возможное, чтобы наша переводческая программа выделялась среди других машинных переводчиков. Mate предназначен для сохранения значения исходного текста и его основной идеи.Переводчики-люди нашли себе пару — это Mate.
Если вы устали копировать данные в Google, Яндекс или Bing, попробуйте Mate. Он не только показывает вам переводы там, где они вам нужны, с помощью элегантного двойного щелчка, но также обеспечивает лучшую конфиденциальность. Мы не отслеживаем, не продаем и не обрабатываем ваши данные. Ваши переводы принадлежат вам. Считайте нас бабел-рыбкой с завязанными глазами, которую превратили в кучу красивых приложений, которые помогут вам с переводами.
Электронные книги
IOS Press — пример гибридного анализа: правила, уточненные эмпирической и корпусной статистикой
Пример гибридного анализа: правила, уточненные эмпирической и корпусной статистикой
Авторы
Игорь Богуславский, Леонид Иомдин, Вадим Петроченков, Виктор Сизов, Леонид Цинман
Страницы
226–240
DOI
10.3233 / 978-1-61499-352-0-226
Ряд
Электронная книга
Abstract
В статье представлен анализатор зависимостей на основе правил с большим охватом для русского языка, ETAP-3, и результаты его оценки по нескольким критериям. Синтаксический анализатор принимает морфологическую структуру обрабатываемого предложения в качестве входных данных и строит дерево зависимостей для этого предложения, используя набор синтаксических правил. Каждое правило устанавливает одну маркированную и направленную связь между двумя словами предложения, которые образуют определенную синтаксическую конструкцию.Парсер использует около 65 различных синтаксических ссылок. Правила применяются алгоритмом, который сначала строит все возможные гипотетические ссылки, а затем использует различные фильтры для удаления лишних ссылок, так что оставшиеся образуют дерево зависимостей. На этом этапе фильтрации используются несколько типов данных, собранных эмпирическим путем или из синтаксически размеченного корпуса русского языка, SynTagRus, для улучшения производительности парсера. Синтаксический анализатор использует хорошо структурированный словарь русского языка объемом 130 000 человек, в статьях которого содержатся подробные описания синтаксических, семантических и других свойств слов.Значительная часть ссылок в выходных деревьях непроективна. Важной особенностью синтаксического анализатора является его способность производить несколько синтаксических разборов одного и того же предложения. В специальном режиме работы синтаксическому анализатору может быть дана инструкция производить больше результатов синтаксического анализа в дополнение к первому. Это можно сделать автоматически или в интерактивном режиме. В оценке SynTagRus рассматривается как золотой стандарт. Результаты оценки показывают цифры 0,911 для немаркированной оценки привязанности, 0,874 для оценки привязанности с меткой, 0.507 для немаркированной правильности структуры и 0,360 для маркированной правильности структуры.
российских моделей тегов и парсинга для CoreNLP
[ранее мы отправляли такое же письмо по адресу: [email protected]]
Привет!
Мы с коллегами реализовали российские модели тегов и синтаксического анализа зависимостей в Stanford CoreNLP и любезно просим совета.
К настоящему времени мы сделали следующее:
- Tagger:
1.1 Модель была обучена на выборке 200 тыс. Токенов из русских частей параллельных корпусов для статистического машинного перевода (http://statmt.org/).
Общий размер морфологически аннотированного подкорпуса составляет 10 млн токенов. Этот подкорпус был аннотирован с помощью анализатора SemSin. Каждому токену приписывалась следующая морфологическая информация: лемма + тег POS + морфологические признаки, омонимия была разрешена во время синтаксического анализа.
SemSin — медленный, но сравнительно точный анализатор зависимостей (качество тегов выше 0,96, лучший LAS немного выше 0.80, оба оцениваются в текстах новостей), который сочетает в себе поверхностный синтаксис и семантические метки ролей (но оба типа меток не соответствуют никакому стандарту). Описания SemSin доступны только на русском языке, некоторую информацию на английском языке можно найти в аннотации статьи: [http://www.dialog-21.ru/media/1394/kanevsky.pdf].
1.2 Набор тегов SemSin был сопоставлен с универсальными зависимостями (универсальные POS-теги и универсальные функции)
Результаты: Файл свойств русскоязычного теггера: ud-tagger.props, обученная модель тегов на русском языке (помечает входные предложения только тегами POS).
Вопросов по tagger:
Как лучше всего добавить в модель информацию о морфологических особенностях и лексемах? Как эта информация должна быть представлена в обучающей выборке? У нас есть большой аннотированный обучающий набор с POS, морфофункциями и леммами в формате UD v2, и мы хотим добавить всю информацию в модель тегов, потому что это важно для анализа морфологически богатого языка, такого как русский.
- Парсер
2.1 Следуя рекомендациям по обучению парсера зависимостей нейронной сети, мы написали RussianMorphoFeatureSpecification, RussianTreebankLanguagePack и несколько HeadFinder. Последний RussianHeadFinder был написан для поиска голов в деревьях после UD-представления, и различение главного и придаточного предложения, существительного и предложной фразы в русском языке стало проблемой. Итак, данная версия RussianHeadFinder — это всего лишь прототип, в котором описана структура только самых частых фраз.
2.2 Для обучения синтаксического анализатора мы использовали 1) выборку из 12000 предложений в формате conll-u в качестве обучающего набора и выборку из 6500 в качестве набора разработчика из SynTagRus treebank, 2) небольшой древовидный банк из 1000 предложений, проанализированных с помощью SemSin, автоматически преобразованных в UD и вручную проверил.
вложения Word были созданы с использованием корпуса http://statmt.org/.
2.3 Для обучения использовались следующие параметры:
-tlp edu.stanford.nlp.trees.international.russian.RussianTreebankLanguagePack -trainFile ud-SytTagRus2.conllu -embedFile model400.txt -embeddingSize 100 -model nndep.rus.model.txt.gz -maxIter 20000 -numPreComputed 10000 -batchSize 1000 -dropProb 0,25 -hiddenSize 200 -initRange 0,005 -trainingThreads 4 -evalPerIter_divag-dev dev.conllu -язык Русский
Результаты.
UAS = 73,83
LAS = 67,67
В настоящее время мы продолжаем эксперименты с большими размерами вложений, обучающей выборкой и количеством итераций.
вопросов.
Можно ли использовать морфологические функции в HeadFinder и в качестве функций для обучения парсеров? (В наборе тегов PennTreebank разные POS-теги используются для обозначения морфологических характеристик слов, принадлежащих одной и той же части речи, но в UD грамматические свойства перенесены в морфологические признаки, которые не используются парсером).Поэтому, если мы не ошибаемся, при обучении парсера данных в UD-представлении теряется много информации, которая полезна для построения шаблонов функций и встраиваний POS для морфологически насыщенного языка.
Можем ли мы получить от вас какие-либо рекомендации по разработке и улучшению моделей и внесению их в CoreNLP?
Ссылка на проект со всеми упомянутыми классами и моделями:
https://github.com/MANASLU8/CoreNLP
https://github.com/MANASLU8/CoreNLPRusModels
О нас: мы группа НЛП в Лаборатории информатики и семантических технологий факультета информатики и прикладной математики Университета ИТМО, Санкт-Петербург, Россия: http: // iam.ifmo.ru/ru/.
Основные направления исследований в области НЛП: лингвистические ресурсы для русского языка, популяция онтологий, грамматический вывод для разговорного русского языка, голосовые интерфейсы для IoT
.
Знакомство с пакетом «Сюжет»
Виньетка демонстрирует использование основных функций пакета «Сюжет». Пакет поставляется с четырьмя словарями настроений и предоставляет метод доступа к надежному, но дорогостоящему в вычислительном отношении инструменту извлечения настроений, разработанному в группе НЛП в Стэнфорде.Для использования этого более позднего метода необходимо, чтобы вы уже установили пакет coreNLP (см. Http://nlp.stanford.edu/software/corenlp.shtml).
Цель этой виньетки — познакомить с основными функциями пакета, чтобы вы могли быстро извлекать данные о графике и тональности из ваших собственных текстовых файлов. В этом документе будет использоваться короткий примерный отрывок, чтобы продемонстрировать функции и различные способы, которыми извлеченные данные могут быть возвращены и / или визуализированы.
get_sentences
После загрузки пакета (библиотека (сюжет) ) вы начинаете с разбора текста на вектор предложений.Для этого вы будете использовать функцию get_sentences () , которая реализует токенизатор предложений openNLP . Функция get_sentences () включает аргумент, который определяет, как обрабатывать цитируемый текст. По умолчанию кавычки удаляются перед синтаксическим анализом предложения. (Спасибо Энни Сваффорд, которая заметила, что синтаксический анализ предложений с помощью openNLP улучшается при удалении цитат.) В следующем примере очень простой текстовый отрывок, содержащий двенадцать предложений, загружается напрямую.(Вы можете так же легко загрузить текстовый файл со своего локального жесткого диска или с URL-адреса, используя функцию get_text_as_string () . get_text_as_string () описывается ниже.)
Результатом вызова get_sentences () в этом примере является новый вектор символов с именем s_v . Этот вектор содержит 12 элементов, по одному для каждого токенизированного предложения. Если вы хотите исследовать предложения, вы можете проверить результирующий вектор символов, как и любой другой вектор символов в R.Например,
## [1] "персонаж" ## chr [1:12] «Я начинаю этот рассказ с нейтрального высказывания». ... ## [1] «Я начинаю этот рассказ с нейтрального высказывания».
## [2] «По сути, это очень глупый тест».
## [3] «Вы тестируете пакет Сюжет, используя короткие, бессмысленные предложения».
## [4] «Я действительно очень счастлив сегодня».
## [5] "Я наконец закончил писать этот пакет."
## [6] «Завтра мне будет очень грустно». get_text_as_string
Функция get_text_as_string полезна, если вы хотите загрузить файл большего размера. Функция принимает один аргумент path , указывающий либо на файл на локальном диске, либо на URL-адрес. В этом примере мы загрузим версию проекта Gutenberg «Портрет художника в молодости Джеймса Джойса» по URL-адресу.
get_tokens
Функция get_tokens позволяет токенизировать слова вместо предложений.Вы можете ввести собственное регулярное выражение для определения границ слова. По умолчанию функция использует регулярное выражение «\ W» для определения границ слова. Обратите внимание, что «\ W» не удаляет подчеркивания.
get_sentiment ()
После того, как вы собрали предложения или токены слов из текста в вектор, вы отправите их в функцию get_sentiment , которая будет оценивать тональность каждого слова или предложения. Эта функция принимает два аргумента: вектор символов (предложений или слов) и «метод».Выбранный вами метод определяет, какой из четырех доступных методов извлечения тональности использовать. В следующем примере вызывается метод «сюжет» (по умолчанию).
Другие методы включают «bing», «afinn», «nrc» и «stanford». В документации к функции приведены библиографические ссылки на словари. Чтобы просмотреть документацию, просто введите в консоль ? Get_sentiment .
Если вы изучите содержимое нового объекта сюжет_вектор , вы увидите, что теперь он содержит набор из 5147 значений, соответствующих 5147 предложениям в Портрет художника в молодости .Ценности — это оценка моделью настроения в каждом предложении. Вот несколько первых значений, основанных на методе по умолчанию:
## [1] 2,50 0,60 0,00 -0,25 0,00 0,00 Обратите внимание, однако, что разные методы возвращают немного разные результаты. Частично это связано с тем, что каждый метод использует немного разную шкалу.
## [1] 1 0 -1 -1 0 0 ## [1] 3 0 0 1 0 0 ## [1] 1 1 -1 0 0 0 Поскольку в разных методах используются разные шкалы, может быть более полезно сравнить их с помощью функции R, встроенной в функцию sign .Функция sign преобразует все положительные числа в 1 , все отрицательные числа в -1 , а все нули остаются 0 .
## [, 1] [, 2] [, 3] [, 4] [, 5] [, 6]
## [1,] 1 1 0 -1 0 0
## [2,] 1 0 -1 -1 0 0
## [3,] 1 0 0 1 0 0
## [4,] 1 1 -1 0 0 0 После того, как значения настроения определены, мы могли бы, например, пожелать просуммировать значения, чтобы получить меру общей эмоциональной валентности в тексте:
## [1] -209.2 Результат -209,2 отрицательный, факт, который может указывать на то, что в целом текст выглядит как облом. В качестве альтернативы мы можем захотеть понять центральную тенденцию, среднюю эмоциональную валентность.
## [1] -0.033 Это среднее значение -0,03
немного ниже нуля. Эта и подобные сводные статистические данные могут помочь лучше понять, как распределяются эмоции в отрывке. Вы можете использовать функцию сводки, чтобы получить общее представление о распределении настроений в тексте.
## Мин. 1st Qu. Среднее значение 3-го кв. Максимум.
## -8.65000 -0.45000 0.00000 -0.03912 0.50000 6.60000 Хотя эти глобальные показатели настроений могут быть информативными, они очень мало говорят нам о том, как структурировано повествование и как эти положительные и отрицательные настроения активируются по всему тексту. Поэтому вам может быть полезно нанести значения на график, где ось x представляет собой течение времени от начала до конца текста, а ось y измеряет степень положительного и отрицательного настроения.Вот пример, использующий очень простой пример текста сверху:
С коротким отрывком прозы, таким как тот, который мы используем в этом примере, полученный сюжет не очень сложно интерпретировать. История здесь начинается на нейтральной территории, движется немного негативно, а затем переходит в период от нейтрального до слегка позитивного языка. Однако в седьмом предложении (видимом между шестым и восьмым галочками на оси x) настроение принимает довольно негативный поворот вниз и достигает нижней точки отрывка.Но после двух в основном отрицательных предложений (восемь и девять) настроение восстанавливается с очень положительными десятым, одиннадцатым и двенадцатым предложениями, «счастливый конец», если хотите.
То, что здесь наблюдается, полезно для демонстрационных целей, но вряд ли типично для 300-страничного романа. На протяжении трех-четырехсот страниц можно встретить довольно много эмоционального шума. Вот, например, сюжет из «Портрет художника в молодости » Джойса .
Хотя эти необработанные данные могут быть полезны для определенных приложений, для визуализации обычно предпочтительнее удалить шум и показать простую форму траектории.Один из способов сделать это — применить линию тренда. На следующем графике линия тренда скользящего среднего применяется к простому тексту примера, содержащему двенадцать предложений.
Хотя скользящее среднее может быть полезно, мы должны помнить, что данные на краях теряются. Тем не менее такое сглаживание может быть полезно для понимания эмоциональной траектории отдельного текста.
get_percentage_values
Когда дело доходит до сравнения формы одной траектории с другой, может быть полезна функция get_percentage_values .Функция get_percentage_values делит текст на равное количество «фрагментов», а затем вычисляет среднюю валентность тональности для каждого. В приведенном ниже примере настроения из Portrait разбиты на 10 частей и затем нанесены на график.
Используя необязательный аргумент bins , вы можете контролировать, сколько предложений включается в каждый процентный блок:
К сожалению, когда ряд значений предложения объединяется в более крупный кусок с использованием процентной меры, крайности эмоциональной валентности имеют тенденцию размываться.Это особенно верно, когда сегменты текста, которые возвращаются на основе процентного разбиения, особенно велики. При усреднении отрывок из 1000 предложений с гораздо большей вероятностью будет содержать широкий диапазон значений, чем отрывок из 100 предложений. Действительно, средства более длинных отрывков стремятся сходиться к нулю. Но это не единственная проблема с нормализацией на основе процентов. Нормализация, основанная на процентах, не только притупляет эмоциональную дисперсию, но и делает сравнение книги с книгой несколько бесполезным. Сравнение первой десятой части очень длинной книги, такой как Моби Дик Мелвилла, с первой десятой короткой новеллы, такой как Картина Дориана Грея Оскара Уайльда, просто не так уж и плодотворно, потому что в одном случае первая десятая часть состоит из 1000 предложений, а в другом — всего 100.
Пакет Сюжет предоставляет две альтернативы процентному сравнению с использованием преобразования Фурье или дискретного косинусного преобразования в сочетании с фильтром нижних частот.
get_transformed_values
ПРИМЕЧАНИЕ: get_transformed_values поддерживается для устаревших целей. Пользователям следует рассмотреть возможность использования вместо этого get_dct_transform () .
Сглаживание и нормализация формы с использованием преобразования на основе Фурье и фильтрации нижних частот достигается с помощью функции get_transformed_values , как показано ниже.Различные аргументы описаны в справочной документации.
## Предупреждение в get_transformed_values (syuzhet_vector, low_pass_size = 3,
## x_reverse_len = 100,: Эта функция поддерживается для устаревших целей. Рассмотреть возможность
## используя вместо этого get_dct_transform (). get_dct_transform
Функция get_dct_transform аналогична функции get_transformed_values , но применяет более простое дискретное косинусное преобразование (DCT) вместо быстрого преобразования Фурье.Его главное преимущество заключается в лучшем представлении значений границ в сглаженной версии вектора тональности.
## simple_plot Функция simple_plot принимает вектор тональности и применяет три метода сглаживания. К сглаживанию относятся скользящее среднее, лессовое и дискретное косинусное преобразование. Эта функция создает два графика с накоплением. Первый показывает все три метода сглаживания на одном графике. Второй график показывает только сглаженную линию DCT, но на нормализованной оси времени.Форма линии DCT как на верхнем, так и на нижнем графиках идентична. В следующем коде Мадам Бовари Флобера используется вместо Портрет Джойса.
get_nrc_sentiment
get_nrc_sentiment реализует лексику NRC Emotion Саифа Мохаммеда. По словам Мохаммеда, «лексика эмоций NRC — это список слов и их ассоциаций с восемью эмоциями (гнев, страх, ожидание, доверие, удивление, печаль, радость и отвращение) и двумя чувствами (отрицательным и положительным)» (см. Http : // сайфмохаммад.ru / WebPages / NRC-Emotion-Lexicon.htm). Функция get_nrc_sentiment возвращает кадр данных, в котором каждая строка представляет предложение из исходного файла. Столбцы включают по одному для каждого типа эмоции, а также положительную или отрицательную валентность настроения. В приведенном ниже примере функция вызывается с использованием простого отрывка из двенадцати предложений, хранящегося в объекте s_v сверху.
Как только данные были возвращены, к ним можно получить доступ, как и к любому другому фрейму данных.К данным в столбцах (гнев, ожидание, отвращение, страх, радость, печаль, удивление, доверие, негатив, позитив) можно получить доступ по отдельности или в наборах. Здесь мы идентифицируем элементы, вызывающие наибольший гнев, и используем его в качестве ссылки для поиска соответствующего предложения из отрывка.
## [1] «Я могу рассердиться и решить сделать что-нибудь ужасное». Точно так же легко идентифицировать элементы, которые в лексиконе NRC определены как радостные:
## [1] «По сути, это очень глупый тест."
## [2] «Я действительно очень счастлив сегодня».
## [3] «Я наконец закончил писать этот пакет».
## [4] «Честно говоря, такое использование преобразования Фурье действительно довольно элегантно».
## [5] «Можно даже сказать, красиво!» Просмотреть все эмоции и их значения просто:
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 2 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 2 | 1 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
Или вы можете исследовать только положительную и отрицательную валентность:
| 0 | 1 |
| 1 | 0 |
| 1 | 0 |
| 0 | 1 |
| 0 | 1 |
| 0 | 0 |
| 0 | 0 |
| 2 | 0 |
| 0 | 0 |
| 0 | 0 |
| 0 | 1 |
| 0 | 1 |
Последние два столбца используются методом nrc в описанной выше функции get_sentiment .Чтобы вычислить одно значение положительной или отрицательной валентности для каждого предложения, значения в отрицательном столбце преобразуются в отрицательные числа, а затем добавляются к значениям в положительном столбце, как это.
## [1] 1-1-1 1 1 0 0-2 0 0 1 1 Наконец, процент каждой эмоции в тексте можно представить в виде гистограммы:
rescale_x_2
Функция rescale_x_2 удобна для повторного масштабирования значений по нормализованным осям x и y.Это полезно для сравнения двух дуг настроений. Предположим, что мы хотим сравнить формы, полученные путем применения скользящего среднего к двум разным дугам настроения. Сначала мы вычислим исходные значения тональности в Портрет художника и Мадам Бовари .
Теперь мы рассчитаем скользящее среднее для каждого вектора необработанных значений. Мы будем использовать размер окна, равный 1/10 общей длины вектора.
Результирующие векторы имеют разную длину: 4814 и 6248, поэтому мы можем использовать rescale_x_2 , чтобы расположить их в одном масштабе.
Затем мы можем построить две линии на одном графике, даже если они имеют разную длину:
Хотя теперь нам удалось масштабировать и ось x, и ось y, чтобы отобразить их на одном графике, у нас все еще нет векторов одинаковой длины, что означает, что их нелегко сравнить математически. Ось времени для Портрет художника составляет 4814 единиц, а временная ось для Мадам Бовари составляет 6248 единиц.
Возможна выборка из этих векторов.В коде, который следует здесь, мы делим каждый вектор на 100 выборок, а затем строим эти точки выборки. В результате каждая линия строится из 100 точек на оси абсцисс.
poa_sample <- seq (1, длина (poa_list $ x), by = round (length (poa_list $ x) / 100))
bov_sample <- seq (1, длина (bov_list $ x), by = round (length (bov_list $ x) / 100))
сюжет (poa_list $ x [poa_sample],
poa_list $ z [poa_sample],
type = "l",
col = "синий",
xlab = "Время повествования (выборка)",
ylab = "Эмоциональная валентность"
)
строки (bov_list $ x [bov_sample], bov_list $ z [bov_sample], col = "red") При равном количестве значений в каждом векторе мы можем применить меру расстояния или сходства, например евклидово расстояние корреляции Пирсона.
## 1
## 2 7.223739 ## [, 1] [, 2]
## [1,] 1.0000000 -0.2100283
## [2,] -0,2100283 1,0000000 Некоторые пользователи могут найти этот вид нормализации и выборки предпочтительнее альтернативного метода, предоставляемого get_dct_transform , который предполагает, что основной поток траектории тональности находится в низкочастотных компонентах преобразованного сигнала. В этом примере мы сделали выборку из набора значений, которые были сглажены с использованием скользящего среднего (который является типом фильтра нижних частот).Однажды можно было легко применить ту же процедуру к значениям, которые были сглажены другим методом, например сглаживателем лесса, который реализован в функции simple_plot .
Вот как можно использовать аналогичный подход для выборки из сглаженной лёссовой линии.
poa_x <- 1: длина (poa_values)
poa_y <- poa_values
raw_poa <- лёсс (poa_y ~ poa_x, span = .5)
poa_line <- масштабировать (прогнозировать (raw_poa))
bov_x <- 1: длина (bovary_values)
bov_y <- bovary_values
raw_bov <- лёсс (bov_y ~ bov_x, span =.5)
bov_line <- масштабировать (прогнозировать (raw_bov))
poa_sample <- seq (1, длина (poa_line), by = round (length (poa_line) / 100))
bov_sample <- seq (1, длина (bov_line), by = round (length (bov_line) / 100))
сюжет (poa_line [poa_sample],
type = "l",
col = "синий",
xlab = "Время повествования (выборка)",
ylab = "Эмоциональная валентность"
)
линии (bov_line [bov_sample], col = "red") Многоязычный словарь тональности
В версии 1.0.4 была добавлена поддержка определения настроений на нескольких языках с использованием расширенного лексикона NRC от Саифа Мохаммеда.Лексика включает значения тональности для 13901 слова на каждом из следующих языков:
Арабский, баскский, бенгальский, каталонский, упрощенный китайский, традиционный китайский, датский, голландский, английский, эсперанто, финский, французский, немецкий, греческий, гуджарати, иврит, хинди, ирландский, итальянский, японский, латинский, маратхи, персидский, португальский, румынский , Русский, сомалийский, испанский, суданский, суахили, шведский, тамильский, телугу, тайский, турецкий, украинский, урду, вьетнамский, валлийский, идиш, зулусский.
На момент выхода этого выпуска Сюжет будет работать только с языками, в которых используются латинские символы.Фактически это означает, что «арабский», «бенгальский», «китайский упрощенный», «китайский традиционный», «греческий», «гуджарати», «иврит», «хинди», «японский», «маратхи», «персидский», «русский» »,« Тамильский »,« Телугу »,« Тайский »,« Украинский »,« Урду »,« Идиш »не поддерживаются, хотя эти языки являются частью расширенного словаря NRC.
Также важно отметить, что токенизатор предложений внутри функции get_sentences () по своей сути смещен в сторону английского синтаксиса. Следует позаботиться о том, чтобы используемый язык был правильно проанализирован функцией get_sentences ().Может быть целесообразно отказаться от токенизации предложений в пользу токенизации на основе слов с помощью функции get_tokens (). Ниже приведен пример того, как вызвать испанский лексикон для обнаружения сантиментов в Дон Кихот .
## [1] 0-4 0 3 2 2-1 2 1 6 Индивидуальные лексики настроений
В версии 1.0.4 к функции get_sentiments () была добавлена функциональность, позволяющая пользователям загружать свои собственные лексиконы тональности. Для работы пользователям необходимо создать свой собственный лексикон в виде фрейма данных, по крайней мере, с двумя столбцами с именами «слово» и «значение».Вот упрощенный пример:
## [1] 2 -2 Распараллеливание
Сбор результатов тональности больших объемов данных может занять много времени. Можно вызвать get_sentiment и предоставить информацию о кластере из parallel :: makeCluster () , чтобы быстрее достичь результатов в системах с несколькими ядрами. Например, на Madame Bovary , как указано выше:
## Загрузка необходимого пакета: параллельно Смешанные сообщения
Иногда нам может потребоваться выявить области текста, в которых присутствует эмоциональная двусмысленность.Функция mixed_messages () предлагает один из способов идентификации предложений, которые кажутся противоречащими друг другу. Эта функция вычисляет «эмоциональную энтропию» строки на основе количества конфликтующих валентностей, обнаруженных в словах предложения. Эмоциональную энтропию можно рассматривать как меру непредсказуемости и неожиданности, основанную на последовательности или несогласованности эмоционального языка в данной строке. Можно сказать, что строка с противоречивым эмоциональным языком выражает или содержит «смешанное сообщение».Вот пример, который пытается идентифицировать и строить участки в Madame Bovary , которые имеют самую высокую и самую низкую концентрацию смешанных сообщений.
Из этого рисунка видно, что первая часть романа имеет самую высокую концентрацию эмоционально неоднозначного или противоречивого языка. Мы также можем построить метрическую энтропию, которая нормализует значения энтропии в зависимости от длины предложения.
Этот график рассказывает немного иную историю.Он по-прежнему показывает, что начало романа имеет высокую эмоциональную энтропию, но также идентифицирует вторую волну примерно в 1800-м предложении.
Если мы хотим посмотреть на конкретные предложения, их достаточно легко отсортировать с помощью dplyr . Сначала мы рассмотрим несколько предложений, основанных на наивысшей энтропии.
##
## Прикрепляемый пакет: 'dplyr' ## Следующие объекты замаскированы из package: stats:
##
## фильтр, лаг ## Следующие объекты замаскированы из package: base:
##
## Intercct, setdiff, setequal, union ## энтропия
## 7 1
## 8 1
## 9 1
## 10 1
## sample_sents
## 7 Когда-то живая, экспансивная и ласковая, с возрастом она стала (по моде вина, которое на воздухе превращается в уксус) вспыльчивой, ворчливой, раздражительной.## 8 Когда у нее родился ребенок, его пришлось отдать няньке.
## 9 Но, миролюбивый по натуре, парень плохо отвечал на его представления.
## 10 Его мать всегда держала его рядом с собой; она вырезала ему картон, рассказывала сказки, развлекала его бесконечными монологами, полными меланхолической веселости и очаровательной чепухи.